 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Short-Term Sample Distillation
Mar 02, 2020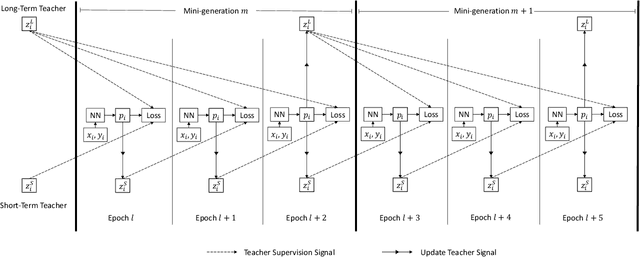
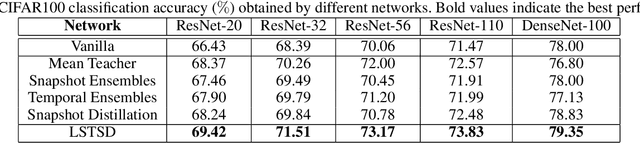
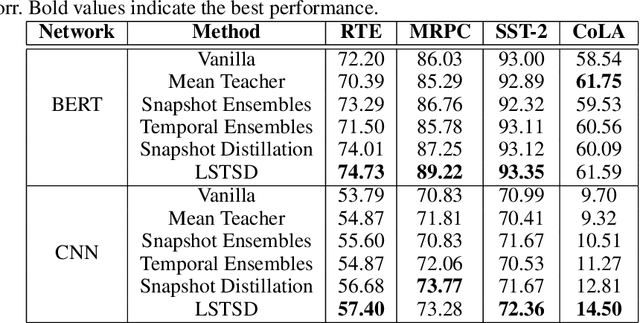
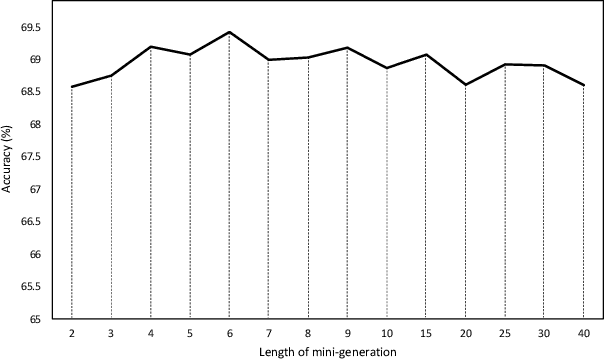
In the past decade, there has been substantial progress at training increasingly deep neural networks. Recent advances within the teacher--student training paradigm have established that information about past training updates show promise as a source of guidance during subsequent training steps. Based on this notion, in this paper, we propose Long Short-Term Sample Distillation, a novel training policy that simultaneously leverages multiple phases of the previous training process to guide the later training updates to a neural network, while efficiently proceeding in just one single generation pass. With Long Short-Term Sample Distillation, the supervision signal for each sample is decomposed into two parts: a long-term signal and a short-term one. The long-term teacher draws on snapshots from several epochs ago in order to provide steadfast guidance and to guarantee teacher--student differences, while the short-term one yields more up-to-date cues with the goal of enabling higher-quality updates. Moreover, the teachers for each sample are unique, such that, overall, the model learns from a very diverse set of teachers. Comprehensive experimental results across a range of vision and NLP tasks demonstrate the effectiveness of this new training method.
Yes-Net: An effective Detector Based on Global Information
Jun 30, 2017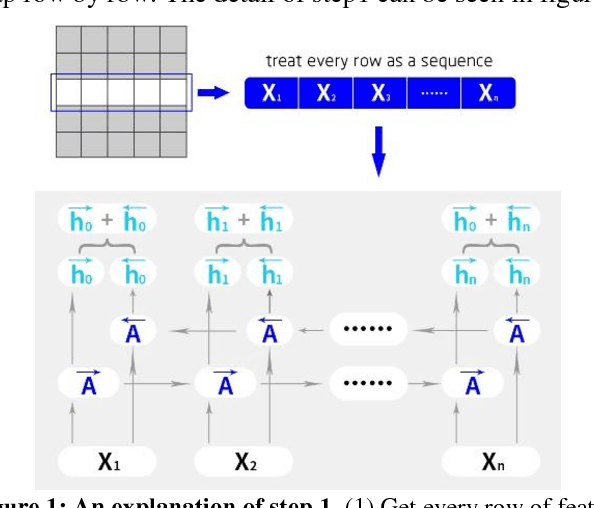
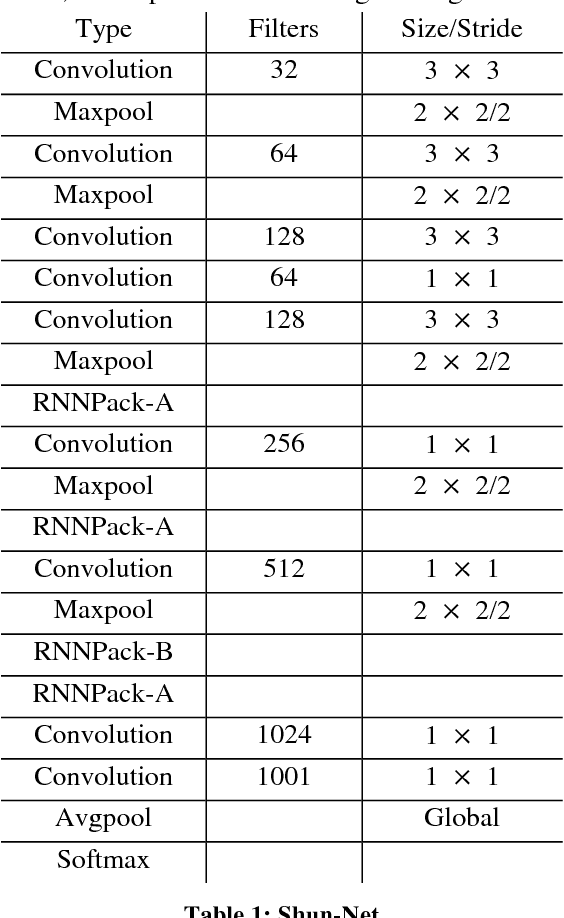
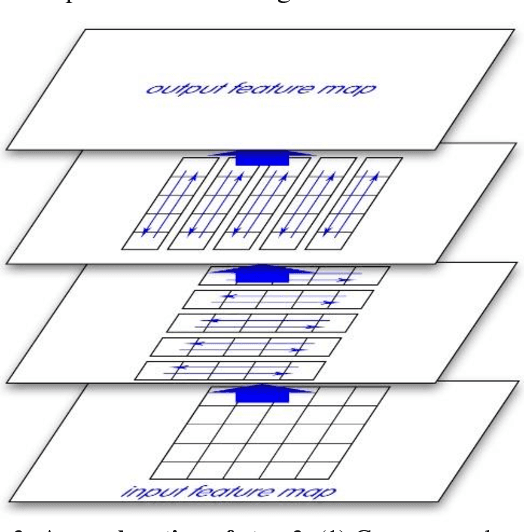
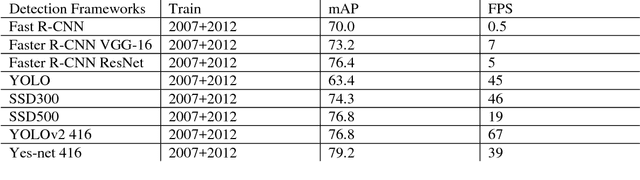
This paper introduces a new real-time object detection approach named Yes-Net. It realizes the prediction of bounding boxes and class via single neural network like YOLOv2 and SSD, but owns more efficient and outstanding features. It combines local information with global information by adding the RNN architecture as a packed unit in CNN model to form the basic feature extractor. Independent anchor boxes coming from full-dimension k-means is also applied in Yes-Net, it brings better average IOU than grid anchor box. In addition, instead of NMS, Yes-Net uses RNN as a filter to get the final boxes, which is more efficient. For 416 x 416 input, Yes-Net achieves 79.2% mAP on VOC2007 test at 39 FPS on an Nvidia Titan X Pascal.