 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoINS: Counterfactual Interactive Navigation via Skill-Aware VLM
Jan 07, 2026Recent Vision-Language Models (VLMs) have demonstrated significant potential in robotic planning. However, they typically function as semantic reasoners, lacking an intrinsic understanding of the specific robot's physical capabilities. This limitation is particularly critical in interactive navigation, where robots must actively modify cluttered environments to create traversable paths. Existing VLM-based navigators are predominantly confined to passive obstacle avoidance, failing to reason about when and how to interact with objects to clear blocked paths. To bridge this gap, we propose Counterfactual Interactive Navigation via Skill-aware VLM (CoINS), a hierarchical framework that integrates skill-aware reasoning and robust low-level execution. Specifically, we fine-tune a VLM, named InterNav-VLM, which incorporates skill affordance and concrete constraint parameters into the input context and grounds them into a metric-scale environmental representation. By internalizing the logic of counterfactual reasoning through fine-tuning on the proposed InterNav dataset, the model learns to implicitly evaluate the causal effects of object removal on navigation connectivity, thereby determining interaction necessity and target selection. To execute the generated high-level plans, we develop a comprehensive skill library through reinforcement learning, specifically introducing traversability-oriented strategies to manipulate diverse objects for path clearance. A systematic benchmark in Isaac Sim is proposed to evaluate both the reasoning and execution aspects of interactive navigation. Extensive simulations and real-world experiments demonstrate that CoINS significantly outperforms representative baselines, achieving a 17\% higher overall success rate and over 80\% improvement in complex long-horizon scenarios compared to the best-performing baseline
VLA-RAIL: A Real-Time Asynchronous Inference Linker for VLA Models and Robots
Dec 31, 2025Vision-Language-Action (VLA) models have achieved remarkable breakthroughs in robotics, with the action chunk playing a dominant role in these advances. Given the real-time and continuous nature of robotic motion control, the strategies for fusing a queue of successive action chunks have a profound impact on the overall performance of VLA models. Existing methods suffer from jitter, stalling, or even pauses in robotic action execution, which not only limits the achievable execution speed but also reduces the overall success rate of task completion. This paper introduces VLA-RAIL (A Real-Time Asynchronous Inference Linker), a novel framework designed to address these issues by conducting model inference and robot motion control asynchronously and guaranteeing smooth, continuous, and high-speed action execution. The core contributions of the paper are two fold: a Trajectory Smoother that effectively filters out the noise and jitter in the trajectory of one action chunk using polynomial fitting and a Chunk Fuser that seamlessly align the current executing trajectory and the newly arrived chunk, ensuring position, velocity, and acceleration continuity between two successive action chunks. We validate the effectiveness of VLA-RAIL on a benchmark of dynamic simulation tasks and several real-world manipulation tasks. Experimental results demonstrate that VLA-RAIL significantly reduces motion jitter, enhances execution speed, and improves task success rates, which will become a key infrastructure for the large-scale deployment of VLA models.
ReSPIRe: Informative and Reusable Belief Tree Search for Robot Probabilistic Search and Tracking in Unknown Environments
Dec 31, 2025Target search and tracking (SAT) is a fundamental problem for various robotic applications such as search and rescue and environmental exploration. This paper proposes an informative trajectory planning approach, namely ReSPIRe, for SAT in unknown cluttered environments under considerably inaccurate prior target information and limited sensing field of view. We first develop a novel sigma point-based approximation approach to fast and accurately estimate mutual information reward under non-Gaussian belief distributions, utilizing informative sampling in state and observation spaces to mitigate the computational intractability of integral calculation. To tackle significant uncertainty associated with inadequate prior target information, we propose the hierarchical particle structure in ReSPIRe, which not only extracts critical particles for global route guidance, but also adjusts the particle number adaptively for planning efficiency. Building upon the hierarchical structure, we develop the reusable belief tree search approach to build a policy tree for online trajectory planning under uncertainty, which reuses rollout evaluation to improve planning efficiency. Extensive simulations and real-world experiments demonstrate that ReSPIRe outperforms representative benchmark methods with smaller MI approximation error, higher search efficiency, and more stable tracking performance, while maintaining outstanding computational efficiency.
Training Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
LLM-based Human-like Traffic Simulation for Self-driving Tests
Aug 23, 2025Ensuring realistic traffic dynamics is a prerequisite for simulation platforms to evaluate the reliability of self-driving systems before deployment in the real world. Because most road users are human drivers, reproducing their diverse behaviors within simulators is vital. Existing solutions, however, typically rely on either handcrafted heuristics or narrow data-driven models, which capture only fragments of real driving behaviors and offer limited driving style diversity and interpretability. To address this gap, we introduce HDSim, an HD traffic generation framework that combines cognitive theory with large language model (LLM) assistance to produce scalable and realistic traffic scenarios within simulation platforms. The framework advances the state of the art in two ways: (i) it introduces a hierarchical driver model that represents diverse driving style traits, and (ii) it develops a Perception-Mediated Behavior Influence strategy, where LLMs guide perception to indirectly shape driver actions. Experiments reveal that embedding HDSim into simulation improves detection of safety-critical failures in self-driving systems by up to 68% and yields realism-consistent accident interpretability.
CannyEdit: Selective Canny Control and Dual-Prompt Guidance for Training-Free Image Editing
Aug 09, 2025Recent advances in text-to-image (T2I) models have enabled training-free regional image editing by leveraging the generative priors of foundation models. However, existing methods struggle to balance text adherence in edited regions, context fidelity in unedited areas, and seamless integration of edits. We introduce CannyEdit, a novel training-free framework that addresses these challenges through two key innovations: (1) Selective Canny Control, which masks the structural guidance of Canny ControlNet in user-specified editable regions while strictly preserving details of the source images in unedited areas via inversion-phase ControlNet information retention. This enables precise, text-driven edits without compromising contextual integrity. (2) Dual-Prompt Guidance, which combines local prompts for object-specific edits with a global target prompt to maintain coherent scene interactions. On real-world image editing tasks (addition, replacement, removal), CannyEdit outperforms prior methods like KV-Edit, achieving a 2.93 to 10.49 percent improvement in the balance of text adherence and context fidelity. In terms of editing seamlessness, user studies reveal only 49.2 percent of general users and 42.0 percent of AIGC experts identified CannyEdit's results as AI-edited when paired with real images without edits, versus 76.08 to 89.09 percent for competitor methods.
3D-MoRe: Unified Modal-Contextual Reasoning for Embodied Question Answering
Jul 16, 2025
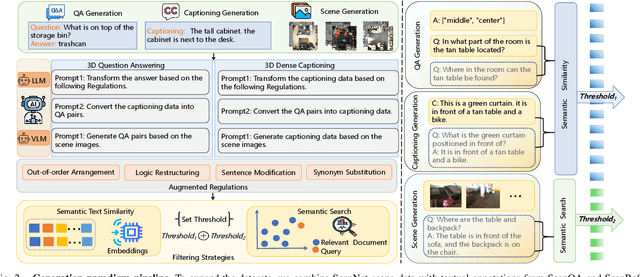


With the growing need for diverse and scalable data in indoor scene tasks, such as question answering and dense captioning, we propose 3D-MoRe, a novel paradigm designed to generate large-scale 3D-language datasets by leveraging the strengths of foundational models. The framework integrates key components, including multi-modal embedding, cross-modal interaction, and a language model decoder, to process natural language instructions and 3D scene data. This approach facilitates enhanced reasoning and response generation in complex 3D environments. Using the ScanNet 3D scene dataset, along with text annotations from ScanQA and ScanRefer, 3D-MoRe generates 62,000 question-answer (QA) pairs and 73,000 object descriptions across 1,513 scenes. We also employ various data augmentation techniques and implement semantic filtering to ensure high-quality data. Experiments on ScanQA demonstrate that 3D-MoRe significantly outperforms state-of-the-art baselines, with the CIDEr score improving by 2.15\%. Similarly, on ScanRefer, our approach achieves a notable increase in CIDEr@0.5 by 1.84\%, highlighting its effectiveness in both tasks. Our code and generated datasets will be publicly released to benefit the community, and both can be accessed on the https://3D-MoRe.github.io.
Adaptive Interactive Navigation of Quadruped Robots using Large Language Models
Mar 29, 2025
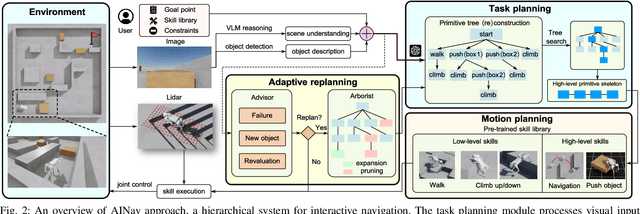
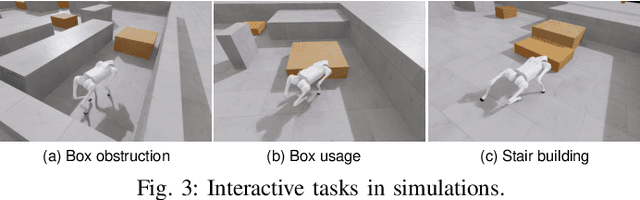
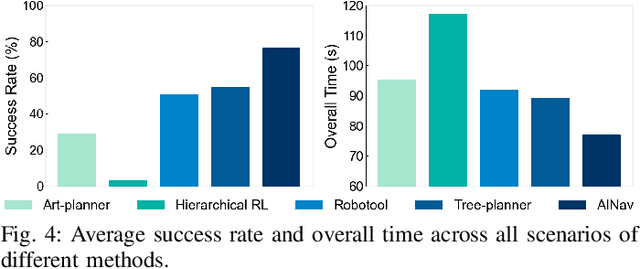
Robotic navigation in complex environments remains a critical research challenge. Traditional navigation methods focus on optimal trajectory generation within free space, struggling in environments lacking viable paths to the goal, such as disaster zones or cluttered warehouses. To address this gap, we propose an adaptive interactive navigation approach that proactively interacts with environments to create feasible paths to reach originally unavailable goals. Specifically, we present a primitive tree for task planning with large language models (LLMs), facilitating effective reasoning to determine interaction objects and sequences. To ensure robust subtask execution, we adopt reinforcement learning to pre-train a comprehensive skill library containing versatile locomotion and interaction behaviors for motion planning. Furthermore, we introduce an adaptive replanning method featuring two LLM-based modules: an advisor serving as a flexible replanning trigger and an arborist for autonomous plan adjustment. Integrated with the tree structure, the replanning mechanism allows for convenient node addition and pruning, enabling rapid plan modification in unknown environments. Comprehensive simulations and experiments have demonstrated our method's effectiveness and adaptivity in diverse scenarios. The supplementary video is available at page: https://youtu.be/W5ttPnSap2g.
Learning Effective Dynamics across Spatio-Temporal Scales of Complex Flows
Feb 11, 2025Modeling and simulation of complex fluid flows with dynamics that span multiple spatio-temporal scales is a fundamental challenge in many scientific and engineering domains. Full-scale resolving simulations for systems such as highly turbulent flows are not feasible in the foreseeable future, and reduced-order models must capture dynamics that involve interactions across scales. In the present work, we propose a novel framework, Graph-based Learning of Effective Dynamics (Graph-LED), that leverages graph neural networks (GNNs), as well as an attention-based autoregressive model, to extract the effective dynamics from a small amount of simulation data. GNNs represent flow fields on unstructured meshes as graphs and effectively handle complex geometries and non-uniform grids. The proposed method combines a GNN based, dimensionality reduction for variable-size unstructured meshes with an autoregressive temporal attention model that can learn temporal dependencies automatically. We evaluated the proposed approach on a suite of fluid dynamics problems, including flow past a cylinder and flow over a backward-facing step over a range of Reynolds numbers. The results demonstrate robust and effective forecasting of spatio-temporal physics; in the case of the flow past a cylinder, both small-scale effects that occur close to the cylinder as well as its wake are accurately captured.
Progressive Boundary Guided Anomaly Synthesis for Industrial Anomaly Detection
Dec 23, 2024



Unsupervised anomaly detection methods can identify surface defects in industrial images by leveraging only normal samples for training. Due to the risk of overfitting when learning from a single class, anomaly synthesis strategies are introduced to enhance detection capability by generating artificial anomalies. However, existing strategies heavily rely on anomalous textures from auxiliary datasets. Moreover, their limitations in the coverage and directionality of anomaly synthesis may result in a failure to capture useful information and lead to significant redundancy. To address these issues, we propose a novel Progressive Boundary-guided Anomaly Synthesis (PBAS) strategy, which can directionally synthesize crucial feature-level anomalies without auxiliary textures. It consists of three core components: Approximate Boundary Learning (ABL), Anomaly Feature Synthesis (AFS), and Refined Boundary Optimization (RBO). To make the distribution of normal samples more compact, ABL first learns an approximate decision boundary by center constraint, which improves the center initialization through feature alignment. AFS then directionally synthesizes anomalies with more flexible scales guided by the hypersphere distribution of normal features. Since the boundary is so loose that it may contain real anomalies, RBO refines the decision boundary through the binary classification of artificial anomalies and normal features. Experimental results show that our method achieves state-of-the-art performance and the fastest detection speed on three widely used industrial datasets, including MVTec AD, VisA, and MPDD. The code will be available at: https://github.com/cqylunlun/PBAS.