 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIG3D: Marrying Gaussian Splatting with Deformable Transformer for Single Image 3D Reconstruction
Paper and Code
Apr 25, 2024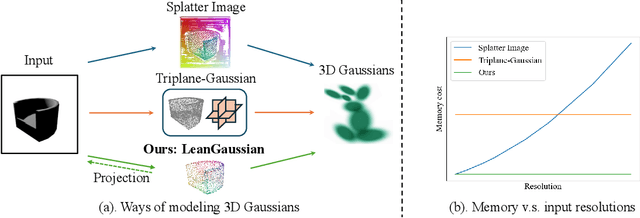

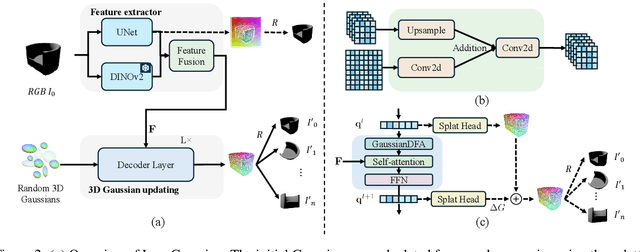

In this paper, we study the problem of 3D reconstruction from a single-view RGB image and propose a novel approach called DIG3D for 3D object reconstruction and novel view synthesis. Our method utilizes an encoder-decoder framework which generates 3D Gaussians in decoder with the guidance of depth-aware image features from encoder. In particular, we introduce the use of deformable transformer, allowing efficient and effective decoding through 3D reference point and multi-layer refinement adaptations. By harnessing the benefits of 3D Gaussians, our approach offers an efficient and accurate solution for 3D reconstruction from single-view images. We evaluate our method on the ShapeNet SRN dataset, getting PSNR of 24.21 and 24.98 in car and chair dataset, respectively. The result outperforming the recent method by around 2.25%, demonstrating the effectiveness of our method in achieving superior results.