 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Diversity-Enhanced and Constraints-Relaxed Augmentation for Low-Resource Classification
Paper and Code
Sep 24, 2021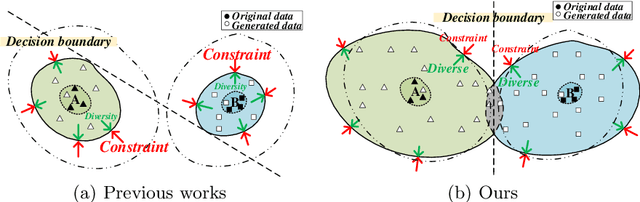
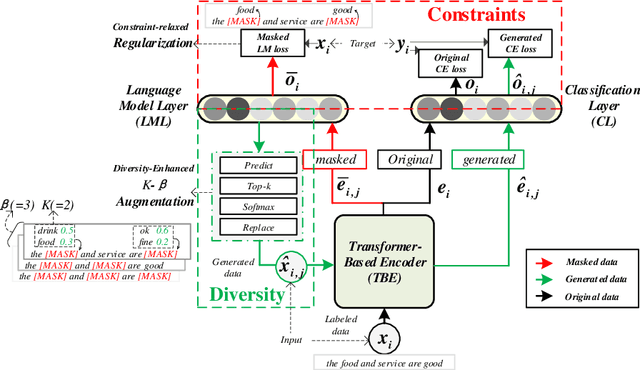
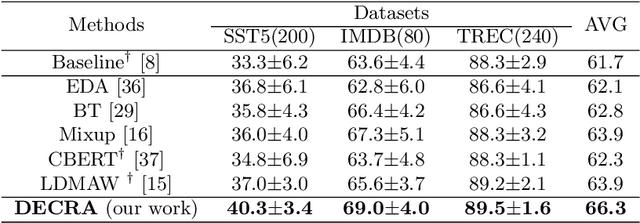
Data augmentation (DA) aims to generate constrained and diversified data to improve classifiers in Low-Resource Classification (LRC). Previous studies mostly use a fine-tuned Language Model (LM) to strengthen the constraints but ignore the fact that the potential of diversity could improve the effectiveness of generated data. In LRC, strong constraints but weak diversity in DA result in the poor generalization ability of classifiers. To address this dilemma, we propose a {D}iversity-{E}nhanced and {C}onstraints-\{R}elaxed {A}ugmentation (DECRA). Our DECRA has two essential components on top of a transformer-based backbone model. 1) A k-beta augmentation, an essential component of DECRA, is proposed to enhance the diversity in generating constrained data. It expands the changing scope and improves the degree of complexity of the generated data. 2) A masked language model loss, instead of fine-tuning, is used as a regularization. It relaxes constraints so that the classifier can be trained with more scattered generated data. The combination of these two components generates data that can reach or approach category boundaries and hence help the classifier generalize better. We evaluate our DECRA on three public benchmark datasets under low-resource settings. Extensive experiments demonstrate that our DECRA outperforms state-of-the-art approaches by 3.8% in the overall score.