 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBypassing Logits Bias in Online Class-Incremental Learning with a Generative Framework
May 19, 2022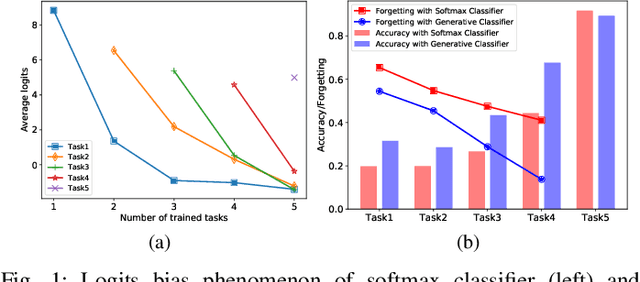
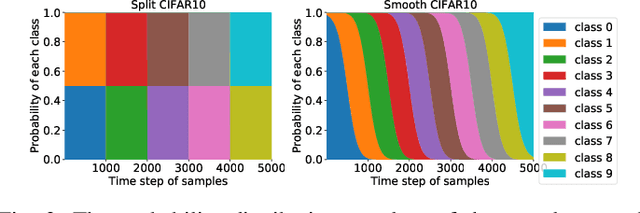
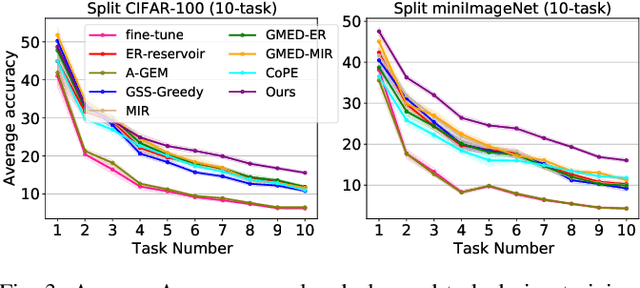
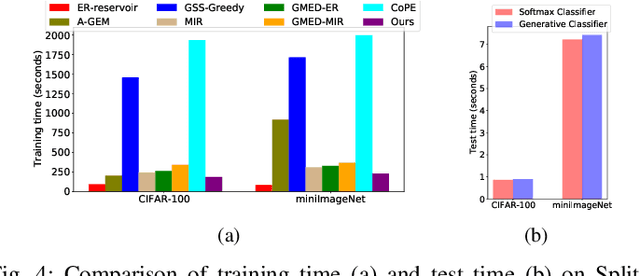
Continual learning requires the model to maintain the learned knowledge while learning from a non-i.i.d data stream continually. Due to the single-pass training setting, online continual learning is very challenging, but it is closer to the real-world scenarios where quick adaptation to new data is appealing. In this paper, we focus on online class-incremental learning setting in which new classes emerge over time. Almost all existing methods are replay-based with a softmax classifier. However, the inherent logits bias problem in the softmax classifier is a main cause of catastrophic forgetting while existing solutions are not applicable for online settings. To bypass this problem, we abandon the softmax classifier and propose a novel generative framework based on the feature space. In our framework, a generative classifier which utilizes replay memory is used for inference, and the training objective is a pair-based metric learning loss which is proven theoretically to optimize the feature space in a generative way. In order to improve the ability to learn new data, we further propose a hybrid of generative and discriminative loss to train the model. Extensive experiments on several benchmarks, including newly introduced task-free datasets, show that our method beats a series of state-of-the-art replay-based methods with discriminative classifiers, and reduces catastrophic forgetting consistently with a remarkable margin.
Self-Supervised Learning Aided Class-Incremental Lifelong Learning
Jun 19, 2020
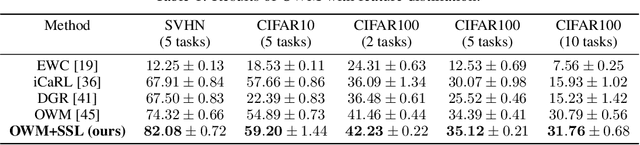
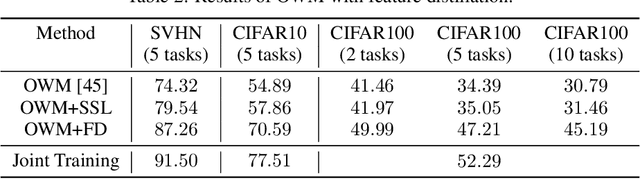
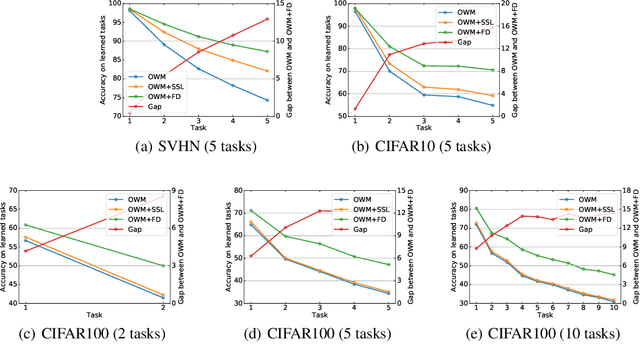
Lifelong or continual learning remains to be a challenge for artificial neural network, as it is required to be both stable for preservation of old knowledge and plastic for acquisition of new knowledge. It is common to see previous experience get overwritten, which leads to the well-known issue of catastrophic forgetting, especially in the scenario of class-incremental learning (Class-IL). Recently, many lifelong learning methods have been proposed to avoid catastrophic forgetting. However, models which learn without replay of the input data, would encounter another problem which has been ignored, and we refer to it as prior information loss (PIL). In training procedure of Class-IL, as the model has no knowledge about following tasks, it would only extract features necessary for tasks learned so far, whose information is insufficient for joint classification. In this paper, our empirical results on several image datasets show that PIL limits the performance of current state-of-the-art method for Class-IL, the orthogonal weights modification (OWM) algorithm. Furthermore, we propose to combine self-supervised learning, which can provide effective representations without requiring labels, with Class-IL to partly get around this problem. Experiments show superiority of proposed method to OWM, as well as other strong baselines.
Generative Feature Replay with Orthogonal Weight Modification for Continual Learning
May 07, 2020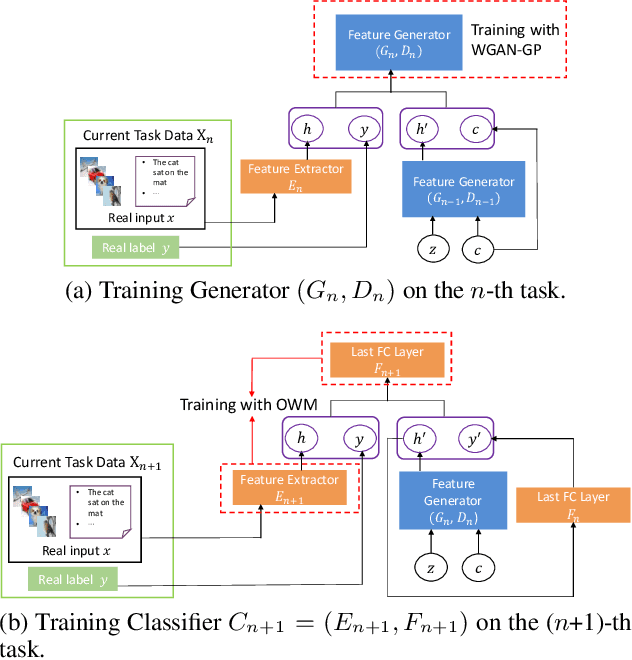


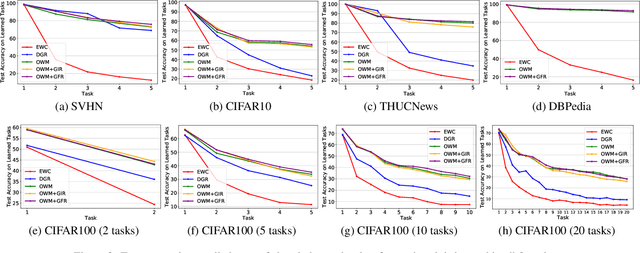
The ability of intelligent agents to learn and remember multiple tasks sequentially is crucial to achieving artificial general intelligence. Many continual learning (CL) methods have been proposed to overcome catastrophic forgetting. Catastrophic forgetting notoriously impedes the sequential learning of neural networks as the data of previous tasks are unavailable. In this paper we focus on class incremental learning, a challenging CL scenario, in which classes of each task are disjoint and task identity is unknown during test. For this scenario, generative replay is an effective strategy which generates and replays pseudo data for previous tasks to alleviate catastrophic forgetting. However, it is not trivial to learn a generative model continually for relatively complex data. Based on recently proposed orthogonal weight modification (OWM) algorithm which can keep previously learned input-output mappings invariant approximately when learning new tasks, we propose to directly generate and replay feature. Empirical results on image and text datasets show our method can improve OWM consistently by a significant margin while conventional generative replay always results in a negative effect. Our method also beats a state-of-the-art generative replay method and is competitive with a strong baseline based on real data storage.
Leap-LSTM: Enhancing Long Short-Term Memory for Text Categorization
May 28, 2019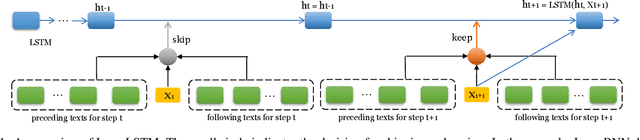



Recurrent Neural Networks (RNNs) are widely used in the field of natural language processing (NLP), ranging from text categorization to question answering and machine translation. However, RNNs generally read the whole text from beginning to end or vice versa sometimes, which makes it inefficient to process long texts. When reading a long document for a categorization task, such as topic categorization, large quantities of words are irrelevant and can be skipped. To this end, we propose Leap-LSTM, an LSTM-enhanced model which dynamically leaps between words while reading texts. At each step, we utilize several feature encoders to extract messages from preceding texts, following texts and the current word, and then determine whether to skip the current word. We evaluate Leap-LSTM on several text categorization tasks: sentiment analysis, news categorization, ontology classification and topic classification, with five benchmark data sets. The experimental results show that our model reads faster and predicts better than standard LSTM. Compared to previous models which can also skip words, our model achieves better trade-offs between performance and efficiency.
Learning to Compose over Tree Structures via POS Tags
Aug 21, 2018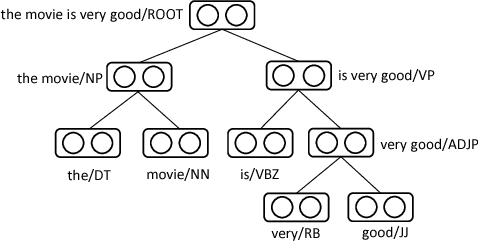

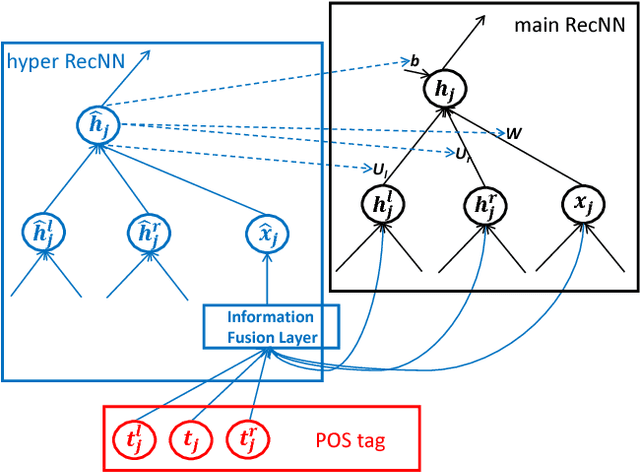

Recursive Neural Network (RecNN), a type of models which compose words or phrases recursively over syntactic tree structures, has been proven to have superior ability to obtain sentence representation for a variety of NLP tasks. However, RecNN is born with a thorny problem that a shared compositional function for each node of trees can't capture the complex semantic compositionality so that the expressive power of model is limited. In this paper, in order to address this problem, we propose Tag-Guided HyperRecNN/TreeLSTM (TG-HRecNN/TreeLSTM), which introduces hypernetwork into RecNNs to take as inputs Part-of-Speech (POS) tags of word/phrase and generate the semantic composition parameters dynamically. Experimental results on five datasets for two typical NLP tasks show proposed models both obtain significant improvement compared with RecNN and TreeLSTM consistently. Our TG-HTreeLSTM outperforms all existing RecNN-based models and achieves or is competitive with state-of-the-art on four sentence classification benchmarks. The effectiveness of our models is also demonstrated by qualitative analysis.
A Novel Framework for Recurrent Neural Networks with Enhancing Information Processing and Transmission between Units
Jun 02, 2018



This paper proposes a novel framework for recurrent neural networks (RNNs) inspired by the human memory models in the field of cognitive neuroscience to enhance information processing and transmission between adjacent RNNs' units. The proposed framework for RNNs consists of three stages that is working memory, forget, and long-term store. The first stage includes taking input data into sensory memory and transferring it to working memory for preliminary treatment. And the second stage mainly focuses on proactively forgetting the secondary information rather than the primary in the working memory. And finally, we get the long-term store normally using some kind of RNN's unit. Our framework, which is generalized and simple, is evaluated on 6 datasets which fall into 3 different tasks, corresponding to text classification, image classification and language modelling. Experiments reveal that our framework can obviously improve the performance of traditional recurrent neural networks. And exploratory task shows the ability of our framework of correctly forgetting the secondary information.
A Gap-Based Framework for Chinese Word Segmentation via Very Deep Convolutional Networks
Dec 27, 2017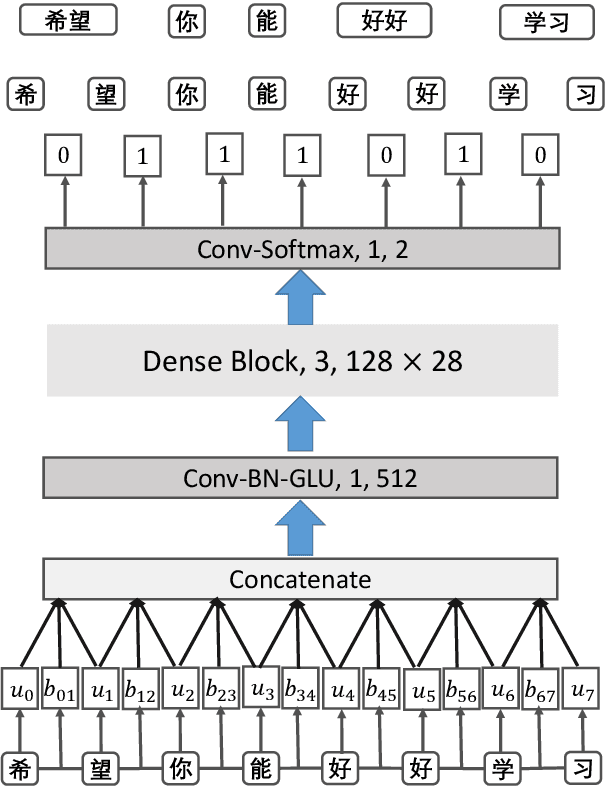
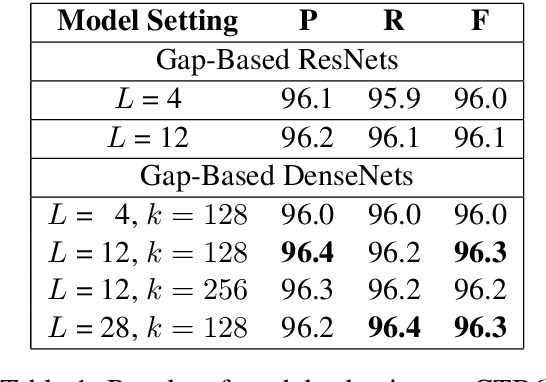
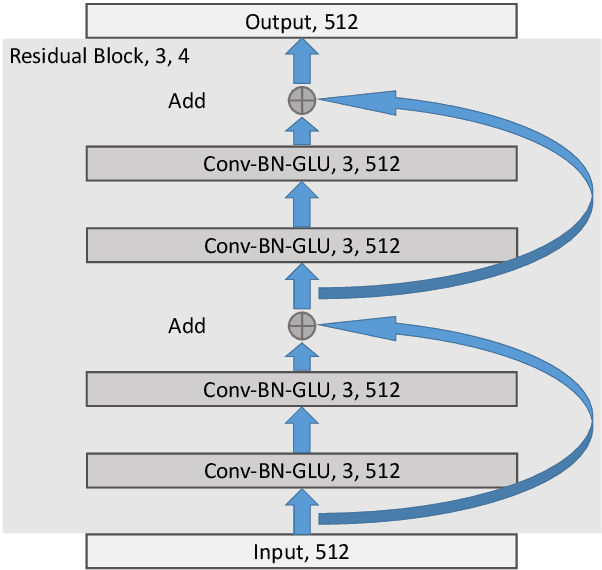
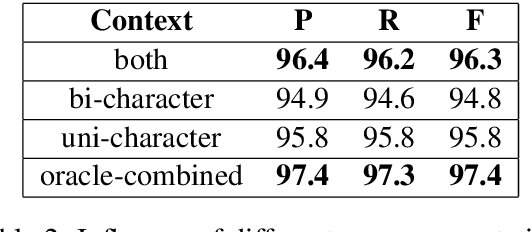
Most previous approaches to Chinese word segmentation can be roughly classified into character-based and word-based methods. The former regards this task as a sequence-labeling problem, while the latter directly segments character sequence into words. However, if we consider segmenting a given sentence, the most intuitive idea is to predict whether to segment for each gap between two consecutive characters, which in comparison makes previous approaches seem too complex. Therefore, in this paper, we propose a gap-based framework to implement this intuitive idea. Moreover, very deep convolutional neural networks, namely, ResNets and DenseNets, are exploited in our experiments. Results show that our approach outperforms the best character-based and word-based methods on 5 benchmarks, without any further post-processing module (e.g. Conditional Random Fields) nor beam search.