 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Hides behind Unfairness? Exploring Dynamics Fairness in Reinforcement Learning
Apr 16, 2024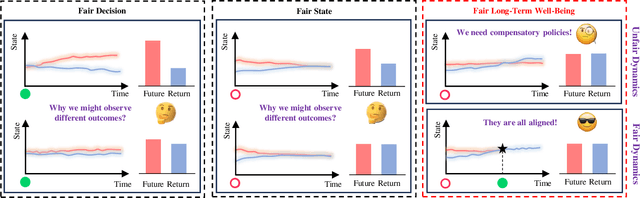
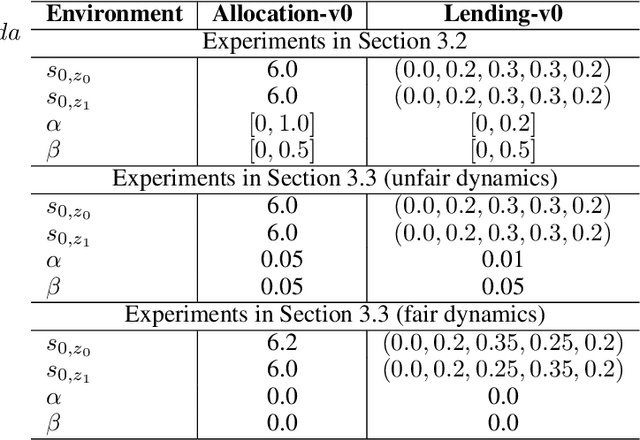
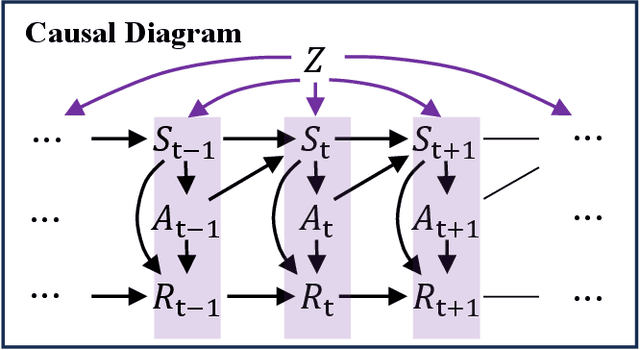

In sequential decision-making problems involving sensitive attributes like race and gender, reinforcement learning (RL) agents must carefully consider long-term fairness while maximizing returns. Recent works have proposed many different types of fairness notions, but how unfairness arises in RL problems remains unclear. In this paper, we address this gap in the literature by investigating the sources of inequality through a causal lens. We first analyse the causal relationships governing the data generation process and decompose the effect of sensitive attributes on long-term well-being into distinct components. We then introduce a novel notion called dynamics fairness, which explicitly captures the inequality stemming from environmental dynamics, distinguishing it from those induced by decision-making or inherited from the past. This notion requires evaluating the expected changes in the next state and the reward induced by changing the value of the sensitive attribute while holding everything else constant. To quantitatively evaluate this counterfactual concept, we derive identification formulas that allow us to obtain reliable estimations from data. Extensive experiments demonstrate the effectiveness of the proposed techniques in explaining, detecting, and reducing inequality in reinforcement learning.
Prefix-Tuning Based Unsupervised Text Style Transfer
Oct 23, 2023
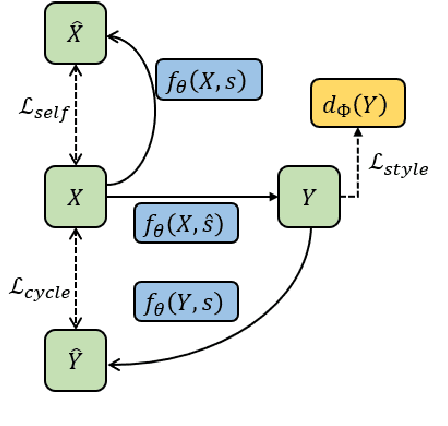
Unsupervised text style transfer aims at training a generative model that can alter the style of the input sentence while preserving its content without using any parallel data. In this paper, we employ powerful pre-trained large language models and present a new prefix-tuning-based method for unsupervised text style transfer. We construct three different kinds of prefixes, i.e., \textit{shared prefix, style prefix}, and \textit{content prefix}, to encode task-specific information, target style, and the content information of the input sentence, respectively. Compared to embeddings used by previous works, the proposed prefixes can provide richer information for the model. Furthermore, we adopt a recursive way of using language models in the process of style transfer. This strategy provides a more effective way for the interactions between the input sentence and GPT-2, helps the model construct more informative prefixes, and thus, helps improve the performance. Evaluations on the well-known datasets show that our method outperforms the state-of-the-art baselines. Results, analysis of ablation studies, and subjective evaluations from humans are also provided for a deeper understanding of the proposed method.
Causal Reinforcement Learning: A Survey
Jul 04, 2023Reinforcement learning is an essential paradigm for solving sequential decision problems under uncertainty. Despite many remarkable achievements in recent decades, applying reinforcement learning methods in the real world remains challenging. One of the main obstacles is that reinforcement learning agents lack a fundamental understanding of the world and must therefore learn from scratch through numerous trial-and-error interactions. They may also face challenges in providing explanations for their decisions and generalizing the acquired knowledge. Causality, however, offers a notable advantage as it can formalize knowledge in a systematic manner and leverage invariance for effective knowledge transfer. This has led to the emergence of causal reinforcement learning, a subfield of reinforcement learning that seeks to enhance existing algorithms by incorporating causal relationships into the learning process. In this survey, we comprehensively review the literature on causal reinforcement learning. We first introduce the basic concepts of causality and reinforcement learning, and then explain how causality can address core challenges in non-causal reinforcement learning. We categorize and systematically review existing causal reinforcement learning approaches based on their target problems and methodologies. Finally, we outline open issues and future directions in this emerging field.
Retrieved Sequence Augmentation for Protein Representation Learning
Feb 24, 2023Protein language models have excelled in a variety of tasks, ranging from structure prediction to protein engineering. However, proteins are highly diverse in functions and structures, and current state-of-the-art models including the latest version of AlphaFold rely on Multiple Sequence Alignments (MSA) to feed in the evolutionary knowledge. Despite their success, heavy computational overheads, as well as the de novo and orphan proteins remain great challenges in protein representation learning. In this work, we show that MSAaugmented models inherently belong to retrievalaugmented methods. Motivated by this finding, we introduce Retrieved Sequence Augmentation(RSA) for protein representation learning without additional alignment or pre-processing. RSA links query protein sequences to a set of sequences with similar structures or properties in the database and combines these sequences for downstream prediction. We show that protein language models benefit from the retrieval enhancement on both structure prediction and property prediction tasks, with a 5% improvement on MSA Transformer on average while being 373 times faster. In addition, we show that our model can transfer to new protein domains better and outperforms MSA Transformer on de novo protein prediction. Our study fills a much-encountered gap in protein prediction and brings us a step closer to demystifying the domain knowledge needed to understand protein sequences. Code is available on https://github.com/HKUNLP/RSA.
Undersampling and Cumulative Class Re-decision Methods to Improve Detection of Agitation in People with Dementia
Feb 07, 2023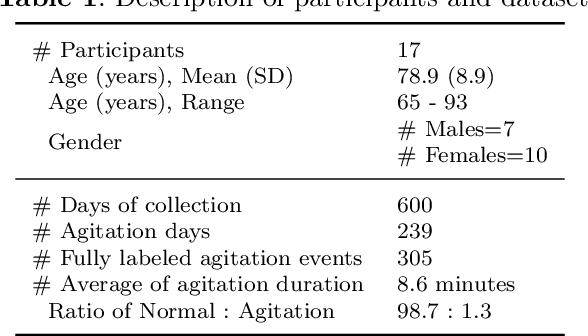
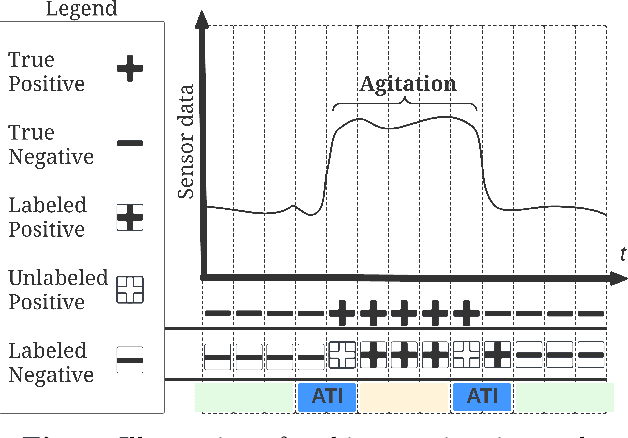
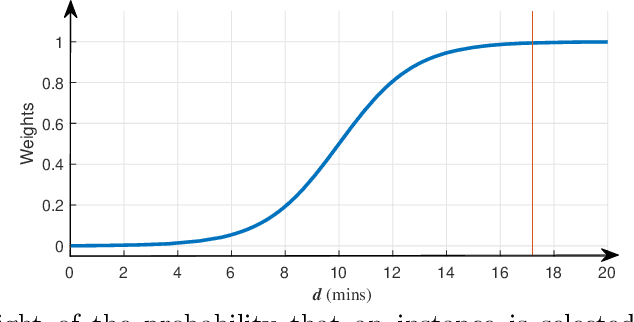
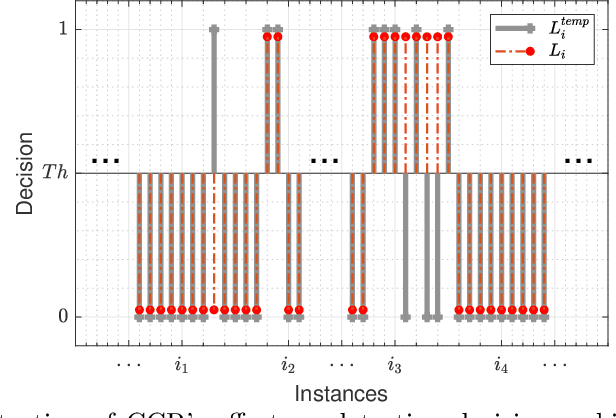
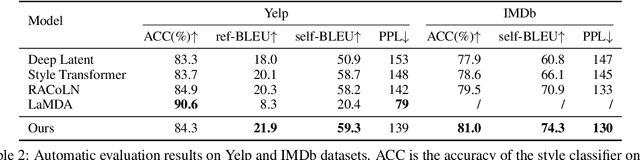
Agitation is one of the most prevalent symptoms in people with dementia (PwD) that can place themselves and the caregiver's safety at risk. Developing objective agitation detection approaches is important to support health and safety of PwD living in a residential setting. In a previous study, we collected multimodal wearable sensor data from 17 participants for 600 days and developed machine learning models for predicting agitation in one-minute windows. However, there are significant limitations in the dataset, such as imbalance problem and potential imprecise labels as the occurrence of agitation is much rarer in comparison to the normal behaviours. In this paper, we first implement different undersampling methods to eliminate the imbalance problem, and come to the conclusion that only 20% of normal behaviour data are adequate to train a competitive agitation detection model. Then, we design a weighted undersampling method to evaluate the manual labeling mechanism given the ambiguous time interval (ATI) assumption. After that, the postprocessing method of cumulative class re-decision (CCR) is proposed based on the historical sequential information and continuity characteristic of agitation, improving the decision-making performance for the potential application of agitation detection system. The results show that a combination of undersampling and CCR improves best F1-score by 26.6% and other metrics to varying degrees with less training time and data used, and inspires a way to find the potential range of optimal threshold reference for clinical purpose.
Pessimistic Bootstrapping for Uncertainty-Driven Offline Reinforcement Learning
Feb 23, 2022



Offline Reinforcement Learning (RL) aims to learn policies from previously collected datasets without exploring the environment. Directly applying off-policy algorithms to offline RL usually fails due to the extrapolation error caused by the out-of-distribution (OOD) actions. Previous methods tackle such problem by penalizing the Q-values of OOD actions or constraining the trained policy to be close to the behavior policy. Nevertheless, such methods typically prevent the generalization of value functions beyond the offline data and also lack precise characterization of OOD data. In this paper, we propose Pessimistic Bootstrapping for offline RL (PBRL), a purely uncertainty-driven offline algorithm without explicit policy constraints. Specifically, PBRL conducts uncertainty quantification via the disagreement of bootstrapped Q-functions, and performs pessimistic updates by penalizing the value function based on the estimated uncertainty. To tackle the extrapolating error, we further propose a novel OOD sampling method. We show that such OOD sampling and pessimistic bootstrapping yields provable uncertainty quantifier in linear MDPs, thus providing the theoretical underpinning for PBRL. Extensive experiments on D4RL benchmark show that PBRL has better performance compared to the state-of-the-art algorithms.
SCORE: Spurious COrrelation REduction for Offline Reinforcement Learning
Oct 24, 2021



Offline reinforcement learning (RL) aims to learn the optimal policy from a pre-collected dataset without online interactions. Most of the existing studies focus on distributional shift caused by out-of-distribution actions. However, even in-distribution actions can raise serious problems. Since the dataset only contains limited information about the underlying model, offline RL is vulnerable to spurious correlations, i.e., the agent tends to prefer actions that by chance lead to high returns, resulting in a highly suboptimal policy. To address such a challenge, we propose a practical and theoretically guaranteed algorithm SCORE that reduces spurious correlations by combing an uncertainty penalty into policy evaluation. We show that this is consistent with the pessimism principle studied in theory, and the proposed algorithm converges to the optimal policy with a sublinear rate under mild assumptions. By conducting extensive experiments on existing benchmarks, we show that SCORE not only benefits from a solid theory but also obtains strong empirical results on a variety of tasks.
Domain Adaptation via Maximizing Surrogate Mutual Information
Oct 23, 2021



Unsupervised domain adaptation (UDA), which is an important topic in transfer learning, aims to predict unlabeled data from target domain with access to labeled data from the source domain. In this work, we propose a novel framework called SIDA (Surrogate Mutual Information Maximization Domain Adaptation) with strong theoretical guarantees. To be specific, SIDA implements adaptation by maximizing mutual information (MI) between features. In the framework, a surrogate joint distribution models the underlying joint distribution of the unlabeled target domain. Our theoretical analysis validates SIDA by bounding the expected risk on target domain with MI and surrogate distribution bias. Experiments show that our approach is comparable with state-of-the-art unsupervised adaptation methods on standard UDA tasks.
A Novel Framework for Recurrent Neural Networks with Enhancing Information Processing and Transmission between Units
Jun 02, 2018



This paper proposes a novel framework for recurrent neural networks (RNNs) inspired by the human memory models in the field of cognitive neuroscience to enhance information processing and transmission between adjacent RNNs' units. The proposed framework for RNNs consists of three stages that is working memory, forget, and long-term store. The first stage includes taking input data into sensory memory and transferring it to working memory for preliminary treatment. And the second stage mainly focuses on proactively forgetting the secondary information rather than the primary in the working memory. And finally, we get the long-term store normally using some kind of RNN's unit. Our framework, which is generalized and simple, is evaluated on 6 datasets which fall into 3 different tasks, corresponding to text classification, image classification and language modelling. Experiments reveal that our framework can obviously improve the performance of traditional recurrent neural networks. And exploratory task shows the ability of our framework of correctly forgetting the secondary information.
A Gap-Based Framework for Chinese Word Segmentation via Very Deep Convolutional Networks
Dec 27, 2017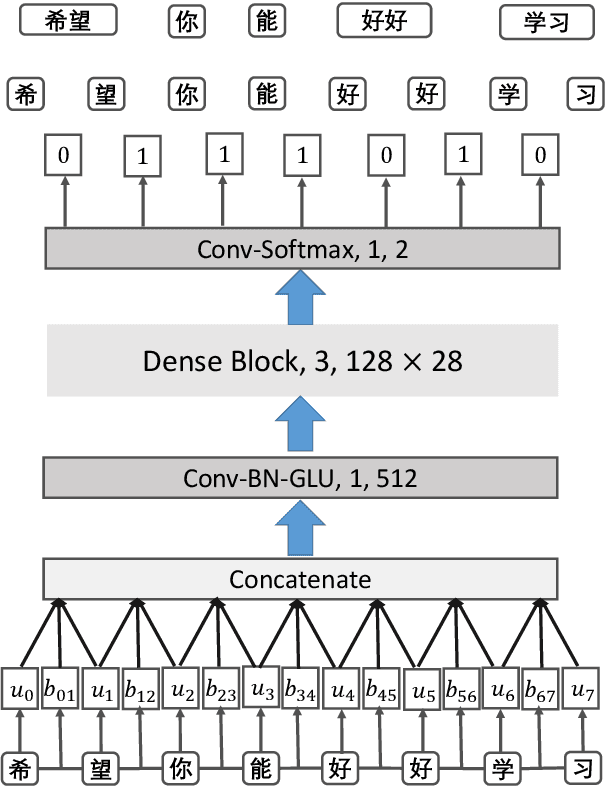
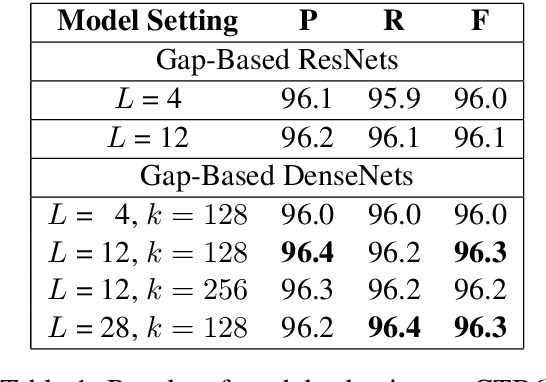
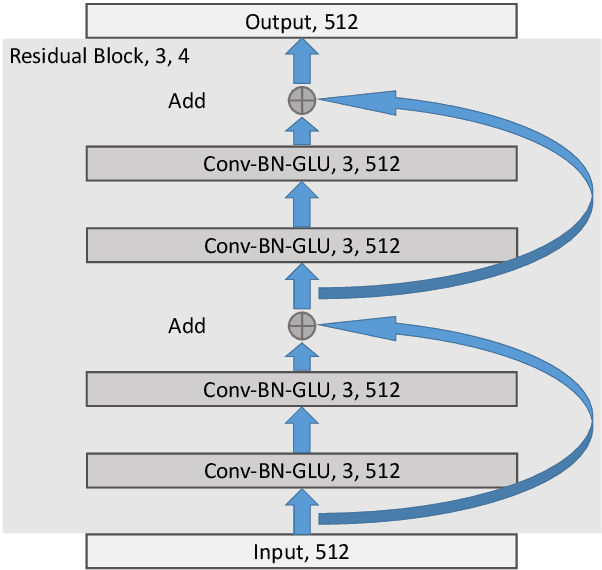
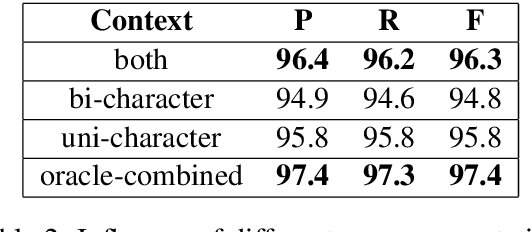
Most previous approaches to Chinese word segmentation can be roughly classified into character-based and word-based methods. The former regards this task as a sequence-labeling problem, while the latter directly segments character sequence into words. However, if we consider segmenting a given sentence, the most intuitive idea is to predict whether to segment for each gap between two consecutive characters, which in comparison makes previous approaches seem too complex. Therefore, in this paper, we propose a gap-based framework to implement this intuitive idea. Moreover, very deep convolutional neural networks, namely, ResNets and DenseNets, are exploited in our experiments. Results show that our approach outperforms the best character-based and word-based methods on 5 benchmarks, without any further post-processing module (e.g. Conditional Random Fields) nor beam search.