 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFATRER: Full-Attention Topic Regularizer for Accurate and Robust Conversational Emotion Recognition
Jul 23, 2023This paper concentrates on the understanding of interlocutors' emotions evoked in conversational utterances. Previous studies in this literature mainly focus on more accurate emotional predictions, while ignoring model robustness when the local context is corrupted by adversarial attacks. To maintain robustness while ensuring accuracy, we propose an emotion recognizer augmented by a full-attention topic regularizer, which enables an emotion-related global view when modeling the local context in a conversation. A joint topic modeling strategy is introduced to implement regularization from both representation and loss perspectives. To avoid over-regularization, we drop the constraints on prior distributions that exist in traditional topic modeling and perform probabilistic approximations based entirely on attention alignment. Experiments show that our models obtain more favorable results than state-of-the-art models, and gain convincing robustness under three types of adversarial attacks.
A Diversity-Enhanced and Constraints-Relaxed Augmentation for Low-Resource Classification
Sep 24, 2021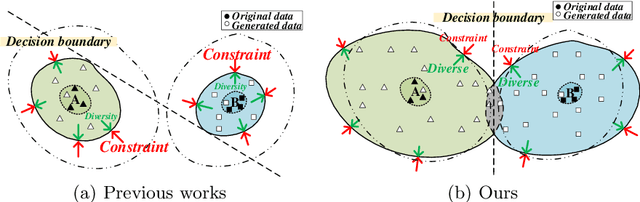
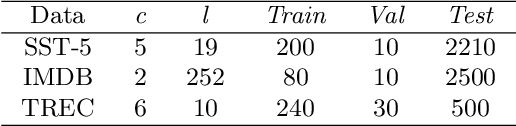
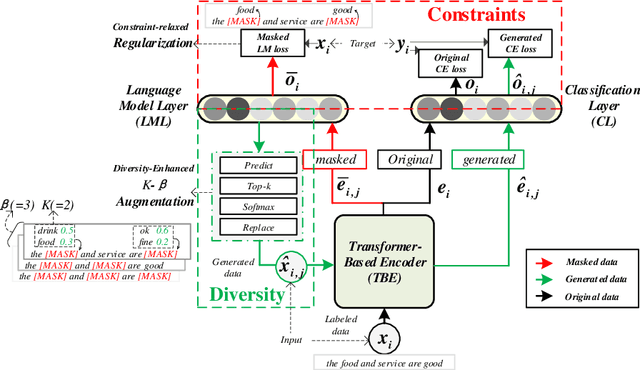
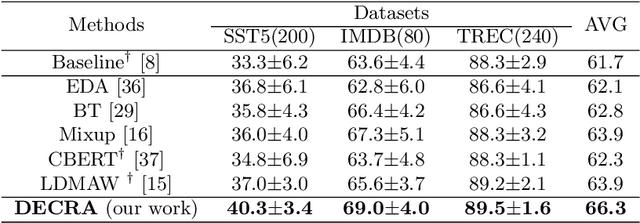
Data augmentation (DA) aims to generate constrained and diversified data to improve classifiers in Low-Resource Classification (LRC). Previous studies mostly use a fine-tuned Language Model (LM) to strengthen the constraints but ignore the fact that the potential of diversity could improve the effectiveness of generated data. In LRC, strong constraints but weak diversity in DA result in the poor generalization ability of classifiers. To address this dilemma, we propose a {D}iversity-{E}nhanced and {C}onstraints-\{R}elaxed {A}ugmentation (DECRA). Our DECRA has two essential components on top of a transformer-based backbone model. 1) A k-beta augmentation, an essential component of DECRA, is proposed to enhance the diversity in generating constrained data. It expands the changing scope and improves the degree of complexity of the generated data. 2) A masked language model loss, instead of fine-tuning, is used as a regularization. It relaxes constraints so that the classifier can be trained with more scattered generated data. The combination of these two components generates data that can reach or approach category boundaries and hence help the classifier generalize better. We evaluate our DECRA on three public benchmark datasets under low-resource settings. Extensive experiments demonstrate that our DECRA outperforms state-of-the-art approaches by 3.8% in the overall score.
Adversarial Mixing Policy for Relaxing Locally Linear Constraints in Mixup
Sep 15, 2021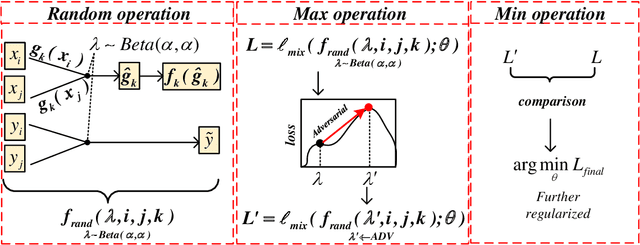
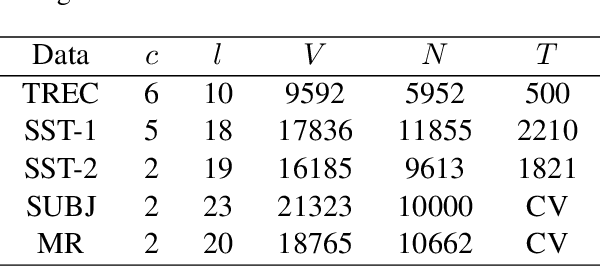
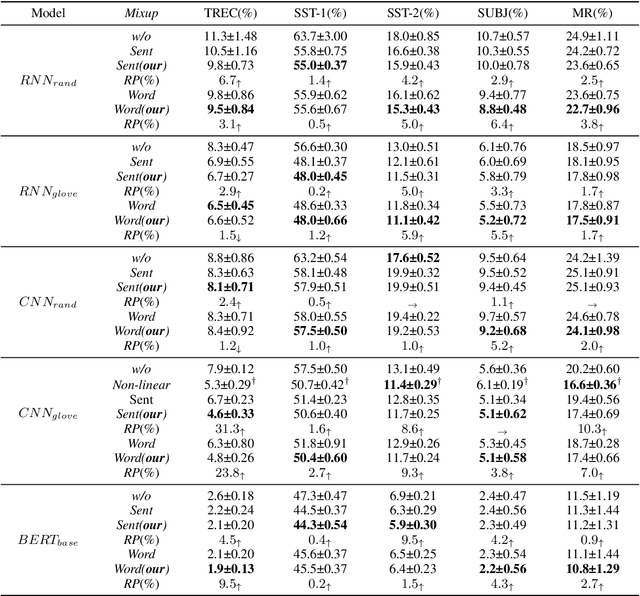
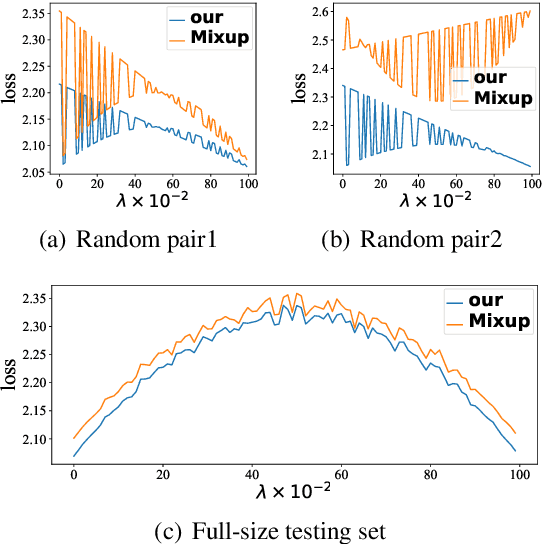
Mixup is a recent regularizer for current deep classification networks. Through training a neural network on convex combinations of pairs of examples and their labels, it imposes locally linear constraints on the model's input space. However, such strict linear constraints often lead to under-fitting which degrades the effects of regularization. Noticeably, this issue is getting more serious when the resource is extremely limited. To address these issues, we propose the Adversarial Mixing Policy (AMP), organized in a min-max-rand formulation, to relax the Locally Linear Constraints in Mixup. Specifically, AMP adds a small adversarial perturbation to the mixing coefficients rather than the examples. Thus, slight non-linearity is injected in-between the synthetic examples and synthetic labels. By training on these data, the deep networks are further regularized, and thus achieve a lower predictive error rate. Experiments on five text classification benchmarks and five backbone models have empirically shown that our methods reduce the error rate over Mixup variants in a significant margin (up to 31.3%), especially in low-resource conditions (up to 17.5%).
DialogueTRM: Exploring the Intra- and Inter-Modal Emotional Behaviors in the Conversation
Oct 15, 2020

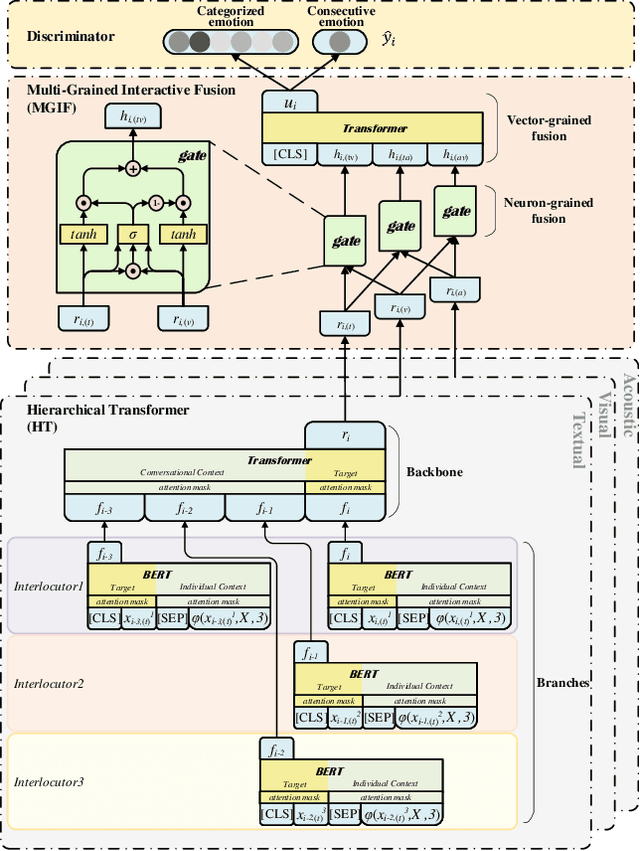
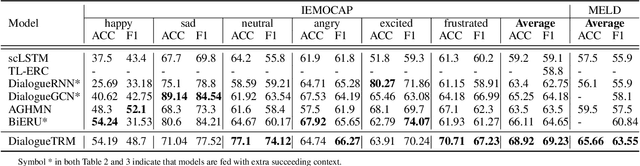
Emotion Recognition in Conversations (ERC) is essential for building empathetic human-machine systems. Existing studies on ERC primarily focus on summarizing the context information in a conversation, however, ignoring the differentiated emotional behaviors within and across different modalities. Designing appropriate strategies that fit the differentiated multi-modal emotional behaviors can produce more accurate emotional predictions. Thus, we propose the DialogueTransformer to explore the differentiated emotional behaviors from the intra- and inter-modal perspectives. For intra-modal, we construct a novel Hierarchical Transformer that can easily switch between sequential and feed-forward structures according to the differentiated context preference within each modality. For inter-modal, we constitute a novel Multi-Grained Interactive Fusion that applies both neuron- and vector-grained feature interactions to learn the differentiated contributions across all modalities. Experimental results show that DialogueTRM outperforms the state-of-the-art by a significant margin on three benchmark datasets.
Hierarchical Context Enhanced Multi-Domain Dialogue System for Multi-domain Task Completion
Mar 03, 2020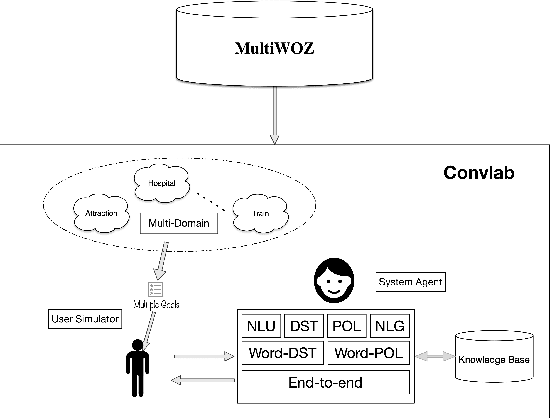
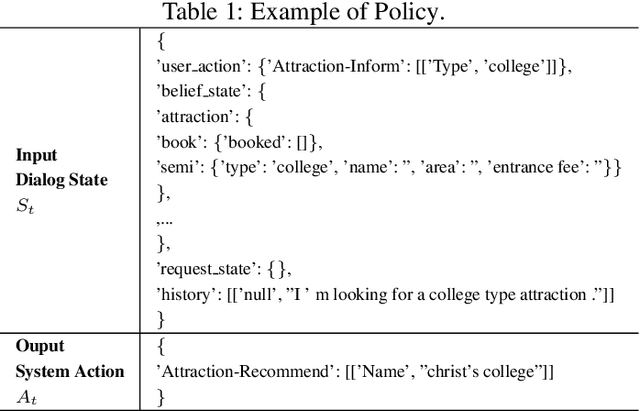
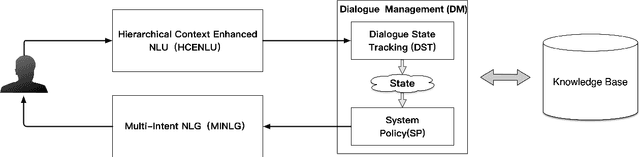

Task 1 of the DSTC8-track1 challenge aims to develop an end-to-end multi-domain dialogue system to accomplish complex users' goals under tourist information desk settings. This paper describes our submitted solution, Hierarchical Context Enhanced Dialogue System (HCEDS), for this task. The main motivation of our system is to comprehensively explore the potential of hierarchical context for sufficiently understanding complex dialogues. More specifically, we apply BERT to capture token-level information and employ the attention mechanism to capture sentence-level information. The results listed in the leaderboard show that our system achieves first place in automatic evaluation and the second place in human evaluation.