 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-platform Product Matching Based on Entity Alignment of Knowledge Graph with RAEA model
Dec 08, 2025Product matching aims to identify identical or similar products sold on different platforms. By building knowledge graphs (KGs), the product matching problem can be converted to the Entity Alignment (EA) task, which aims to discover the equivalent entities from diverse KGs. The existing EA methods inadequately utilize both attribute triples and relation triples simultaneously, especially the interactions between them. This paper introduces a two-stage pipeline consisting of rough filter and fine filter to match products from eBay and Amazon. For fine filtering, a new framework for Entity Alignment, Relation-aware and Attribute-aware Graph Attention Networks for Entity Alignment (RAEA), is employed. RAEA focuses on the interactions between attribute triples and relation triples, where the entity representation aggregates the alignment signals from attributes and relations with Attribute-aware Entity Encoder and Relation-aware Graph Attention Networks. The experimental results indicate that the RAEA model achieves significant improvements over 12 baselines on EA task in the cross-lingual dataset DBP15K (6.59% on average Hits@1) and delivers competitive results in the monolingual dataset DWY100K. The source code for experiments on DBP15K and DWY100K is available at github (https://github.com/Mockingjay-liu/RAEA-model-for-Entity-Alignment).
* 10 pages, 5 figures, published on World Wide Web
DINO-X: A Unified Vision Model for Open-World Object Detection and Understanding
Nov 21, 2024



In this paper, we introduce DINO-X, which is a unified object-centric vision model developed by IDEA Research with the best open-world object detection performance to date. DINO-X employs the same Transformer-based encoder-decoder architecture as Grounding DINO 1.5 to pursue an object-level representation for open-world object understanding. To make long-tailed object detection easy, DINO-X extends its input options to support text prompt, visual prompt, and customized prompt. With such flexible prompt options, we develop a universal object prompt to support prompt-free open-world detection, making it possible to detect anything in an image without requiring users to provide any prompt. To enhance the model's core grounding capability, we have constructed a large-scale dataset with over 100 million high-quality grounding samples, referred to as Grounding-100M, for advancing the model's open-vocabulary detection performance. Pre-training on such a large-scale grounding dataset leads to a foundational object-level representation, which enables DINO-X to integrate multiple perception heads to simultaneously support multiple object perception and understanding tasks, including detection, segmentation, pose estimation, object captioning, object-based QA, etc. Experimental results demonstrate the superior performance of DINO-X. Specifically, the DINO-X Pro model achieves 56.0 AP, 59.8 AP, and 52.4 AP on the COCO, LVIS-minival, and LVIS-val zero-shot object detection benchmarks, respectively. Notably, it scores 63.3 AP and 56.5 AP on the rare classes of LVIS-minival and LVIS-val benchmarks, both improving the previous SOTA performance by 5.8 AP. Such a result underscores its significantly improved capacity for recognizing long-tailed objects.
SymPoint Revolutionized: Boosting Panoptic Symbol Spotting with Layer Feature Enhancement
Jul 02, 2024SymPoint is an initial attempt that utilizes point set representation to solve the panoptic symbol spotting task on CAD drawing. Despite its considerable success, it overlooks graphical layer information and suffers from prohibitively slow training convergence. To tackle this issue, we introduce SymPoint-V2, a robust and efficient solution featuring novel, streamlined designs that overcome these limitations. In particular, we first propose a Layer Feature-Enhanced module (LFE) to encode the graphical layer information into the primitive feature, which significantly boosts the performance. We also design a Position-Guided Training (PGT) method to make it easier to learn, which accelerates the convergence of the model in the early stages and further promotes performance. Extensive experiments show that our model achieves better performance and faster convergence than its predecessor SymPoint on the public benchmark. Our code and trained models are available at https://github.com/nicehuster/SymPointV2.
Grounding DINO 1.5: Advance the "Edge" of Open-Set Object Detection
May 16, 2024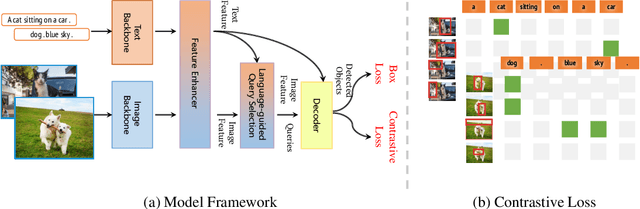
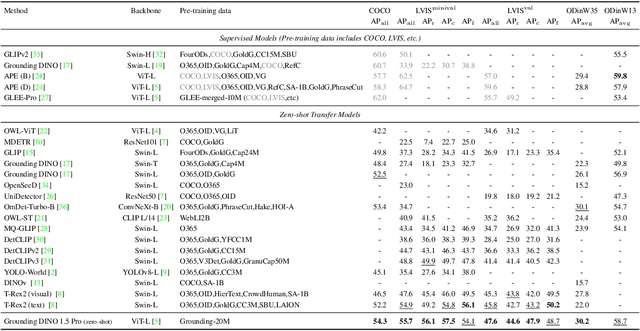
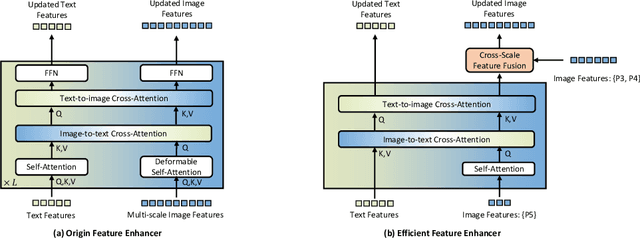

This paper introduces Grounding DINO 1.5, a suite of advanced open-set object detection models developed by IDEA Research, which aims to advance the "Edge" of open-set object detection. The suite encompasses two models: Grounding DINO 1.5 Pro, a high-performance model designed for stronger generalization capability across a wide range of scenarios, and Grounding DINO 1.5 Edge, an efficient model optimized for faster speed demanded in many applications requiring edge deployment. The Grounding DINO 1.5 Pro model advances its predecessor by scaling up the model architecture, integrating an enhanced vision backbone, and expanding the training dataset to over 20 million images with grounding annotations, thereby achieving a richer semantic understanding. The Grounding DINO 1.5 Edge model, while designed for efficiency with reduced feature scales, maintains robust detection capabilities by being trained on the same comprehensive dataset. Empirical results demonstrate the effectiveness of Grounding DINO 1.5, with the Grounding DINO 1.5 Pro model attaining a 54.3 AP on the COCO detection benchmark and a 55.7 AP on the LVIS-minival zero-shot transfer benchmark, setting new records for open-set object detection. Furthermore, the Grounding DINO 1.5 Edge model, when optimized with TensorRT, achieves a speed of 75.2 FPS while attaining a zero-shot performance of 36.2 AP on the LVIS-minival benchmark, making it more suitable for edge computing scenarios. Model examples and demos with API will be released at https://github.com/IDEA-Research/Grounding-DINO-1.5-API
Symbol as Points: Panoptic Symbol Spotting via Point-based Representation
Jan 19, 2024This work studies the problem of panoptic symbol spotting, which is to spot and parse both countable object instances (windows, doors, tables, etc.) and uncountable stuff (wall, railing, etc.) from computer-aided design (CAD) drawings. Existing methods typically involve either rasterizing the vector graphics into images and using image-based methods for symbol spotting, or directly building graphs and using graph neural networks for symbol recognition. In this paper, we take a different approach, which treats graphic primitives as a set of 2D points that are locally connected and use point cloud segmentation methods to tackle it. Specifically, we utilize a point transformer to extract the primitive features and append a mask2former-like spotting head to predict the final output. To better use the local connection information of primitives and enhance their discriminability, we further propose the attention with connection module (ACM) and contrastive connection learning scheme (CCL). Finally, we propose a KNN interpolation mechanism for the mask attention module of the spotting head to better handle primitive mask downsampling, which is primitive-level in contrast to pixel-level for the image. Our approach, named SymPoint, is simple yet effective, outperforming recent state-of-the-art method GAT-CADNet by an absolute increase of 9.6% PQ and 10.4% RQ on the FloorPlanCAD dataset. The source code and models will be available at https://github.com/nicehuster/SymPoint.
tSF: Transformer-based Semantic Filter for Few-Shot Learning
Nov 02, 2022Few-Shot Learning (FSL) alleviates the data shortage challenge via embedding discriminative target-aware features among plenty seen (base) and few unseen (novel) labeled samples. Most feature embedding modules in recent FSL methods are specially designed for corresponding learning tasks (e.g., classification, segmentation, and object detection), which limits the utility of embedding features. To this end, we propose a light and universal module named transformer-based Semantic Filter (tSF), which can be applied for different FSL tasks. The proposed tSF redesigns the inputs of a transformer-based structure by a semantic filter, which not only embeds the knowledge from whole base set to novel set but also filters semantic features for target category. Furthermore, the parameters of tSF is equal to half of a standard transformer block (less than 1M). In the experiments, our tSF is able to boost the performances in different classic few-shot learning tasks (about 2% improvement), especially outperforms the state-of-the-arts on multiple benchmark datasets in few-shot classification task.
Contrastive Learning Approach for Semi-Supervised Seismic Facies Identification Using High-Confidence Representations
Oct 12, 2022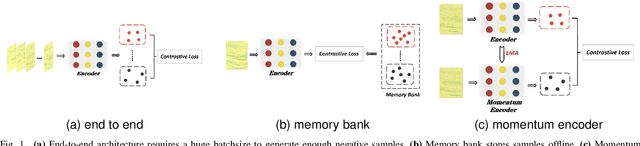
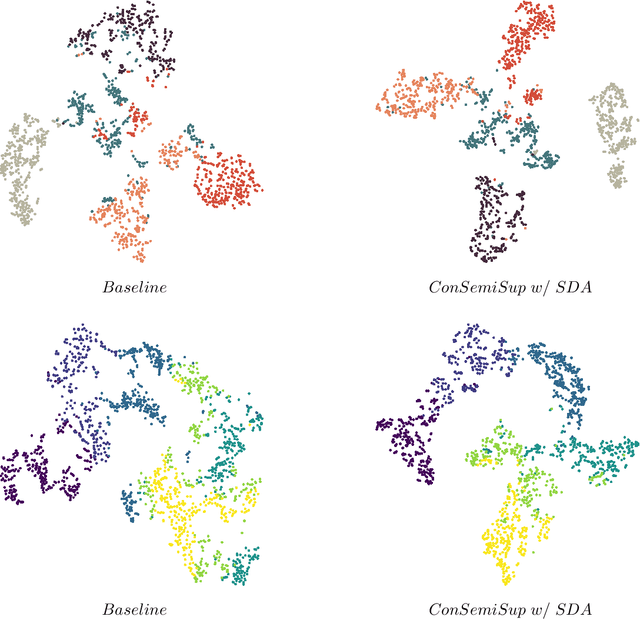
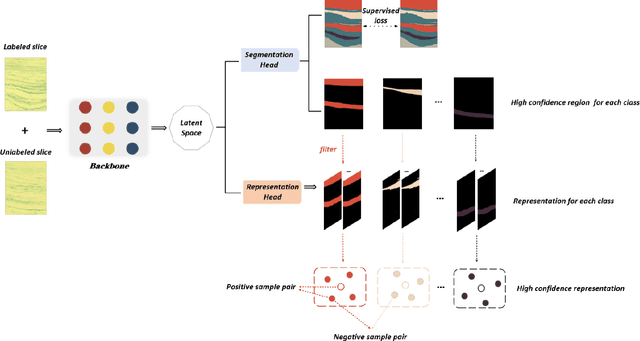
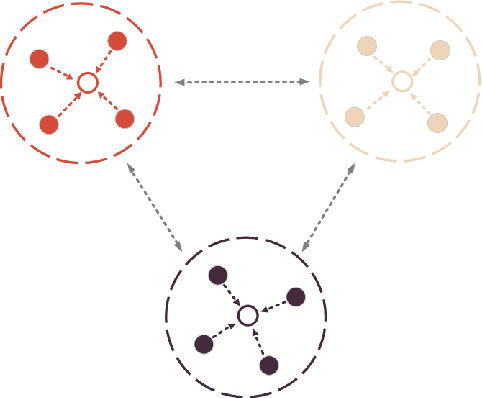
The manual seismic facies annotation relies heavily on the experience of seismic interpreters, and the distribution of seismic facies in adjacent locations is very similar, which means that much of the labeling is costly repetitive work. However, we found that training the model with only a few evenly sampled labeled slices still suffers from severe classification confusion, that is, misidentifying one class of seismic facies as another. To address this issue, we propose a semi-supervised seismic facies identification method using features from unlabeled data for contrastive learning. We sample features in regions with high identification confidence, and use an pixel-level instance discrimination task to narrow the intra-class distance and increase the inter-class distance. Instance discrimination encourages the latent space to produce more distinguishable decision boundaries and reduces the bias in the features of the same class. Our method only needs to extend one branch to compute the contrastive loss without extensive changes to the network structure. We have conducted experiments on two public seismic surveys, SEAM AI and Netherlands F3, and the proposed model achieves an IOU score of more than 90 using only 1% of the annotations in the F3 survey.
nVFNet-RDC: Replay and Non-Local Distillation Collaboration for Continual Object Detection
Sep 08, 2022Continual Learning (CL) focuses on developing algorithms with the ability to adapt to new environments and learn new skills. This very challenging task has generated a lot of interest in recent years, with new solutions appearing rapidly. In this paper, we propose a nVFNet-RDC approach for continual object detection. Our nVFNet-RDC consists of teacher-student models, and adopts replay and feature distillation strategies. As the 1st place solutions, we achieve 55.94% and 54.65% average mAP on the 3rd CLVision Challenge Track 2 and Track 3, respectively.
Yes-Net: An effective Detector Based on Global Information
Jun 30, 2017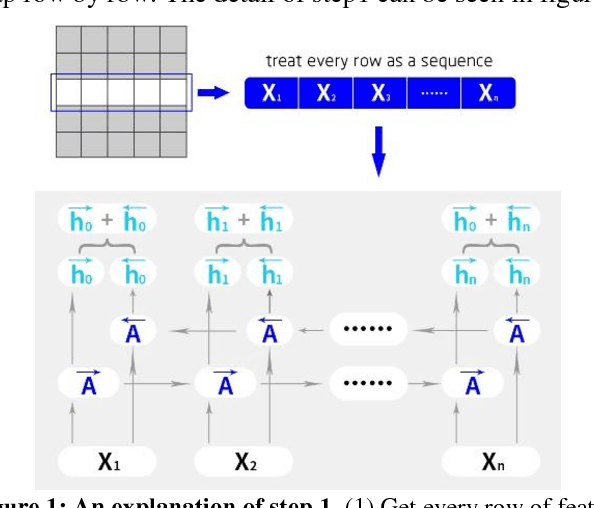
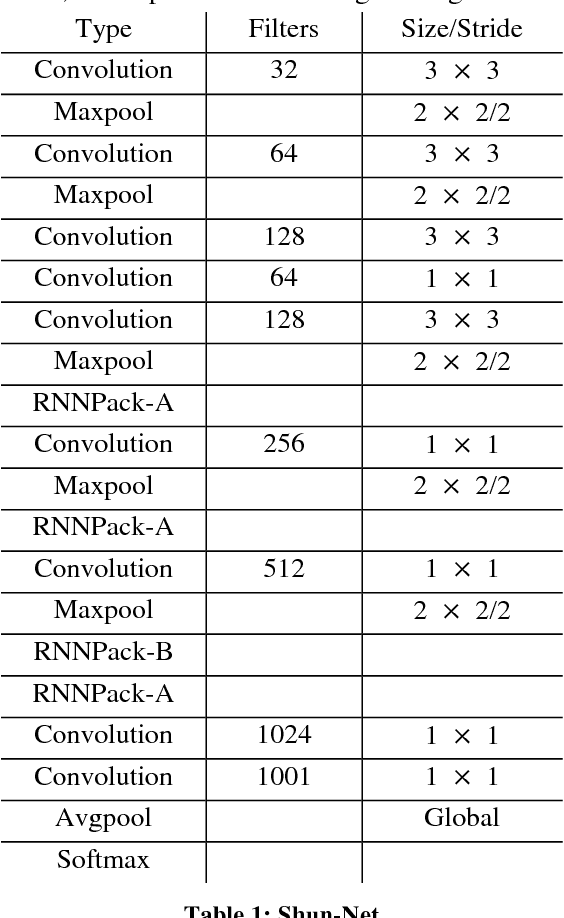
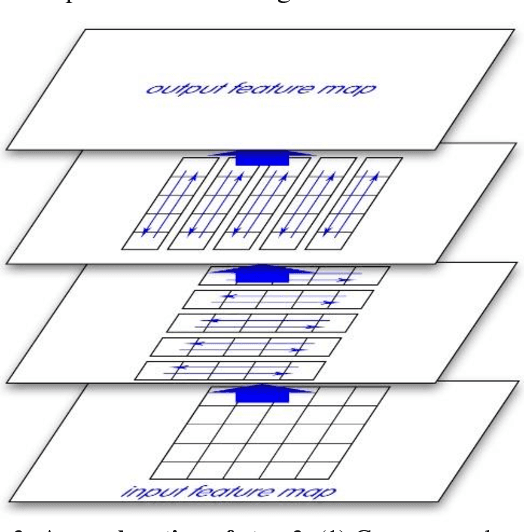
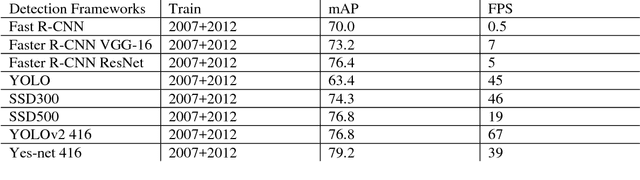
This paper introduces a new real-time object detection approach named Yes-Net. It realizes the prediction of bounding boxes and class via single neural network like YOLOv2 and SSD, but owns more efficient and outstanding features. It combines local information with global information by adding the RNN architecture as a packed unit in CNN model to form the basic feature extractor. Independent anchor boxes coming from full-dimension k-means is also applied in Yes-Net, it brings better average IOU than grid anchor box. In addition, instead of NMS, Yes-Net uses RNN as a filter to get the final boxes, which is more efficient. For 416 x 416 input, Yes-Net achieves 79.2% mAP on VOC2007 test at 39 FPS on an Nvidia Titan X Pascal.