 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Sharp Eyes and Memory for VideoLLMs: Information-Aware Visual Token Pruning for Efficient and Reliable VideoLLM Reasoning
Nov 11, 2025Current Video Large Language Models (VideoLLMs) suffer from quadratic computational complexity and key-value cache scaling, due to their reliance on processing excessive redundant visual tokens. To address this problem, we propose SharpV, a minimalist and efficient method for adaptive pruning of visual tokens and KV cache. Different from most uniform compression approaches, SharpV dynamically adjusts pruning ratios based on spatial-temporal information. Remarkably, this adaptive mechanism occasionally achieves performance gains over dense models, offering a novel paradigm for adaptive pruning. During the KV cache pruning stage, based on observations of visual information degradation, SharpV prunes degraded visual features via a self-calibration manner, guided by similarity to original visual features. In this way, SharpV achieves hierarchical cache pruning from the perspective of information bottleneck, offering a new insight into VideoLLMs' information flow. Experiments on multiple public benchmarks demonstrate the superiority of SharpV. Moreover, to the best of our knowledge, SharpV is notably the first two-stage pruning framework that operates without requiring access to exposed attention scores, ensuring full compatibility with hardware acceleration techniques like Flash Attention.
CEHA: A Dataset of Conflict Events in the Horn of Africa
Dec 18, 2024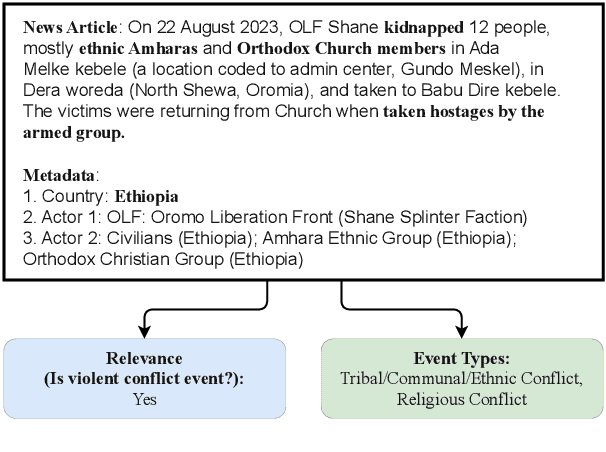


Natural Language Processing (NLP) of news articles can play an important role in understanding the dynamics and causes of violent conflict. Despite the availability of datasets categorizing various conflict events, the existing labels often do not cover all of the fine-grained violent conflict event types relevant to areas like the Horn of Africa. In this paper, we introduce a new benchmark dataset Conflict Events in the Horn of Africa region (CEHA) and propose a new task for identifying violent conflict events using online resources with this dataset. The dataset consists of 500 English event descriptions regarding conflict events in the Horn of Africa region with fine-grained event-type definitions that emphasize the cause of the conflict. This dataset categorizes the key types of conflict risk according to specific areas required by stakeholders in the Humanitarian-Peace-Development Nexus. Additionally, we conduct extensive experiments on two tasks supported by this dataset: Event-relevance Classification and Event-type Classification. Our baseline models demonstrate the challenging nature of these tasks and the usefulness of our dataset for model evaluations in low-resource settings with limited number of training data.
From Prohibition to Adoption: How Hong Kong Universities Are Navigating ChatGPT in Academic Workflows
Oct 02, 2024This paper aims at comparing the time when Hong Kong universities used to ban ChatGPT to the current periods where it has become integrated in the academic processes. Bolted by concerns of integrity and ethical issues in technologies, institutions have adapted by moving towards the center adopting AI literacy and responsibility policies. This study examines new paradigms which have been developed to help implement these positives while preventing negative effects on academia. Keywords: ChatGPT, Academic Integrity, AI Literacy, Ethical AI Use, Generative AI in Education, University Policy, AI Integration in Academia, Higher Education and Technology
AKEM: Aligning Knowledge Base to Queries with Ensemble Model for Entity Recognition and Linking
Sep 13, 2023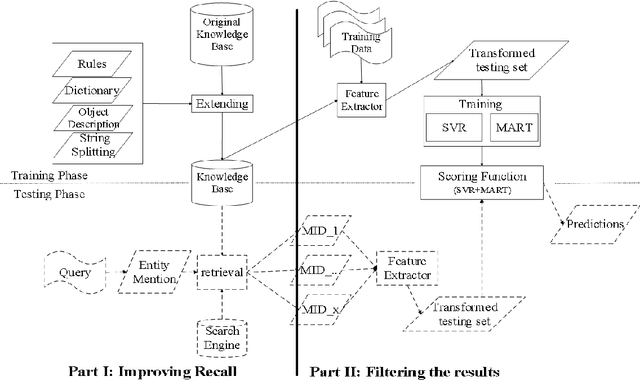

This paper presents a novel approach to address the Entity Recognition and Linking Challenge at NLPCC 2015. The task involves extracting named entity mentions from short search queries and linking them to entities within a reference Chinese knowledge base. To tackle this problem, we first expand the existing knowledge base and utilize external knowledge to identify candidate entities, thereby improving the recall rate. Next, we extract features from the candidate entities and utilize Support Vector Regression and Multiple Additive Regression Tree as scoring functions to filter the results. Additionally, we apply rules to further refine the results and enhance precision. Our method is computationally efficient and achieves an F1 score of 0.535.
FATRER: Full-Attention Topic Regularizer for Accurate and Robust Conversational Emotion Recognition
Jul 23, 2023This paper concentrates on the understanding of interlocutors' emotions evoked in conversational utterances. Previous studies in this literature mainly focus on more accurate emotional predictions, while ignoring model robustness when the local context is corrupted by adversarial attacks. To maintain robustness while ensuring accuracy, we propose an emotion recognizer augmented by a full-attention topic regularizer, which enables an emotion-related global view when modeling the local context in a conversation. A joint topic modeling strategy is introduced to implement regularization from both representation and loss perspectives. To avoid over-regularization, we drop the constraints on prior distributions that exist in traditional topic modeling and perform probabilistic approximations based entirely on attention alignment. Experiments show that our models obtain more favorable results than state-of-the-art models, and gain convincing robustness under three types of adversarial attacks.
Event Extraction as Question Generation and Answering
Jul 10, 2023Recent work on Event Extraction has reframed the task as Question Answering (QA), with promising results. The advantage of this approach is that it addresses the error propagation issue found in traditional token-based classification approaches by directly predicting event arguments without extracting candidates first. However, the questions are typically based on fixed templates and they rarely leverage contextual information such as relevant arguments. In addition, prior QA-based approaches have difficulty handling cases where there are multiple arguments for the same role. In this paper, we propose QGA-EE, which enables a Question Generation (QG) model to generate questions that incorporate rich contextual information instead of using fixed templates. We also propose dynamic templates to assist the training of QG model. Experiments show that QGA-EE outperforms all prior single-task-based models on the ACE05 English dataset.
A New Task and Dataset on Detecting Attacks on Human Rights Defenders
Jun 30, 2023



The ability to conduct retrospective analyses of attacks on human rights defenders over time and by location is important for humanitarian organizations to better understand historical or ongoing human rights violations and thus better manage the global impact of such events. We hypothesize that NLP can support such efforts by quickly processing large collections of news articles to detect and summarize the characteristics of attacks on human rights defenders. To that end, we propose a new dataset for detecting Attacks on Human Rights Defenders (HRDsAttack) consisting of crowdsourced annotations on 500 online news articles. The annotations include fine-grained information about the type and location of the attacks, as well as information about the victim(s). We demonstrate the usefulness of the dataset by using it to train and evaluate baseline models on several sub-tasks to predict the annotated characteristics.
BUMP: A Benchmark of Unfaithful Minimal Pairs for Meta-Evaluation of Faithfulness Metrics
Dec 20, 2022
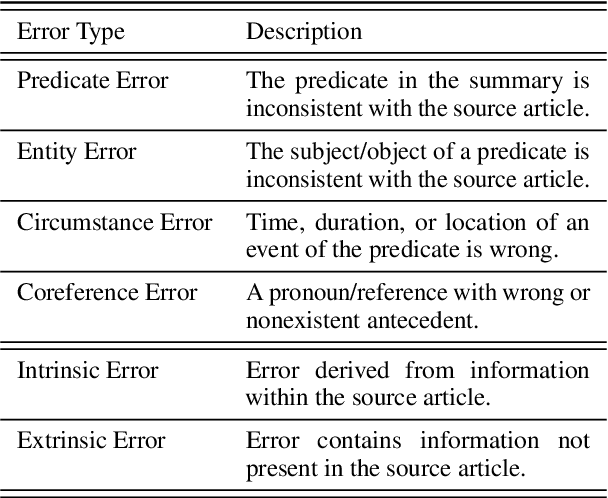
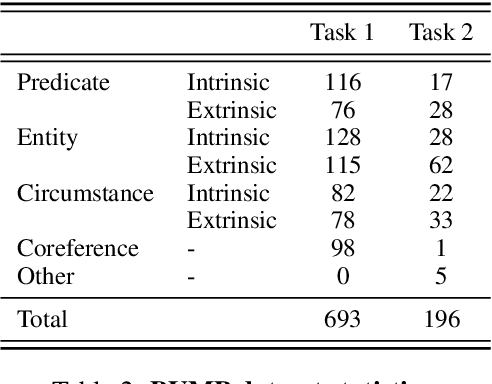

The proliferation of automatic faithfulness metrics for summarization has produced a need for benchmarks to evaluate them. While existing benchmarks measure the correlation with human judgements of faithfulness on model-generated summaries, they are insufficient for diagnosing whether metrics are: 1) consistent, i.e., decrease as errors are introduced into a summary, 2) effective on human-written texts, and 3) sensitive to different error types (as summaries can contain multiple errors). To address these needs, we present a benchmark of unfaithful minimal pairs (BUMP), a dataset of 889 human-written, minimally different summary pairs, where a single error (from an ontology of 7 types) is introduced to a summary from the CNN/DailyMail dataset to produce an unfaithful summary. We find BUMP complements existing benchmarks in a number of ways: 1) the summaries in BUMP are harder to discriminate and less probable under SOTA summarization models, 2) BUMP enables measuring the consistency of metrics, and reveals that the most discriminative metrics tend not to be the most consistent, 3) BUMP enables the measurement of metrics' performance on individual error types and highlights areas of weakness for future work.
Information-driven Path Planning for Hybrid Aerial Underwater Vehicles
Apr 08, 2022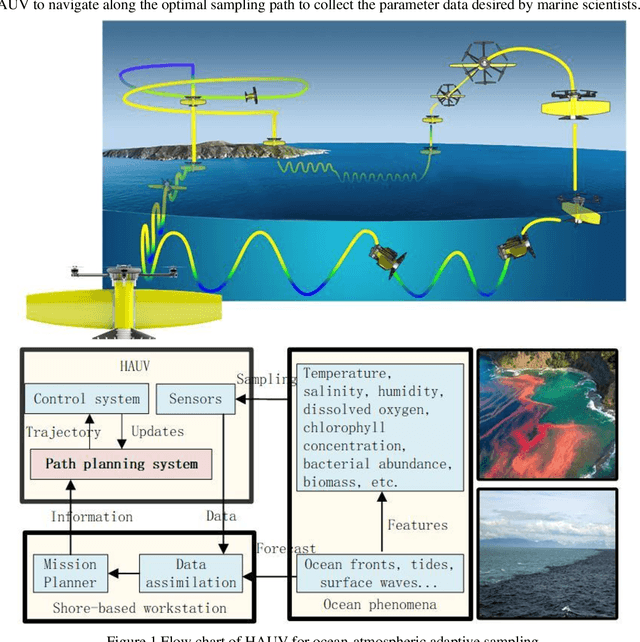
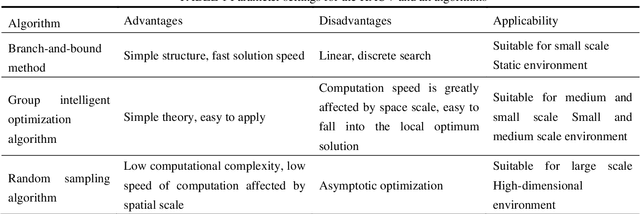

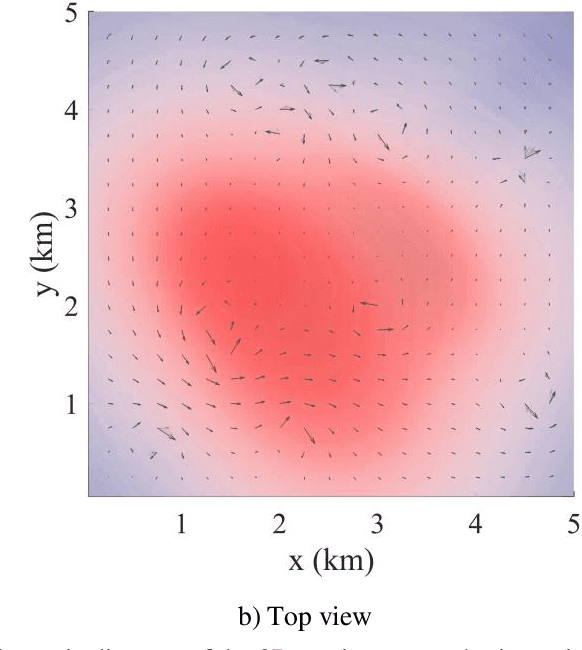
This paper presents a novel Rapidly-exploring Adaptive Sampling Tree (RAST) algorithm for the adaptive sampling mission of a hybrid aerial underwater vehicle (HAUV) in an air-sea 3D environment. This algorithm innovatively combines the tournament-based point selection sampling strategy, the information heuristic search process and the framework of Rapidly-exploring Random Tree (RRT) algorithm. Hence can guide the vehicle to the region of interest to scientists for sampling and generate a collision-free path for maximizing information collection by the HAUV under the constraints of environmental effects of currents or wind and limited budget. The simulation results show that the fast search adaptive sampling tree algorithm has higher optimization performance, faster solution speed and better stability than the Rapidly-exploring Information Gathering Tree (RIGT) algorithm and the particle swarm optimization (PSO) algorithm.