 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Head Masking for Inference Time Content Selection in Abstractive Summarization
Paper and Code
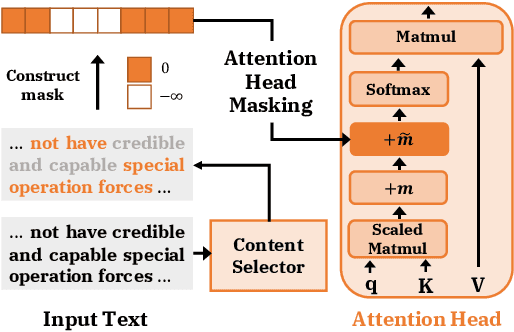


How can we effectively inform content selection in Transformer-based abstractive summarization models? In this work, we present a simple-yet-effective attention head masking technique, which is applied on encoder-decoder attentions to pinpoint salient content at inference time. Using attention head masking, we are able to reveal the relation between encoder-decoder attentions and content selection behaviors of summarization models. We then demonstrate its effectiveness on three document summarization datasets based on both in-domain and cross-domain settings. Importantly, our models outperform prior state-of-the-art models on CNN/Daily Mail and New York Times datasets. Moreover, our inference-time masking technique is also data-efficient, requiring only 20% of the training samples to outperform BART fine-tuned on the full CNN/DailyMail dataset.