 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Compensator: Altering Inference Cost of Vision Transformer without Re-Tuning
Paper and Code



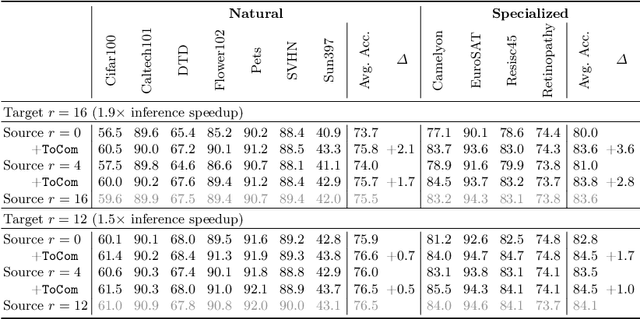
Token compression expedites the training and inference of Vision Transformers (ViTs) by reducing the number of the redundant tokens, e.g., pruning inattentive tokens or merging similar tokens. However, when applied to downstream tasks, these approaches suffer from significant performance drop when the compression degrees are mismatched between training and inference stages, which limits the application of token compression on off-the-shelf trained models. In this paper, we propose a model arithmetic framework to decouple the compression degrees between the two stages. In advance, we additionally perform a fast parameter-efficient self-distillation stage on the pre-trained models to obtain a small plugin, called Token Compensator (ToCom), which describes the gap between models across different compression degrees. During inference, ToCom can be directly inserted into any downstream off-the-shelf models with any mismatched training and inference compression degrees to acquire universal performance improvements without further training. Experiments on over 20 downstream tasks demonstrate the effectiveness of our framework. On CIFAR100, fine-grained visual classification, and VTAB-1k, ToCom can yield up to a maximum improvement of 2.3%, 1.5%, and 2.0% in the average performance of DeiT-B, respectively. Code: https://github.com/JieShibo/ToCom