 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAKEM: Aligning Knowledge Base to Queries with Ensemble Model for Entity Recognition and Linking
Sep 13, 2023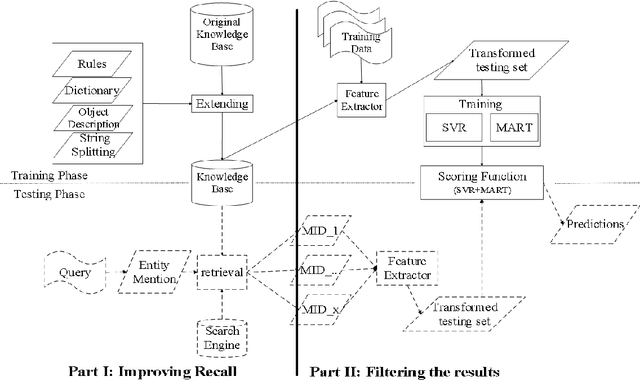

This paper presents a novel approach to address the Entity Recognition and Linking Challenge at NLPCC 2015. The task involves extracting named entity mentions from short search queries and linking them to entities within a reference Chinese knowledge base. To tackle this problem, we first expand the existing knowledge base and utilize external knowledge to identify candidate entities, thereby improving the recall rate. Next, we extract features from the candidate entities and utilize Support Vector Regression and Multiple Additive Regression Tree as scoring functions to filter the results. Additionally, we apply rules to further refine the results and enhance precision. Our method is computationally efficient and achieves an F1 score of 0.535.
Long Short-Term Sample Distillation
Mar 02, 2020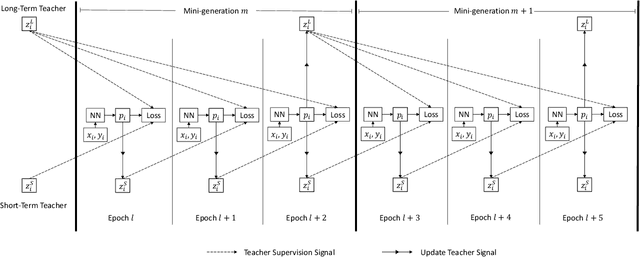
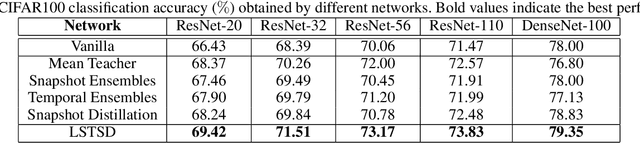
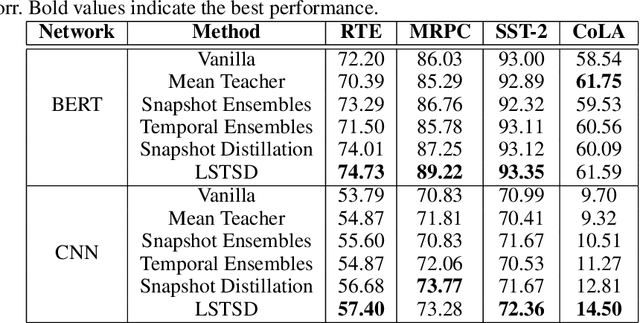
In the past decade, there has been substantial progress at training increasingly deep neural networks. Recent advances within the teacher--student training paradigm have established that information about past training updates show promise as a source of guidance during subsequent training steps. Based on this notion, in this paper, we propose Long Short-Term Sample Distillation, a novel training policy that simultaneously leverages multiple phases of the previous training process to guide the later training updates to a neural network, while efficiently proceeding in just one single generation pass. With Long Short-Term Sample Distillation, the supervision signal for each sample is decomposed into two parts: a long-term signal and a short-term one. The long-term teacher draws on snapshots from several epochs ago in order to provide steadfast guidance and to guarantee teacher--student differences, while the short-term one yields more up-to-date cues with the goal of enabling higher-quality updates. Moreover, the teachers for each sample are unique, such that, overall, the model learns from a very diverse set of teachers. Comprehensive experimental results across a range of vision and NLP tasks demonstrate the effectiveness of this new training method.