 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved and Oracle-Efficient Online $\ell_1$-Multicalibration
May 23, 2025We study \emph{online multicalibration}, a framework for ensuring calibrated predictions across multiple groups in adversarial settings, across $T$ rounds. Although online calibration is typically studied in the $\ell_1$ norm, prior approaches to online multicalibration have taken the indirect approach of obtaining rates in other norms (such as $\ell_2$ and $\ell_{\infty}$) and then transferred these guarantees to $\ell_1$ at additional loss. In contrast, we propose a direct method that achieves improved and oracle-efficient rates of $\widetilde{\mathcal{O}}(T^{-1/3})$ and $\widetilde{\mathcal{O}}(T^{-1/4})$ respectively, for online $\ell_1$-multicalibration. Our key insight is a novel reduction of online \(\ell_1\)-multicalibration to an online learning problem with product-based rewards, which we refer to as \emph{online linear-product optimization} ($\mathtt{OLPO}$). To obtain the improved rate of $\widetilde{\mathcal{O}}(T^{-1/3})$, we introduce a linearization of $\mathtt{OLPO}$ and design a no-regret algorithm for this linearized problem. Although this method guarantees the desired sublinear rate (nearly matching the best rate for online calibration), it becomes computationally expensive when the group family \(\mathcal{H}\) is large or infinite, since it enumerates all possible groups. To address scalability, we propose a second approach to $\mathtt{OLPO}$ that makes only a polynomial number of calls to an offline optimization (\emph{multicalibration evaluation}) oracle, resulting in \emph{oracle-efficient} online \(\ell_1\)-multicalibration with a rate of $\widetilde{\mathcal{O}}(T^{-1/4})$. Our framework also extends to certain infinite families of groups (e.g., all linear functions on the context space) by exploiting a $1$-Lipschitz property of the \(\ell_1\)-multicalibration error with respect to \(\mathcal{H}\).
Single-Sample and Robust Online Resource Allocation
May 05, 2025Online Resource Allocation problem is a central problem in many areas of Computer Science, Operations Research, and Economics. In this problem, we sequentially receive $n$ stochastic requests for $m$ kinds of shared resources, where each request can be satisfied in multiple ways, consuming different amounts of resources and generating different values. The goal is to achieve a $(1-\epsilon)$-approximation to the hindsight optimum, where $\epsilon>0$ is a small constant, assuming each resource has a large budget. In this paper, we investigate the learnability and robustness of online resource allocation. Our primary contribution is a novel Exponential Pricing algorithm with the following properties: 1. It requires only a \emph{single sample} from each of the $n$ request distributions to achieve a $(1-\epsilon)$-approximation for online resource allocation with large budgets. Such an algorithm was previously unknown, even with access to polynomially many samples, as prior work either assumed full distributional knowledge or was limited to i.i.d.\,or random-order arrivals. 2. It is robust to corruptions in the outliers model and the value augmentation model. Specifically, it maintains its $(1 - \epsilon)$-approximation guarantee under both these robustness models, resolving the open question posed in Argue, Gupta, Molinaro, and Singla (SODA'22). 3. It operates as a simple item-pricing algorithm that ensures incentive compatibility. The intuition behind our Exponential Pricing algorithm is that the price of a resource should adjust exponentially as it is overused or underused. It differs from conventional approaches that use an online learning algorithm for item pricing. This departure guarantees that the algorithm will never run out of any resource, but loses the usual no-regret properties of online learning algorithms, necessitating a new analytical approach.
Focus-N-Fix: Region-Aware Fine-Tuning for Text-to-Image Generation
Jan 11, 2025

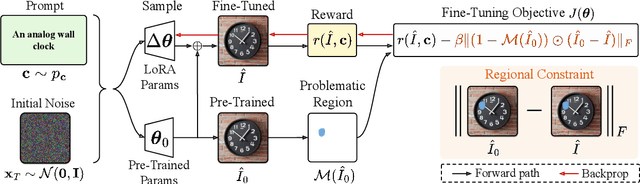
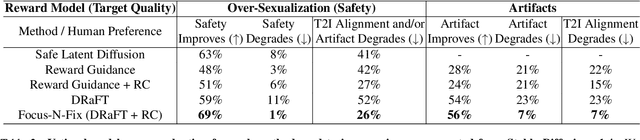
Text-to-image (T2I) generation has made significant advances in recent years, but challenges still remain in the generation of perceptual artifacts, misalignment with complex prompts, and safety. The prevailing approach to address these issues involves collecting human feedback on generated images, training reward models to estimate human feedback, and then fine-tuning T2I models based on the reward models to align them with human preferences. However, while existing reward fine-tuning methods can produce images with higher rewards, they may change model behavior in unexpected ways. For example, fine-tuning for one quality aspect (e.g., safety) may degrade other aspects (e.g., prompt alignment), or may lead to reward hacking (e.g., finding a way to increase rewards without having the intended effect). In this paper, we propose Focus-N-Fix, a region-aware fine-tuning method that trains models to correct only previously problematic image regions. The resulting fine-tuned model generates images with the same high-level structure as the original model but shows significant improvements in regions where the original model was deficient in safety (over-sexualization and violence), plausibility, or other criteria. Our experiments demonstrate that Focus-N-Fix improves these localized quality aspects with little or no degradation to others and typically imperceptible changes in the rest of the image. Disclaimer: This paper contains images that may be overly sexual, violent, offensive, or harmful.
Online Combinatorial Allocations and Auctions with Few Samples
Sep 17, 2024In online combinatorial allocations/auctions, n bidders sequentially arrive, each with a combinatorial valuation (such as submodular/XOS) over subsets of m indivisible items. The aim is to immediately allocate a subset of the remaining items to maximize the total welfare, defined as the sum of bidder valuations. A long line of work has studied this problem when the bidder valuations come from known independent distributions. In particular, for submodular/XOS valuations, we know 2-competitive algorithms/mechanisms that set a fixed price for each item and the arriving bidders take their favorite subset of the remaining items given these prices. However, these algorithms traditionally presume the availability of the underlying distributions as part of the input to the algorithm. Contrary to this assumption, practical scenarios often require the learning of distributions, a task complicated by limited sample availability. This paper investigates the feasibility of achieving O(1)-competitive algorithms under the realistic constraint of having access to only a limited number of samples from the underlying bidder distributions. Our first main contribution shows that a mere single sample from each bidder distribution is sufficient to yield an O(1)-competitive algorithm for submodular/XOS valuations. This result leverages a novel extension of the secretary-style analysis, employing the sample to have the algorithm compete against itself. Although online, this first approach does not provide an online truthful mechanism. Our second main contribution shows that a polynomial number of samples suffices to yield a $(2+\epsilon)$-competitive online truthful mechanism for submodular/XOS valuations and any constant $\epsilon>0$. This result is based on a generalization of the median-based algorithm for the single-item prophet inequality problem to combinatorial settings with multiple items.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Beyond Thumbs Up/Down: Untangling Challenges of Fine-Grained Feedback for Text-to-Image Generation
Jun 24, 2024Human feedback plays a critical role in learning and refining reward models for text-to-image generation, but the optimal form the feedback should take for learning an accurate reward function has not been conclusively established. This paper investigates the effectiveness of fine-grained feedback which captures nuanced distinctions in image quality and prompt-alignment, compared to traditional coarse-grained feedback (for example, thumbs up/down or ranking between a set of options). While fine-grained feedback holds promise, particularly for systems catering to diverse societal preferences, we show that demonstrating its superiority to coarse-grained feedback is not automatic. Through experiments on real and synthetic preference data, we surface the complexities of building effective models due to the interplay of model choice, feedback type, and the alignment between human judgment and computational interpretation. We identify key challenges in eliciting and utilizing fine-grained feedback, prompting a reassessment of its assumed benefits and practicality. Our findings -- e.g., that fine-grained feedback can lead to worse models for a fixed budget, in some settings; however, in controlled settings with known attributes, fine grained rewards can indeed be more helpful -- call for careful consideration of feedback attributes and potentially beckon novel modeling approaches to appropriately unlock the potential value of fine-grained feedback in-the-wild.
e-COP : Episodic Constrained Optimization of Policies
Jun 13, 2024In this paper, we present the $\texttt{e-COP}$ algorithm, the first policy optimization algorithm for constrained Reinforcement Learning (RL) in episodic (finite horizon) settings. Such formulations are applicable when there are separate sets of optimization criteria and constraints on a system's behavior. We approach this problem by first establishing a policy difference lemma for the episodic setting, which provides the theoretical foundation for the algorithm. Then, we propose to combine a set of established and novel solution ideas to yield the $\texttt{e-COP}$ algorithm that is easy to implement and numerically stable, and provide a theoretical guarantee on optimality under certain scaling assumptions. Through extensive empirical analysis using benchmarks in the Safety Gym suite, we show that our algorithm has similar or better performance than SoTA (non-episodic) algorithms adapted for the episodic setting. The scalability of the algorithm opens the door to its application in safety-constrained Reinforcement Learning from Human Feedback for Large Language or Diffusion Models.
Robust Disaster Assessment from Aerial Imagery Using Text-to-Image Synthetic Data
May 22, 2024We present a simple and efficient method to leverage emerging text-to-image generative models in creating large-scale synthetic supervision for the task of damage assessment from aerial images. While significant recent advances have resulted in improved techniques for damage assessment using aerial or satellite imagery, they still suffer from poor robustness to domains where manual labeled data is unavailable, directly impacting post-disaster humanitarian assistance in such under-resourced geographies. Our contribution towards improving domain robustness in this scenario is two-fold. Firstly, we leverage the text-guided mask-based image editing capabilities of generative models and build an efficient and easily scalable pipeline to generate thousands of post-disaster images from low-resource domains. Secondly, we propose a simple two-stage training approach to train robust models while using manual supervision from different source domains along with the generated synthetic target domain data. We validate the strength of our proposed framework under cross-geography domain transfer setting from xBD and SKAI images in both single-source and multi-source settings, achieving significant improvements over a source-only baseline in each case.
Bandit Sequential Posted Pricing via Half-Concavity
Dec 20, 2023


Sequential posted pricing auctions are popular because of their simplicity in practice and their tractability in theory. A usual assumption in their study is that the Bayesian prior distributions of the buyers are known to the seller, while in reality these priors can only be accessed from historical data. To overcome this assumption, we study sequential posted pricing in the bandit learning model, where the seller interacts with $n$ buyers over $T$ rounds: In each round the seller posts $n$ prices for the $n$ buyers and the first buyer with a valuation higher than the price takes the item. The only feedback that the seller receives in each round is the revenue. Our main results obtain nearly-optimal regret bounds for single-item sequential posted pricing in the bandit learning model. In particular, we achieve an $\tilde{O}(\mathsf{poly}(n)\sqrt{T})$ regret for buyers with (Myerson's) regular distributions and an $\tilde{O}(\mathsf{poly}(n)T^{{2}/{3}})$ regret for buyers with general distributions, both of which are tight in the number of rounds $T$. Our result for regular distributions was previously not known even for the single-buyer setting and relies on a new half-concavity property of the revenue function in the value space. For $n$ sequential buyers, our technique is to run a generalized single-buyer algorithm for all the buyers and to carefully bound the regret from the sub-optimal pricing of the suffix buyers.
Spuriosity Rankings: Sorting Data for Spurious Correlation Robustness
Dec 05, 2022



We present a framework for ranking images within their class based on the strength of spurious cues present. By measuring the gap in accuracy on the highest and lowest ranked images (we call this spurious gap), we assess spurious feature reliance for $89$ diverse ImageNet models, finding that even the best models underperform in images with weak spurious presence. However, the effect of spurious cues varies far more dramatically across classes, emphasizing the crucial, often overlooked, class-dependence of the spurious correlation problem. While most spurious features we observe are clarifying (i.e. improving test-time accuracy when present, as is typically expected), we surprisingly find many cases of confusing spurious features, where models perform better when they are absent. We then close the spurious gap by training new classification heads on lowly ranked (i.e. without common spurious cues) images, resulting in improved effective robustness to distribution shifts (ObjectNet, ImageNet-R, ImageNet-Sketch). We also propose a second metric to assess feature reliability, finding that spurious features are generally less reliable than non-spurious (core) ones, though again, spurious features can be more reliable for certain classes. To enable our analysis, we annotated $5,000$ feature-class dependencies over {\it all} of ImageNet as core or spurious using minimal human supervision. Finally, we show the feature discovery and spuriosity ranking framework can be extended to other datasets like CelebA and WaterBirds in a lightweight fashion with only linear layer training, leading to discovering a previously unknown racial bias in the Celeb-A hair classification.