 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurrogate Ensemble in Expensive Multi-Objective Optimization via Deep Q-Learning
Jan 31, 2026Surrogate-assisted Evolutionary Algorithms~(SAEAs) have shown promising robustness in solving expensive optimization problems. A key aspect that impacts SAEAs' effectiveness is surrogate model selection, which in existing works is predominantly decided by human developer. Such human-made design choice introduces strong bias into SAEAs and may hurt their expected performance on out-of-scope tasks. In this paper, we propose a reinforcement learning-assisted ensemble framework, termed as SEEMOO, which is capable of scheduling different surrogate models within a single optimization process, hence boosting the overall optimization performance in a cooperative paradigm. Specifically, we focus on expensive multi-objective optimization problems, where multiple objective functions shape a compositional landscape and hence challenge surrogate selection. SEEMOO comprises following core designs: 1) A pre-collected model pool that maintains different surrogate models; 2) An attention-based state-extractor supports universal optimization state representation of problems with varied objective numbers; 3) a deep Q-network serves as dynamic surrogate selector: Given the optimization state, it selects desired surrogate model for current-step evaluation. SEEMOO is trained to maximize the overall optimization performance under a training problem distribution. Extensive benchmark results demonstrate SEEMOO's surrogate ensemble paradigm boosts the optimization performance of single-surrogate baselines. Further ablation studies underscore the importance of SEEMOO's design components.
Reinforcement Learning-assisted Constraint Relaxation for Constrained Expensive Optimization
Jan 31, 2026Constraint handling plays a key role in solving realistic complex optimization problems. Though intensively discussed in the last few decades, existing constraint handling techniques predominantly rely on human experts' designs, which more or less fall short in utility towards general cases. Motivated by recent progress in Meta-Black-Box Optimization where automated algorithm design can be learned to boost optimization performance, in this paper, we propose learning effective, adaptive and generalizable constraint handling policy through reinforcement learning. Specifically, a tailored Markov Decision Process is first formulated, where given optimization dynamics features, a deep Q-network-based policy controls the constraint relaxation level along the underlying optimization process. Such adaptive constraint handling provides flexible tradeoff between objective-oriented exploitation and feasible-region-oriented exploration, and hence leads to promising optimization performance. We train our approach on CEC 2017 Constrained Optimization benchmark with limited evaluation budget condition (expensive cases) and compare the trained constraint handling policy to strong baselines such as recent winners in CEC/GECCO competitions. Extensive experimental results show that our approach performs competitively or even surpasses the compared baselines under either Leave-one-out cross-validation or ordinary train-test split validation. Further analysis and ablation studies reveal key insights in our designs.
Detect and Act: Automated Dynamic Optimizer through Meta-Black-Box Optimization
Jan 30, 2026Dynamic Optimization Problems (DOPs) are challenging to address due to their complex nature, i.e., dynamic environment variation. Evolutionary Computation methods are generally advantaged in solving DOPs since they resemble dynamic biological evolution. However, existing evolutionary dynamic optimization methods rely heavily on human-crafted adaptive strategy to detect environment variation in DOPs, and then adapt the searching strategy accordingly. These hand-crafted strategies may perform ineffectively at out-of-box scenarios. In this paper, we propose a reinforcement learning-assisted approach to enable automated variation detection and self-adaption in evolutionary algorithms. This is achieved by borrowing the bi-level learning-to-optimize idea from recent Meta-Black-Box Optimization works. We use a deep Q-network as optimization dynamics detector and searching strategy adapter: It is fed as input with current-step optimization state and then dictates desired control parameters to underlying evolutionary algorithms for next-step optimization. The learning objective is to maximize the expected performance gain across a problem distribution. Once trained, our approach could generalize toward unseen DOPs with automated environment variation detection and self-adaption. To facilitate comprehensive validation, we further construct an easy-to-difficult DOPs testbed with diverse synthetic instances. Extensive benchmark results demonstrate flexible searching behavior and superior performance of our approach in solving DOPs, compared to state-of-the-art baselines.
COBRA++: Enhanced COBRA Optimizer with Augmented Surrogate Pool and Reinforced Surrogate Selection
Jan 30, 2026The optimization problems in realistic world present significant challenges onto optimization algorithms, such as the expensive evaluation issue and complex constraint conditions. COBRA optimizer (including its up-to-date variants) is a representative and effective tool for addressing such optimization problems, which introduces 1) RBF surrogate to reduce online evaluation and 2) bi-stage optimization process to alternate search for feasible solution and optimal solution. Though promising, its design space, i.e., surrogate model pool and selection standard, is still manually decided by human expert, resulting in labor-intensive fine-tuning for novel tasks. In this paper, we propose a learning-based adaptive strategy (COBRA++) that enhances COBRA in two aspects: 1) An augmented surrogate pool to break the tie with RBF-like surrogate and hence enhances model diversity and approximation capability; 2) A reinforcement learning-based online model selection policy that empowers efficient and accurate optimization process. The model selection policy is trained to maximize overall performance of COBRA++ across a distribution of constrained optimization problems with diverse properties. We have conducted multi-dimensional validation experiments and demonstrate that COBRA++ achieves substantial performance improvement against vanilla COBRA and its adaptive variant. Ablation studies are provided to support correctness of each design component in COBRA++.
READY: Reward Discovery for Meta-Black-Box Optimization
Jan 29, 2026Meta-Black-Box Optimization (MetaBBO) is an emerging avenue within Optimization community, where algorithm design policy could be meta-learned by reinforcement learning to enhance optimization performance. So far, the reward functions in existing MetaBBO works are designed by human experts, introducing certain design bias and risks of reward hacking. In this paper, we use Large Language Model~(LLM) as an automated reward discovery tool for MetaBBO. Specifically, we consider both effectiveness and efficiency sides. On effectiveness side, we borrow the idea of evolution of heuristics, introducing tailored evolution paradigm in the iterative LLM-based program search process, which ensures continuous improvement. On efficiency side, we additionally introduce multi-task evolution architecture to support parallel reward discovery for diverse MetaBBO approaches. Such parallel process also benefits from knowledge sharing across tasks to accelerate convergence. Empirical results demonstrate that the reward functions discovered by our approach could be helpful for boosting existing MetaBBO works, underscoring the importance of reward design in MetaBBO. We provide READY's project at https://anonymous.4open.science/r/ICML_READY-747F.
MetaBox-v2: A Unified Benchmark Platform for Meta-Black-Box Optimization
May 23, 2025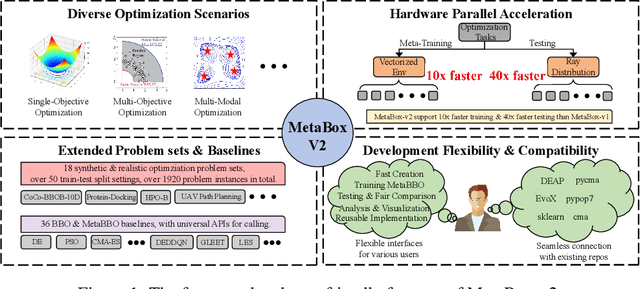
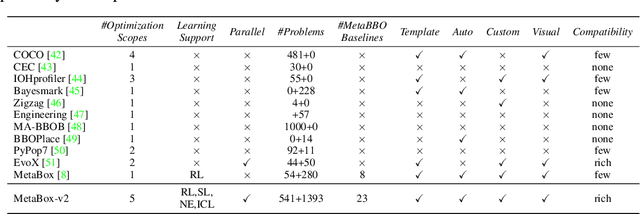
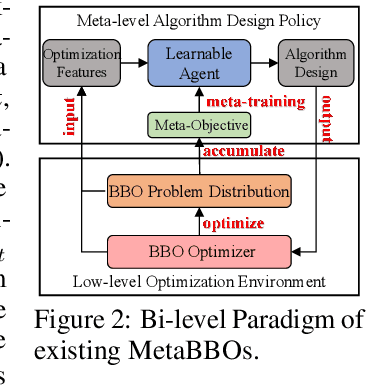
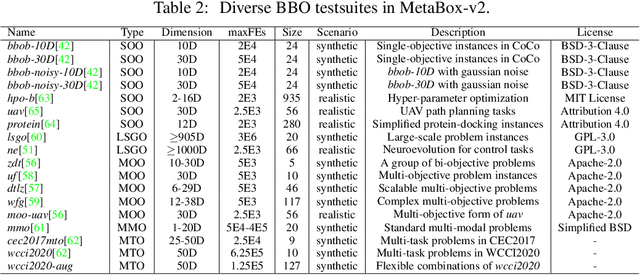
Meta-Black-Box Optimization (MetaBBO) streamlines the automation of optimization algorithm design through meta-learning. It typically employs a bi-level structure: the meta-level policy undergoes meta-training to reduce the manual effort required in developing algorithms for low-level optimization tasks. The original MetaBox (2023) provided the first open-source framework for reinforcement learning-based single-objective MetaBBO. However, its relatively narrow scope no longer keep pace with the swift advancement in this field. In this paper, we introduce MetaBox-v2 (https://github.com/MetaEvo/MetaBox) as a milestone upgrade with four novel features: 1) a unified architecture supporting RL, evolutionary, and gradient-based approaches, by which we reproduce 23 up-to-date baselines; 2) efficient parallelization schemes, which reduce the training/testing time by 10-40x; 3) a comprehensive benchmark suite of 18 synthetic/realistic tasks (1900+ instances) spanning single-objective, multi-objective, multi-model, and multi-task optimization scenarios; 4) plentiful and extensible interfaces for custom analysis/visualization and integrating to external optimization tools/benchmarks. To show the utility of MetaBox-v2, we carry out a systematic case study that evaluates the built-in baselines in terms of the optimization performance, generalization ability and learning efficiency. Valuable insights are concluded from thorough and detailed analysis for practitioners and those new to the field.
DesignX: Human-Competitive Algorithm Designer for Black-Box Optimization
May 23, 2025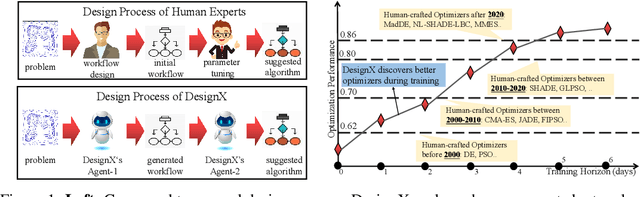
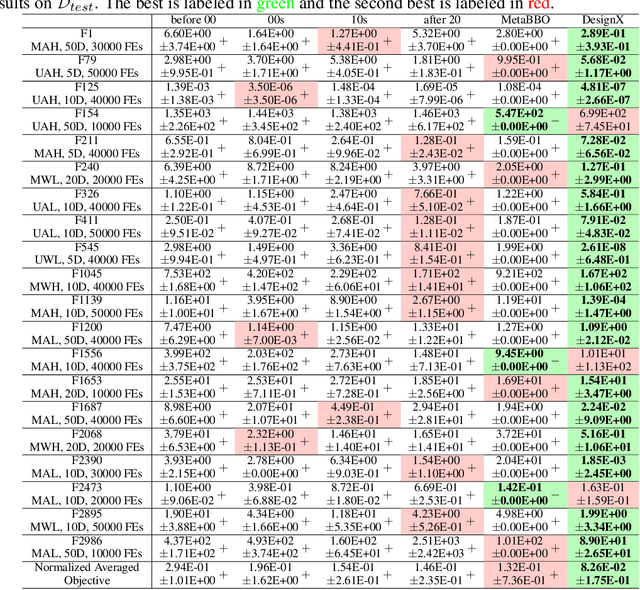
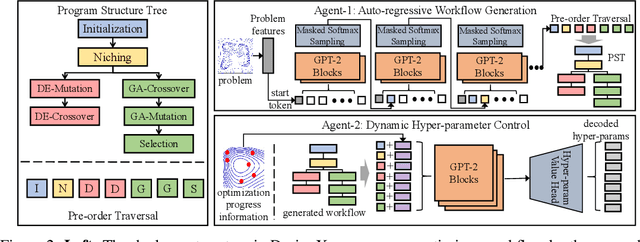
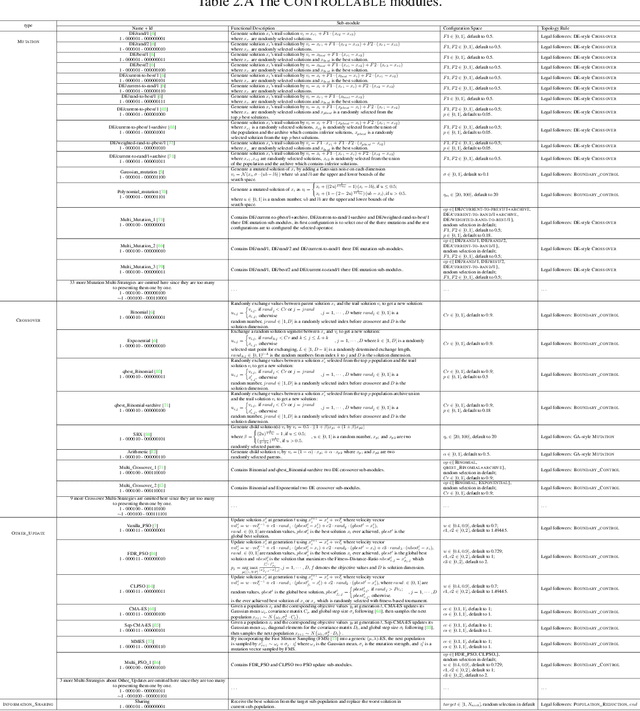
Designing effective black-box optimizers is hampered by limited problem-specific knowledge and manual control that spans months for almost every detail. In this paper, we present DesignX, the first automated algorithm design framework that generates an effective optimizer specific to a given black-box optimization problem within seconds. Rooted in the first principles, we identify two key sub-tasks: 1) algorithm structure generation and 2) hyperparameter control. To enable systematic construction, a comprehensive modular algorithmic space is first built, embracing hundreds of algorithm components collected from decades of research. We then introduce a dual-agent reinforcement learning system that collaborates on structural and parametric design through a novel cooperative training objective, enabling large-scale meta-training across 10k diverse instances. Remarkably, through days of autonomous learning, the DesignX-generated optimizers continuously surpass human-crafted optimizers by orders of magnitude, either on synthetic testbed or on realistic optimization scenarios such as Protein-docking, AutoML and UAV path planning. Further in-depth analysis reveals DesignX's capability to discover non-trivial algorithm patterns beyond expert intuition, which, conversely, provides valuable design insights for the optimization community. We provide DesignX's inference code at https://github.com/MetaEvo/DesignX.
Meta-Black-Box-Optimization through Offline Q-function Learning
May 04, 2025Recent progress in Meta-Black-Box-Optimization (MetaBBO) has demonstrated that using RL to learn a meta-level policy for dynamic algorithm configuration (DAC) over an optimization task distribution could significantly enhance the performance of the low-level BBO algorithm. However, the online learning paradigms in existing works makes the efficiency of MetaBBO problematic. To address this, we propose an offline learning-based MetaBBO framework in this paper, termed Q-Mamba, to attain both effectiveness and efficiency in MetaBBO. Specifically, we first transform DAC task into long-sequence decision process. This allows us further introduce an effective Q-function decomposition mechanism to reduce the learning difficulty within the intricate algorithm configuration space. Under this setting, we propose three novel designs to meta-learn DAC policy from offline data: we first propose a novel collection strategy for constructing offline DAC experiences dataset with balanced exploration and exploitation. We then establish a decomposition-based Q-loss that incorporates conservative Q-learning to promote stable offline learning from the offline dataset. To further improve the offline learning efficiency, we equip our work with a Mamba architecture which helps long-sequence learning effectiveness and efficiency by selective state model and hardware-aware parallel scan respectively. Through extensive benchmarking, we observe that Q-Mamba achieves competitive or even superior performance to prior online/offline baselines, while significantly improving the training efficiency of existing online baselines. We provide sourcecodes of Q-Mamba at https://github.com/MetaEvo/Q-Mamba.
Advancing CMA-ES with Learning-Based Cooperative Coevolution for Scalable Optimization
Apr 24, 2025Recent research in Cooperative Coevolution~(CC) have achieved promising progress in solving large-scale global optimization problems. However, existing CC paradigms have a primary limitation in that they require deep expertise for selecting or designing effective variable decomposition strategies. Inspired by advancements in Meta-Black-Box Optimization, this paper introduces LCC, a pioneering learning-based cooperative coevolution framework that dynamically schedules decomposition strategies during optimization processes. The decomposition strategy selector is parameterized through a neural network, which processes a meticulously crafted set of optimization status features to determine the optimal strategy for each optimization step. The network is trained via the Proximal Policy Optimization method in a reinforcement learning manner across a collection of representative problems, aiming to maximize the expected optimization performance. Extensive experimental results demonstrate that LCC not only offers certain advantages over state-of-the-art baselines in terms of optimization effectiveness and resource consumption, but it also exhibits promising transferability towards unseen problems.
ConfigX: Modular Configuration for Evolutionary Algorithms via Multitask Reinforcement Learning
Dec 10, 2024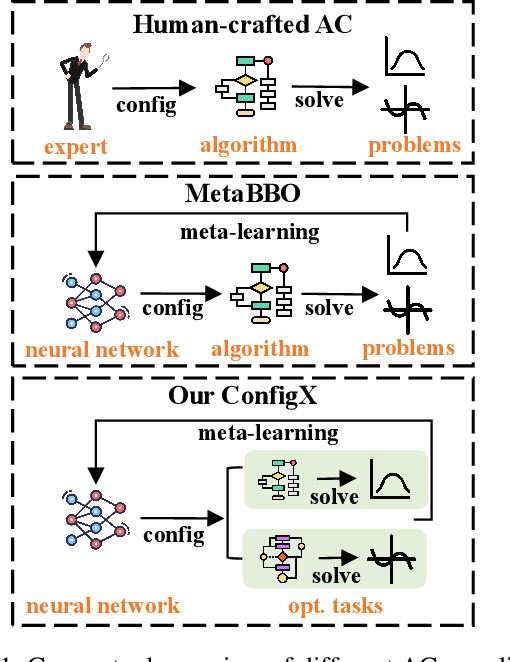
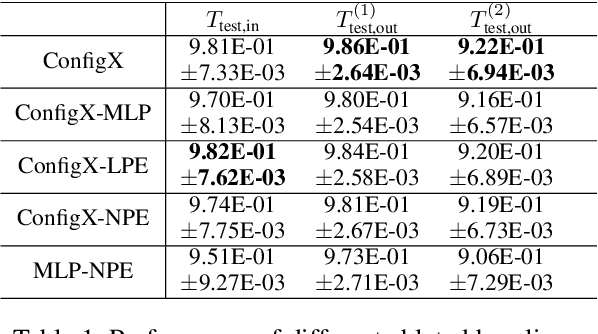
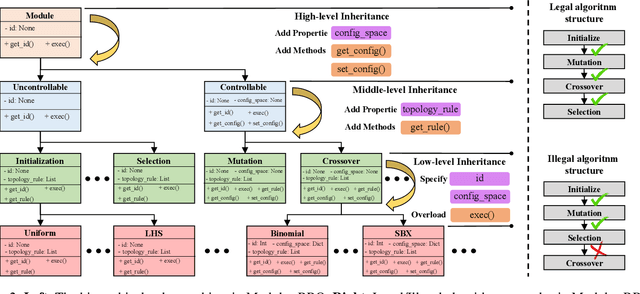
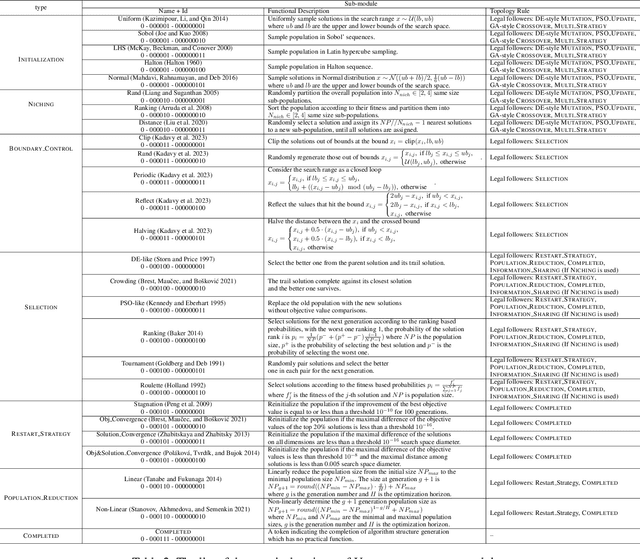
Recent advances in Meta-learning for Black-Box Optimization (MetaBBO) have shown the potential of using neural networks to dynamically configure evolutionary algorithms (EAs), enhancing their performance and adaptability across various BBO instances. However, they are often tailored to a specific EA, which limits their generalizability and necessitates retraining or redesigns for different EAs and optimization problems. To address this limitation, we introduce ConfigX, a new paradigm of the MetaBBO framework that is capable of learning a universal configuration agent (model) for boosting diverse EAs. To achieve so, our ConfigX first leverages a novel modularization system that enables the flexible combination of various optimization sub-modules to generate diverse EAs during training. Additionally, we propose a Transformer-based neural network to meta-learn a universal configuration policy through multitask reinforcement learning across a designed joint optimization task space. Extensive experiments verify that, our ConfigX, after large-scale pre-training, achieves robust zero-shot generalization to unseen tasks and outperforms state-of-the-art baselines. Moreover, ConfigX exhibits strong lifelong learning capabilities, allowing efficient adaptation to new tasks through fine-tuning. Our proposed ConfigX represents a significant step toward an automatic, all-purpose configuration agent for EAs.