 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Retrieval Robustness of Large Language Models
May 28, 2025Retrieval-augmented generation (RAG) generally enhances large language models' (LLMs) ability to solve knowledge-intensive tasks. But RAG may also lead to performance degradation due to imperfect retrieval and the model's limited ability to leverage retrieved content. In this work, we evaluate the robustness of LLMs in practical RAG setups (henceforth retrieval robustness). We focus on three research questions: (1) whether RAG is always better than non-RAG; (2) whether more retrieved documents always lead to better performance; (3) and whether document orders impact results. To facilitate this study, we establish a benchmark of 1500 open-domain questions, each with retrieved documents from Wikipedia. We introduce three robustness metrics, each corresponds to one research question. Our comprehensive experiments, involving 11 LLMs and 3 prompting strategies, reveal that all of these LLMs exhibit surprisingly high retrieval robustness; nonetheless, different degrees of imperfect robustness hinders them from fully utilizing the benefits of RAG.
Verifiable Generation with Subsentence-Level Fine-Grained Citations
Jun 10, 2024
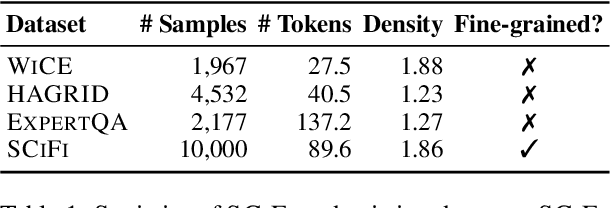

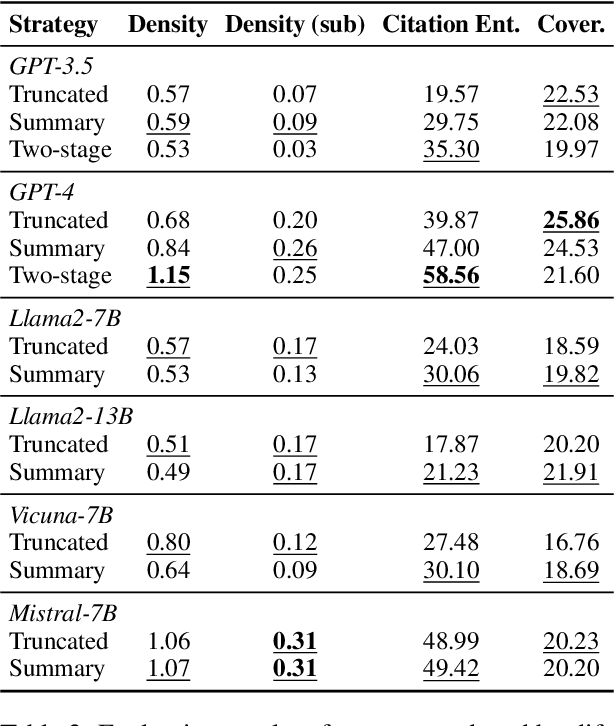
Verifiable generation requires large language models (LLMs) to cite source documents supporting their outputs, thereby improve output transparency and trustworthiness. Yet, previous work mainly targets the generation of sentence-level citations, lacking specificity about which parts of a sentence are backed by the cited sources. This work studies verifiable generation with subsentence-level fine-grained citations for more precise location of generated content supported by the cited sources. We first present a dataset, SCiFi, comprising 10K Wikipedia paragraphs with subsentence-level citations. Each paragraph is paired with a set of candidate source documents for citation and a query that triggers the generation of the paragraph content. On SCiFi, we evaluate the performance of state-of-the-art LLMs and strategies for processing long documents designed for these models. Our experiment results reveals key factors that could enhance the quality of citations, including the expansion of the source documents' context accessible to the models and the implementation of specialized model tuning.
AWESOME: GPU Memory-constrained Long Document Summarization using Memory Mechanism and Global Salient Content
May 24, 2023



Long document summarization systems are critical for domains with lengthy and jargonladen text, yet they present significant challenges to researchers and developers with limited computing resources. Existing solutions mainly focus on efficient attentions or divide-and-conquer strategies. The former reduces theoretical time complexity, but is still memory-heavy. The latter methods sacrifice global context, leading to uninformative and incoherent summaries. This work aims to leverage the memory-efficient nature of divide-and-conquer methods while preserving global context. Concretely, our framework AWESOME uses two novel mechanisms: (1) External memory mechanisms track previously encoded document segments and their corresponding summaries, to enhance global document understanding and summary coherence. (2) Global salient content is further identified beforehand to augment each document segment to support its summarization. Extensive experiments on diverse genres of text, including government reports, transcripts, scientific papers, and novels, show that AWESOME produces summaries with improved informativeness, faithfulness, and coherence than competitive baselines on longer documents, while having a similar or smaller GPU memory footprint.
BUMP: A Benchmark of Unfaithful Minimal Pairs for Meta-Evaluation of Faithfulness Metrics
Dec 20, 2022
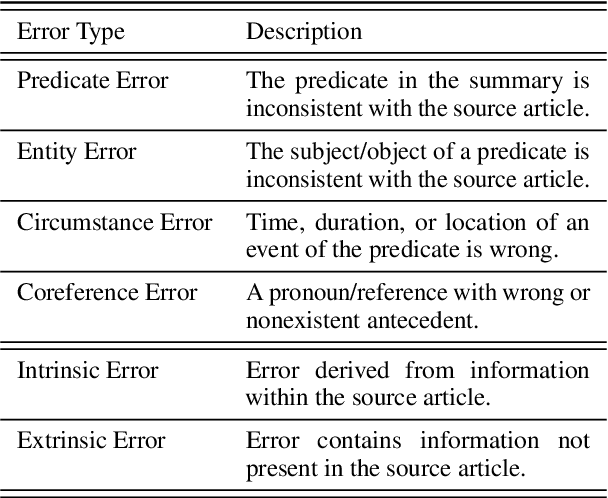
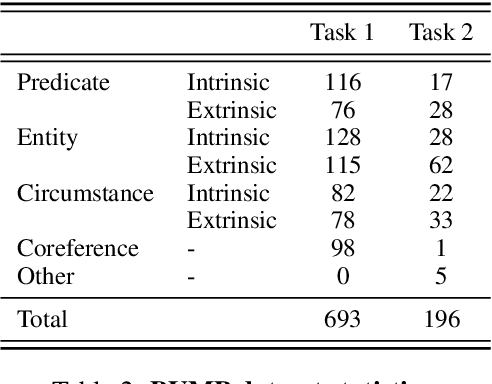

The proliferation of automatic faithfulness metrics for summarization has produced a need for benchmarks to evaluate them. While existing benchmarks measure the correlation with human judgements of faithfulness on model-generated summaries, they are insufficient for diagnosing whether metrics are: 1) consistent, i.e., decrease as errors are introduced into a summary, 2) effective on human-written texts, and 3) sensitive to different error types (as summaries can contain multiple errors). To address these needs, we present a benchmark of unfaithful minimal pairs (BUMP), a dataset of 889 human-written, minimally different summary pairs, where a single error (from an ontology of 7 types) is introduced to a summary from the CNN/DailyMail dataset to produce an unfaithful summary. We find BUMP complements existing benchmarks in a number of ways: 1) the summaries in BUMP are harder to discriminate and less probable under SOTA summarization models, 2) BUMP enables measuring the consistency of metrics, and reveals that the most discriminative metrics tend not to be the most consistent, 3) BUMP enables the measurement of metrics' performance on individual error types and highlights areas of weakness for future work.
Time-aware Prompting for Text Generation
Nov 03, 2022In this paper, we study the effects of incorporating timestamps, such as document creation dates, into generation systems. Two types of time-aware prompts are investigated: (1) textual prompts that encode document timestamps in natural language sentences; and (2) linear prompts that convert timestamps into continuous vectors. To explore extrapolation to future data points, we further introduce a new data-to-text generation dataset, TempWikiBio, containing more than 4 millions of chronologically ordered revisions of biographical articles from English Wikipedia, each paired with structured personal profiles. Through data-to-text generation on TempWikiBio, text-to-text generation on the content transfer dataset, and summarization on XSum, we show that linear prompts on encoder and textual prompts improve the generation quality on all datasets. Despite having less performance drop when testing on data drawn from a later time, linear prompts focus more on non-temporal information and are less sensitive to the given timestamps, according to human evaluations and sensitivity analyses. Meanwhile, textual prompts establish the association between the given timestamps and the output dates, yielding more factual temporal information in the output.
HIBRIDS: Attention with Hierarchical Biases for Structure-aware Long Document Summarization
Mar 21, 2022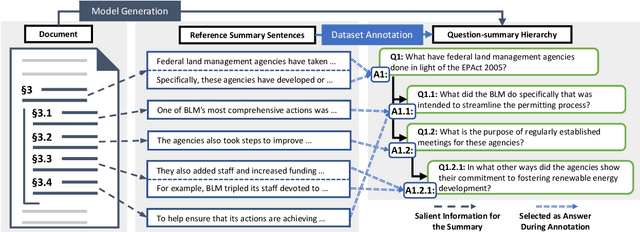

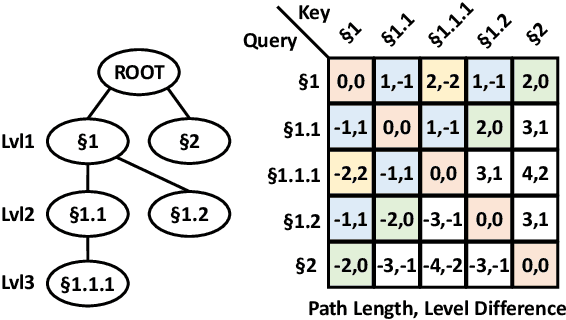

Document structure is critical for efficient information consumption. However, it is challenging to encode it efficiently into the modern Transformer architecture. In this work, we present HIBRIDS, which injects Hierarchical Biases foR Incorporating Document Structure into the calculation of attention scores. We further present a new task, hierarchical question-summary generation, for summarizing salient content in the source document into a hierarchy of questions and summaries, where each follow-up question inquires about the content of its parent question-summary pair. We also annotate a new dataset with 6,153 question-summary hierarchies labeled on long government reports. Experiment results show that our model produces better question-summary hierarchies than comparisons on both hierarchy quality and content coverage, a finding also echoed by human judges. Additionally, our model improves the generation of long-form summaries from lengthy government reports and Wikipedia articles, as measured by ROUGE scores.
CLIFF: Contrastive Learning for Improving Faithfulness and Factuality in Abstractive Summarization
Sep 19, 2021



We study generating abstractive summaries that are faithful and factually consistent with the given articles. A novel contrastive learning formulation is presented, which leverages both reference summaries, as positive training data, and automatically generated erroneous summaries, as negative training data, to train summarization systems that are better at distinguishing between them. We further design four types of strategies for creating negative samples, to resemble errors made commonly by two state-of-the-art models, BART and PEGASUS, found in our new human annotations of summary errors. Experiments on XSum and CNN/Daily Mail show that our contrastive learning framework is robust across datasets and models. It consistently produces more factual summaries than strong comparisons with post error correction, entailment-based reranking, and unlikelihood training, according to QA-based factuality evaluation. Human judges echo the observation and find that our model summaries correct more errors.
Controllable Open-ended Question Generation with A New Question Type Ontology
Jul 01, 2021

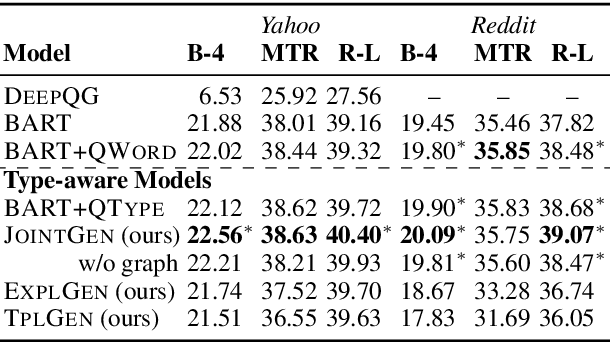

We investigate the less-explored task of generating open-ended questions that are typically answered by multiple sentences. We first define a new question type ontology which differentiates the nuanced nature of questions better than widely used question words. A new dataset with 4,959 questions is labeled based on the new ontology. We then propose a novel question type-aware question generation framework, augmented by a semantic graph representation, to jointly predict question focuses and produce the question. Based on this framework, we further use both exemplars and automatically generated templates to improve controllability and diversity. Experiments on two newly collected large-scale datasets show that our model improves question quality over competitive comparisons based on automatic metrics. Human judges also rate our model outputs highly in answerability, coverage of scope, and overall quality. Finally, our model variants with templates can produce questions with enhanced controllability and diversity.
Efficient Attentions for Long Document Summarization
Apr 11, 2021
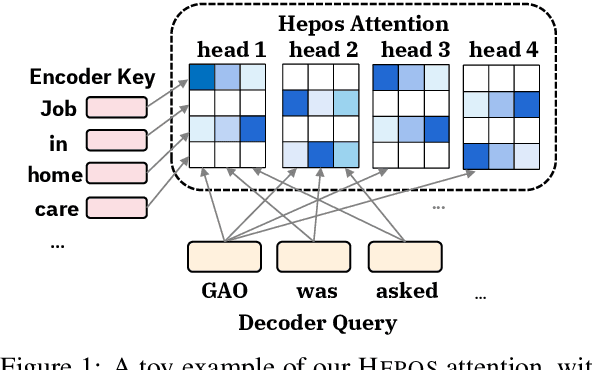


The quadratic computational and memory complexities of large Transformers have limited their scalability for long document summarization. In this paper, we propose Hepos, a novel efficient encoder-decoder attention with head-wise positional strides to effectively pinpoint salient information from the source. We further conduct a systematic study of existing efficient self-attentions. Combined with Hepos, we are able to process ten times more tokens than existing models that use full attentions. For evaluation, we present a new dataset, GovReport, with significantly longer documents and summaries. Results show that our models produce significantly higher ROUGE scores than competitive comparisons, including new state-of-the-art results on PubMed. Human evaluation also shows that our models generate more informative summaries with fewer unfaithful errors.
Attention Head Masking for Inference Time Content Selection in Abstractive Summarization
Apr 06, 2021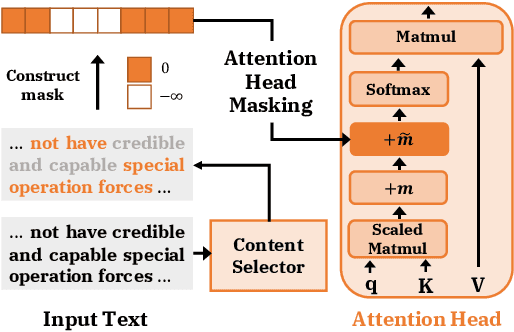

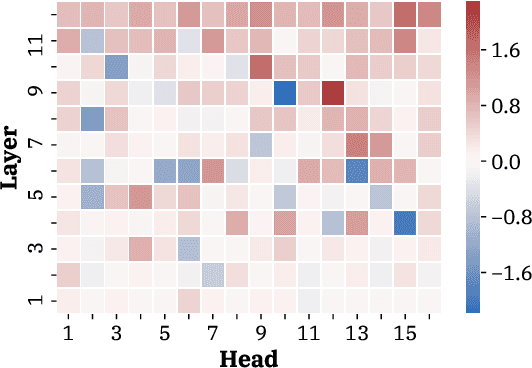

How can we effectively inform content selection in Transformer-based abstractive summarization models? In this work, we present a simple-yet-effective attention head masking technique, which is applied on encoder-decoder attentions to pinpoint salient content at inference time. Using attention head masking, we are able to reveal the relation between encoder-decoder attentions and content selection behaviors of summarization models. We then demonstrate its effectiveness on three document summarization datasets based on both in-domain and cross-domain settings. Importantly, our models outperform prior state-of-the-art models on CNN/Daily Mail and New York Times datasets. Moreover, our inference-time masking technique is also data-efficient, requiring only 20% of the training samples to outperform BART fine-tuned on the full CNN/DailyMail dataset.