 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Interactive Navigation of Quadruped Robots using Large Language Models
Mar 29, 2025
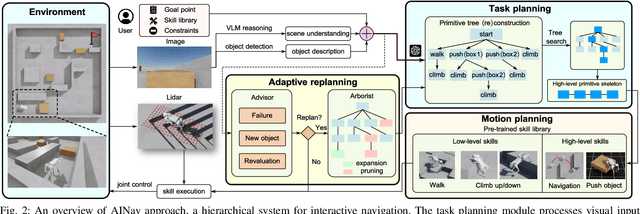
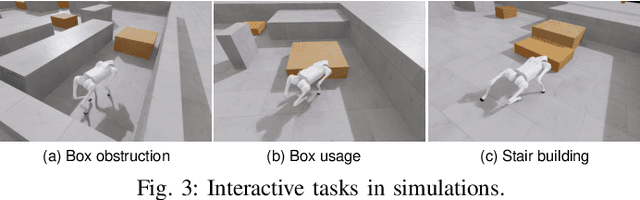
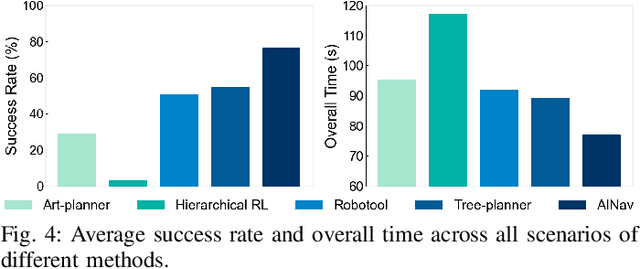
Robotic navigation in complex environments remains a critical research challenge. Traditional navigation methods focus on optimal trajectory generation within free space, struggling in environments lacking viable paths to the goal, such as disaster zones or cluttered warehouses. To address this gap, we propose an adaptive interactive navigation approach that proactively interacts with environments to create feasible paths to reach originally unavailable goals. Specifically, we present a primitive tree for task planning with large language models (LLMs), facilitating effective reasoning to determine interaction objects and sequences. To ensure robust subtask execution, we adopt reinforcement learning to pre-train a comprehensive skill library containing versatile locomotion and interaction behaviors for motion planning. Furthermore, we introduce an adaptive replanning method featuring two LLM-based modules: an advisor serving as a flexible replanning trigger and an arborist for autonomous plan adjustment. Integrated with the tree structure, the replanning mechanism allows for convenient node addition and pruning, enabling rapid plan modification in unknown environments. Comprehensive simulations and experiments have demonstrated our method's effectiveness and adaptivity in diverse scenarios. The supplementary video is available at page: https://youtu.be/W5ttPnSap2g.
Fuzzy Logic Guided Reward Function Variation: An Oracle for Testing Reinforcement Learning Programs
Jun 28, 2024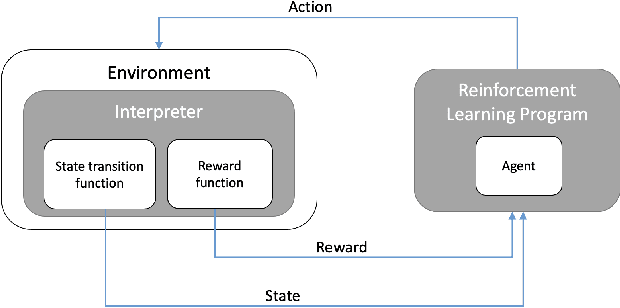

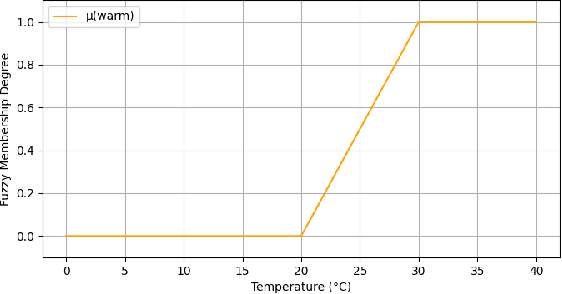
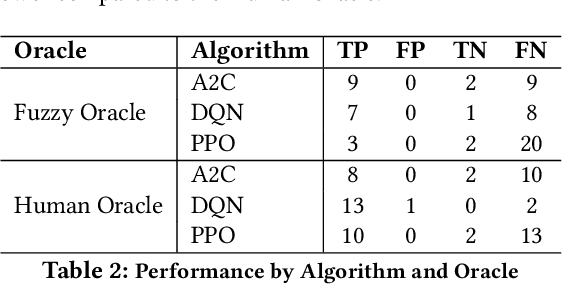
Reinforcement Learning (RL) has gained significant attention across various domains. However, the increasing complexity of RL programs presents testing challenges, particularly the oracle problem: defining the correctness of the RL program. Conventional human oracles struggle to cope with the complexity, leading to inefficiencies and potential unreliability in RL testing. To alleviate this problem, we propose an automated oracle approach that leverages RL properties using fuzzy logic. Our oracle quantifies an agent's behavioral compliance with reward policies and analyzes its trend over training episodes. It labels an RL program as "Buggy" if the compliance trend violates expectations derived from RL characteristics. We evaluate our oracle on RL programs with varying complexities and compare it with human oracles. Results show that while human oracles perform well in simpler testing scenarios, our fuzzy oracle demonstrates superior performance in complex environments. The proposed approach shows promise in addressing the oracle problem for RL testing, particularly in complex cases where manual testing falls short. It offers a potential solution to improve the efficiency, reliability, and scalability of RL program testing. This research takes a step towards automated testing of RL programs and highlights the potential of fuzzy logic-based oracles in tackling the oracle problem.