 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePitch Preservation In Singing Voice Synthesis
Paper and Code
Oct 12, 2021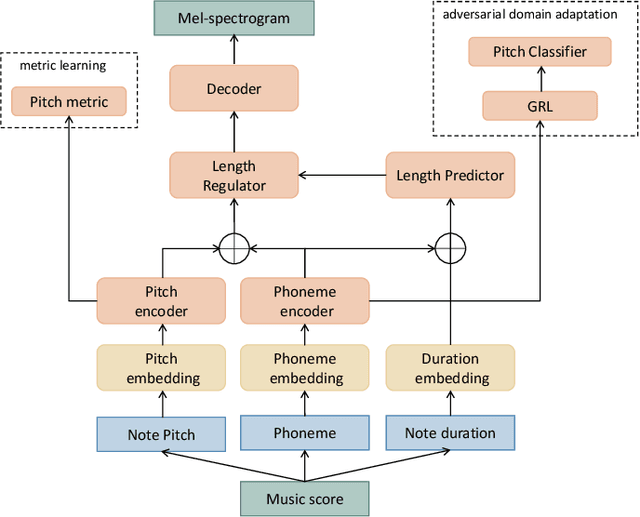
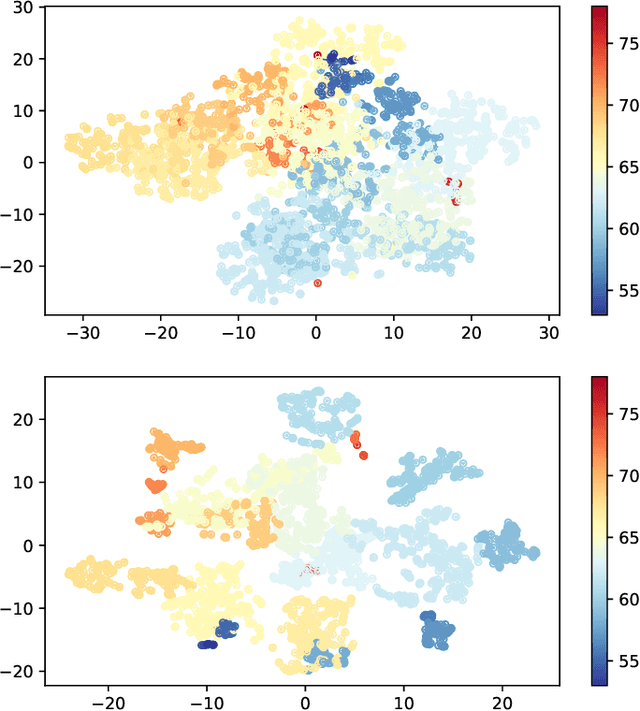
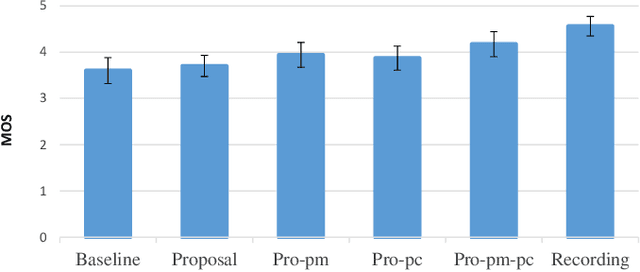
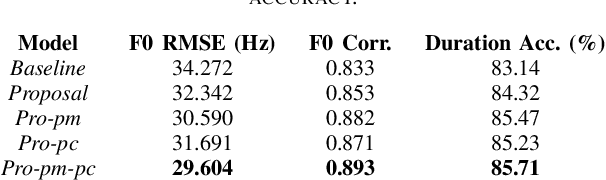
Suffering from limited singing voice corpus, existing singing voice synthesis (SVS) methods that build encoder-decoder neural networks to directly generate spectrogram could lead to out-of-tune issues during the inference phase. To attenuate these issues, this paper presents a novel acoustic model with independent pitch encoder and phoneme encoder, which disentangles the phoneme and pitch information from music score to fully utilize the corpus. Specifically, according to equal temperament theory, the pitch encoder is constrained by a pitch metric loss that maps distances between adjacent input pitches into corresponding frequency multiples between the encoder outputs. For the phoneme encoder, based on the analysis that same phonemes corresponding to varying pitches can produce similar pronunciations, this encoder is followed by an adversarially trained pitch classifier to enforce the identical phonemes with different pitches mapping into the same phoneme feature space. By these means, the sparse phonemes and pitches in original input spaces can be transformed into more compact feature spaces respectively, where the same elements cluster closely and cooperate mutually to enhance synthesis quality. Then, the outputs of the two encoders are summed together to pass through the following decoder in the acoustic model. Experimental results indicate that the proposed approaches can characterize intrinsic structure between pitch inputs to obtain better pitch synthesis accuracy and achieve superior singing synthesis performance against the advanced baseline system.