 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Combinatorial Allocations and Auctions with Few Samples
Sep 17, 2024In online combinatorial allocations/auctions, n bidders sequentially arrive, each with a combinatorial valuation (such as submodular/XOS) over subsets of m indivisible items. The aim is to immediately allocate a subset of the remaining items to maximize the total welfare, defined as the sum of bidder valuations. A long line of work has studied this problem when the bidder valuations come from known independent distributions. In particular, for submodular/XOS valuations, we know 2-competitive algorithms/mechanisms that set a fixed price for each item and the arriving bidders take their favorite subset of the remaining items given these prices. However, these algorithms traditionally presume the availability of the underlying distributions as part of the input to the algorithm. Contrary to this assumption, practical scenarios often require the learning of distributions, a task complicated by limited sample availability. This paper investigates the feasibility of achieving O(1)-competitive algorithms under the realistic constraint of having access to only a limited number of samples from the underlying bidder distributions. Our first main contribution shows that a mere single sample from each bidder distribution is sufficient to yield an O(1)-competitive algorithm for submodular/XOS valuations. This result leverages a novel extension of the secretary-style analysis, employing the sample to have the algorithm compete against itself. Although online, this first approach does not provide an online truthful mechanism. Our second main contribution shows that a polynomial number of samples suffices to yield a $(2+\epsilon)$-competitive online truthful mechanism for submodular/XOS valuations and any constant $\epsilon>0$. This result is based on a generalization of the median-based algorithm for the single-item prophet inequality problem to combinatorial settings with multiple items.
Allocating Indivisible Goods to Strategic Agents: Pure Nash Equilibria and Fairness
Sep 17, 2021We consider the problem of fairly allocating a set of indivisible goods to a set of strategic agents with additive valuation functions. We assume no monetary transfers and, therefore, a mechanism in our setting is an algorithm that takes as input the reported -- rather than the true -- values of the agents. Our main goal is to explore whether there exist mechanisms that have pure Nash equilibria for every instance and, at the same time, provide fairness guarantees for the allocations that correspond to these equilibria. We focus on two relaxations of envy-freeness, namely envy-freeness up to one good (EF1), and envy-freeness up to any good (EFX), and we positively answer the above question. In particular, we study two algorithms that are known to produce such allocations in the non-strategic setting: Round-Robin (EF1 allocations for any number of agents) and a cut-and-choose algorithm of Plaut and Roughgarden [SIAM Journal of Discrete Mathematics, 2020] (EFX allocations for two agents). For Round-Robin we show that all of its pure Nash equilibria induce allocations that are EF1 with respect to the underlying true values, while for the algorithm of Plaut and Roughgarden we show that the corresponding allocations not only are EFX but also satisfy maximin share fairness, something that is not true for this algorithm in the non-strategic setting! Further, we show that a weaker version of the latter result holds for any mechanism for two agents that always has pure Nash equilibria which all induce EFX allocations.
Submodular Maximization subject to a Knapsack Constraint: Combinatorial Algorithms with Near-optimal Adaptive Complexity
Feb 16, 2021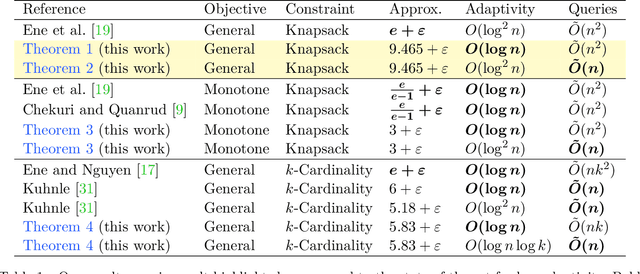
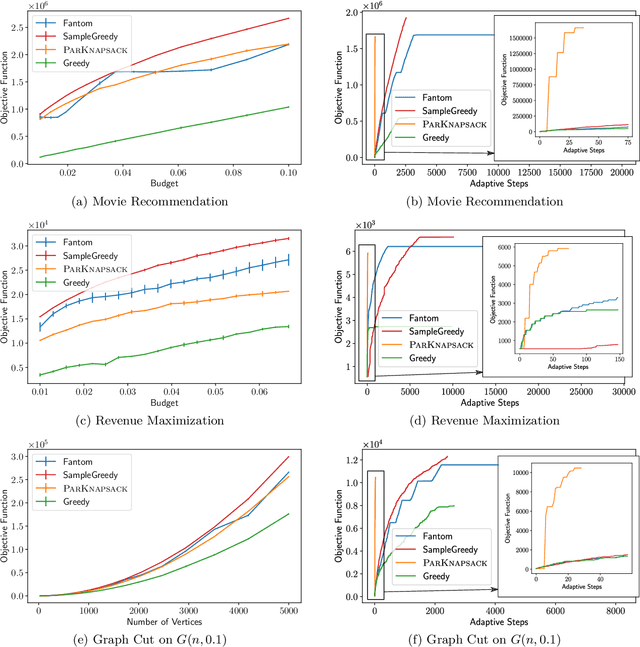
The growing need to deal with massive instances motivates the design of algorithms balancing the quality of the solution with applicability. For the latter, an important measure is the \emph{adaptive complexity}, capturing the number of sequential rounds of parallel computation needed. In this work we obtain the first \emph{constant factor} approximation algorithm for non-monotone submodular maximization subject to a knapsack constraint with \emph{near-optimal} $O(\log n)$ adaptive complexity. Low adaptivity by itself, however, is not enough: one needs to account for the total number of function evaluations (or value queries) as well. Our algorithm asks $\tilde{O}(n^2)$ value queries, but can be modified to run with only $\tilde{O}(n)$ instead, while retaining a low adaptive complexity of $O(\log^2n)$. Besides the above improvement in adaptivity, this is also the first \emph{combinatorial} approach with sublinear adaptive complexity for the problem and yields algorithms comparable to the state-of-the-art even for the special cases of cardinality constraints or monotone objectives. Finally, we showcase our algorithms' applicability on real-world datasets.
Fast Adaptive Non-Monotone Submodular Maximization Subject to a Knapsack Constraint
Jul 09, 2020
Constrained submodular maximization problems encompass a wide variety of applications, including personalized recommendation, team formation, and revenue maximization via viral marketing. The massive instances occurring in modern day applications can render existing algorithms prohibitively slow, while frequently, those instances are also inherently stochastic. Focusing on these challenges, we revisit the classic problem of maximizing a (possibly non-monotone) submodular function subject to a knapsack constraint. We present a simple randomized greedy algorithm that achieves a $5.83$ approximation and runs in $O(n \log n)$ time, i.e., at least a factor $n$ faster than other state-of-the-art algorithms. The robustness of our approach allows us to further transfer it to a stochastic version of the problem. There, we obtain a $9$-approximation to the best adaptive policy, which is the first constant approximation for non-monotone objectives. Experimental evaluation of our algorithms showcases their improved performance on real and synthetic data.
Trend Detection based Regret Minimization for Bandit Problems
Sep 15, 2017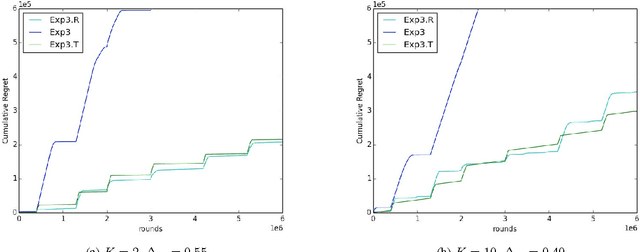
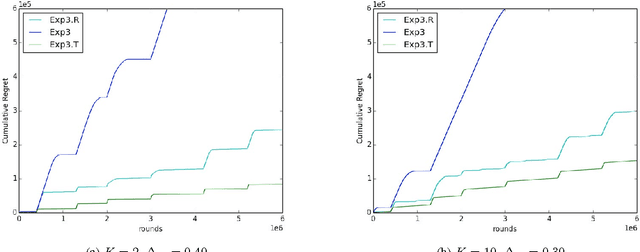
We study a variation of the classical multi-armed bandits problem. In this problem, the learner has to make a sequence of decisions, picking from a fixed set of choices. In each round, she receives as feedback only the loss incurred from the chosen action. Conventionally, this problem has been studied when losses of the actions are drawn from an unknown distribution or when they are adversarial. In this paper, we study this problem when the losses of the actions also satisfy certain structural properties, and especially, do show a trend structure. When this is true, we show that using \textit{trend detection}, we can achieve regret of order $\tilde{O} (N \sqrt{TK})$ with respect to a switching strategy for the version of the problem where a single action is chosen in each round and $\tilde{O} (Nm \sqrt{TK})$ when $m$ actions are chosen each round. This guarantee is a significant improvement over the conventional benchmark. Our approach can, as a framework, be applied in combination with various well-known bandit algorithms, like Exp3. For both versions of the problem, we give regret guarantees also for the \textit{anytime} setting, i.e. when the length of the choice-sequence is not known in advance. Finally, we pinpoint the advantages of our method by comparing it to some well-known other strategies.