 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus-N-Fix: Region-Aware Fine-Tuning for Text-to-Image Generation
Jan 11, 2025

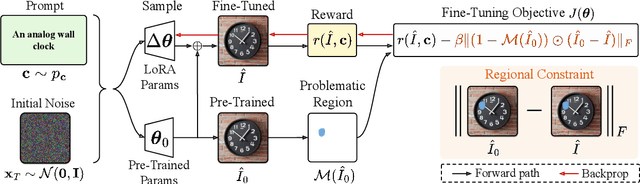
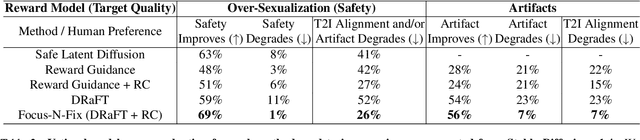
Text-to-image (T2I) generation has made significant advances in recent years, but challenges still remain in the generation of perceptual artifacts, misalignment with complex prompts, and safety. The prevailing approach to address these issues involves collecting human feedback on generated images, training reward models to estimate human feedback, and then fine-tuning T2I models based on the reward models to align them with human preferences. However, while existing reward fine-tuning methods can produce images with higher rewards, they may change model behavior in unexpected ways. For example, fine-tuning for one quality aspect (e.g., safety) may degrade other aspects (e.g., prompt alignment), or may lead to reward hacking (e.g., finding a way to increase rewards without having the intended effect). In this paper, we propose Focus-N-Fix, a region-aware fine-tuning method that trains models to correct only previously problematic image regions. The resulting fine-tuned model generates images with the same high-level structure as the original model but shows significant improvements in regions where the original model was deficient in safety (over-sexualization and violence), plausibility, or other criteria. Our experiments demonstrate that Focus-N-Fix improves these localized quality aspects with little or no degradation to others and typically imperceptible changes in the rest of the image. Disclaimer: This paper contains images that may be overly sexual, violent, offensive, or harmful.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Harm Amplification in Text-to-Image Models
Feb 01, 2024



Text-to-image (T2I) models have emerged as a significant advancement in generative AI; however, there exist safety concerns regarding their potential to produce harmful image outputs even when users input seemingly safe prompts. This phenomenon, where T2I models generate harmful representations that were not explicit in the input, poses a potentially greater risk than adversarial prompts, leaving users unintentionally exposed to harms. Our paper addresses this issue by first introducing a formal definition for this phenomenon, termed harm amplification. We further contribute to the field by developing methodologies to quantify harm amplification in which we consider the harm of the model output in the context of user input. We then empirically examine how to apply these different methodologies to simulate real-world deployment scenarios including a quantification of disparate impacts across genders resulting from harm amplification. Together, our work aims to offer researchers tools to comprehensively address safety challenges in T2I systems and contribute to the responsible deployment of generative AI models.
Safety and Fairness for Content Moderation in Generative Models
Jun 09, 2023



With significant advances in generative AI, new technologies are rapidly being deployed with generative components. Generative models are typically trained on large datasets, resulting in model behaviors that can mimic the worst of the content in the training data. Responsible deployment of generative technologies requires content moderation strategies, such as safety input and output filters. Here, we provide a theoretical framework for conceptualizing responsible content moderation of text-to-image generative technologies, including a demonstration of how to empirically measure the constructs we enumerate. We define and distinguish the concepts of safety, fairness, and metric equity, and enumerate example harms that can come in each domain. We then provide a demonstration of how the defined harms can be quantified. We conclude with a summary of how the style of harms quantification we demonstrate enables data-driven content moderation decisions.
Visualizing Topographic Independent Component Analysis with Movies
Jan 24, 2019
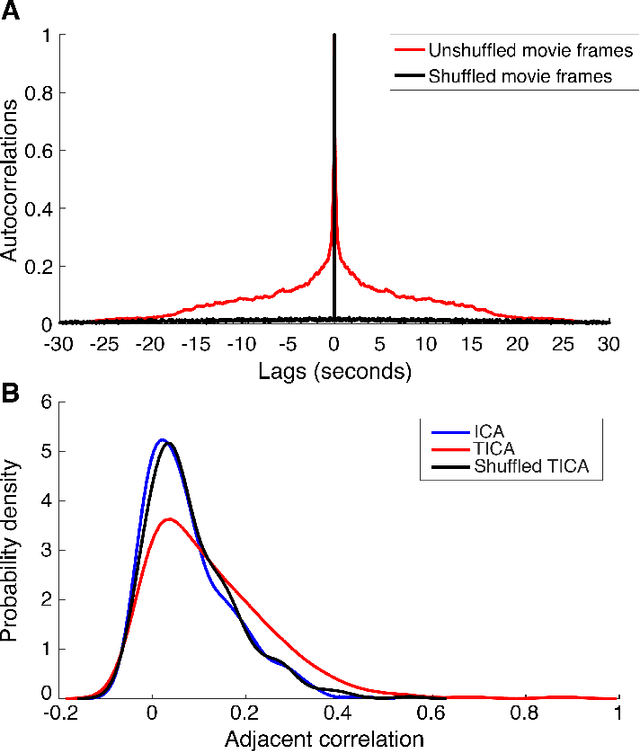
Independent component analysis (ICA) has often been used as a tool to model natural image statistics by separating multivariate signals in the image into components that are assumed to be independent. However, these estimated components oftentimes have higher order dependencies, such as co-activation of components, that are not accounted for in the model. Topographic independent component analysis(TICA), a modification of ICA, takes into account higher order dependencies and orders components topographically as a function of dependence. Here, we aim to visualize the time course of TICA basis activations to movie stimuli. We find that the activity of TICA bases are often clustered and move continuously, potentially resembling activity of topographically organized cells in the visual cortex.