 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions
Aug 11, 2025Speculative decoding is a standard method for accelerating the inference speed of large language models. However, scaling it for production environments poses several engineering challenges, including efficiently implementing different operations (e.g., tree attention and multi-round speculative decoding) on GPU. In this paper, we detail the training and inference optimization techniques that we have implemented to enable EAGLE-based speculative decoding at a production scale for Llama models. With these changes, we achieve a new state-of-the-art inference latency for Llama models. For example, Llama4 Maverick decodes at a speed of about 4 ms per token (with a batch size of one) on 8 NVIDIA H100 GPUs, which is 10% faster than the previously best known method. Furthermore, for EAGLE-based speculative decoding, our optimizations enable us to achieve a speed-up for large batch sizes between 1.4x and 2.0x at production scale.
VAEmo: Efficient Representation Learning for Visual-Audio Emotion with Knowledge Injection
May 05, 2025Audiovisual emotion recognition (AVER) aims to infer human emotions from nonverbal visual-audio (VA) cues, offering modality-complementary and language-agnostic advantages. However, AVER remains challenging due to the inherent ambiguity of emotional expressions, cross-modal expressive disparities, and the scarcity of reliably annotated data. Recent self-supervised AVER approaches have introduced strong multimodal representations, yet they predominantly rely on modality-specific encoders and coarse content-level alignment, limiting fine-grained emotional semantic modeling. To address these issues, we propose VAEmo, an efficient two-stage framework for emotion-centric joint VA representation learning with external knowledge injection. In Stage 1, a unified and lightweight representation network is pre-trained on large-scale speaker-centric VA corpora via masked reconstruction and contrastive objectives, mitigating the modality gap and learning expressive, complementary representations without emotion labels. In Stage 2, multimodal large language models automatically generate detailed affective descriptions according to our well-designed chain-of-thought prompting for only a small subset of VA samples; these rich textual semantics are then injected by aligning their corresponding embeddings with VA representations through dual-path contrastive learning, further bridging the emotion gap. Extensive experiments on multiple downstream AVER benchmarks show that VAEmo achieves state-of-the-art performance with a compact design, highlighting the benefit of unified cross-modal encoding and emotion-aware semantic guidance for efficient, generalizable VA emotion representations.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
A Physics-embedded Deep Learning Framework for Cloth Simulation
Mar 27, 2024



Delicate cloth simulations have long been desired in computer graphics. Various methods were proposed to improve engaged force interactions, collision handling, and numerical integrations. Deep learning has the potential to achieve fast and real-time simulation, but common neural network structures often demand many parameters to capture cloth dynamics. This paper proposes a physics-embedded learning framework that directly encodes physical features of cloth simulation. The convolutional neural network is used to represent spatial correlations of the mass-spring system, after which three branches are designed to learn linear, nonlinear, and time derivate features of cloth physics. The framework can also integrate with other external forces and collision handling through either traditional simulators or sub neural networks. The model is tested across different cloth animation cases, without training with new data. Agreement with baselines and predictive realism successfully validate its generalization ability. Inference efficiency of the proposed model also defeats traditional physics simulation. This framework is also designed to easily integrate with other visual refinement techniques like wrinkle carving, which leaves significant chances to incorporate prevailing macing learning techniques in 3D cloth amination.
Diffeomorphism Neural Operator for various domains and parameters of partial differential equations
Feb 19, 2024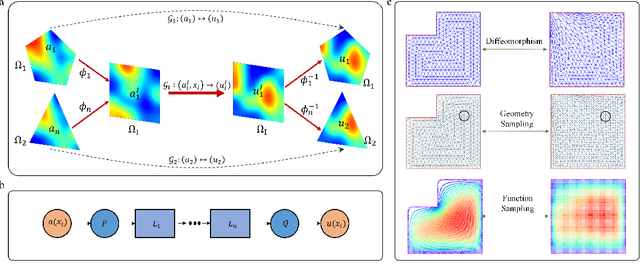
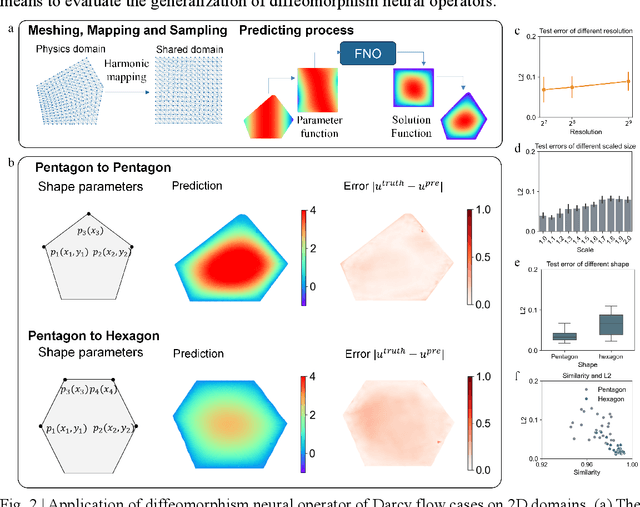
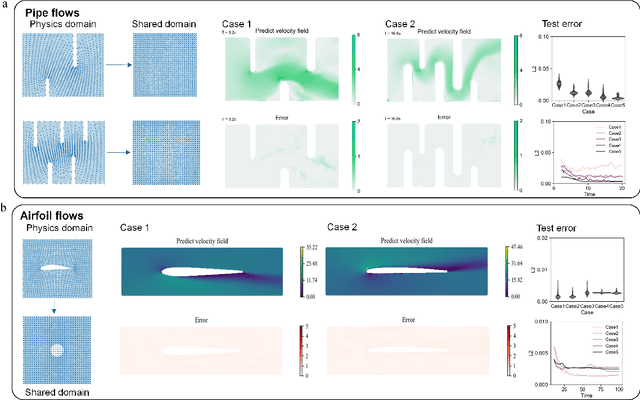
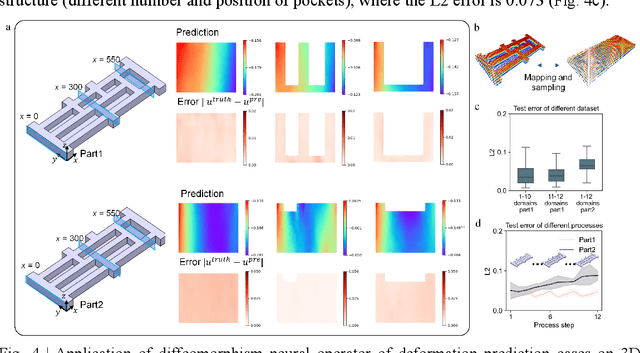
Many science and engineering applications demand partial differential equations (PDE) evaluations that are traditionally computed with resource-intensive numerical solvers. Neural operator models provide an efficient alternative by learning the governing physical laws directly from data in a class of PDEs with different parameters, but constrained in a fixed boundary (domain). Many applications, such as design and manufacturing, would benefit from neural operators with flexible domains when studied at scale. Here we present a diffeomorphism neural operator learning framework towards developing domain-flexible models for physical systems with various and complex domains. Specifically, a neural operator trained in a shared domain mapped from various domains of fields by diffeomorphism is proposed, which transformed the problem of learning function mappings in varying domains (spaces) into the problem of learning operators on a shared diffeomorphic domain. Meanwhile, an index is provided to evaluate the generalization of diffeomorphism neural operators in different domains by the domain diffeomorphism similarity. Experiments on statics scenarios (Darcy flow, mechanics) and dynamic scenarios (pipe flow, airfoil flow) demonstrate the advantages of our approach for neural operator learning under various domains, where harmonic and volume parameterization are used as the diffeomorphism for 2D and 3D domains. Our diffeomorphism neural operator approach enables strong learning capability and robust generalization across varying domains and parameters.
Exploiting Modality-Specific Features For Multi-Modal Manipulation Detection And Grounding
Sep 22, 2023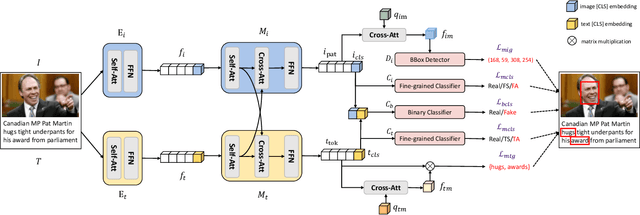
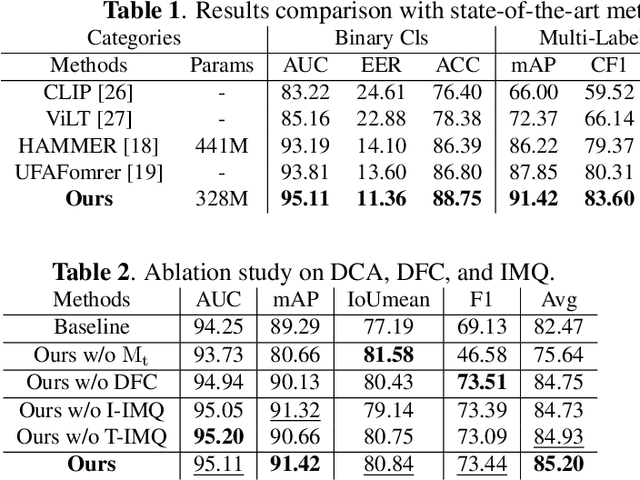

AI-synthesized text and images have gained significant attention, particularly due to the widespread dissemination of multi-modal manipulations on the internet, which has resulted in numerous negative impacts on society. Existing methods for multi-modal manipulation detection and grounding primarily focus on fusing vision-language features to make predictions, while overlooking the importance of modality-specific features, leading to sub-optimal results. In this paper, we construct a simple and novel transformer-based framework for multi-modal manipulation detection and grounding tasks. Our framework simultaneously explores modality-specific features while preserving the capability for multi-modal alignment. To achieve this, we introduce visual/language pre-trained encoders and dual-branch cross-attention (DCA) to extract and fuse modality-unique features. Furthermore, we design decoupled fine-grained classifiers (DFC) to enhance modality-specific feature mining and mitigate modality competition. Moreover, we propose an implicit manipulation query (IMQ) that adaptively aggregates global contextual cues within each modality using learnable queries, thereby improving the discovery of forged details. Extensive experiments on the $\rm DGM^4$ dataset demonstrate the superior performance of our proposed model compared to state-of-the-art approaches.
EVOPOSE: A Recursive Transformer For 3D Human Pose Estimation With Kinematic Structure Priors
Jun 16, 2023



Transformer is popular in recent 3D human pose estimation, which utilizes long-term modeling to lift 2D keypoints into the 3D space. However, current transformer-based methods do not fully exploit the prior knowledge of the human skeleton provided by the kinematic structure. In this paper, we propose a novel transformer-based model EvoPose to introduce the human body prior knowledge for 3D human pose estimation effectively. Specifically, a Structural Priors Representation (SPR) module represents human priors as structural features carrying rich body patterns, e.g. joint relationships. The structural features are interacted with 2D pose sequences and help the model to achieve more informative spatiotemporal features. Moreover, a Recursive Refinement (RR) module is applied to refine the 3D pose outputs by utilizing estimated results and further injects human priors simultaneously. Extensive experiments demonstrate the effectiveness of EvoPose which achieves a new state of the art on two most popular benchmarks, Human3.6M and MPI-INF-3DHP.
Implementation of an Automated Learning System for Non-experts
Mar 26, 2022



Automated machine learning systems for non-experts could be critical for industries to adopt artificial intelligence to their own applications. This paper detailed the engineering system implementation of an automated machine learning system called YMIR, which completely relies on graphical interface to interact with users. After importing training/validation data into the system, a user without AI knowledge can label the data, train models, perform data mining and evaluation by simply clicking buttons. The paper described: 1) Open implementation of model training and inference through docker containers. 2) Implementation of task and resource management. 3) Integration of Labeling software. 4) Implementation of HCI (Human Computer Interaction) with a rebuilt collaborative development paradigm. We also provide subsequent case study on training models with the system. We hope this paper can facilitate the prosperity of our automated machine learning community from industry application perspective. The code of the system has already been released to GitHub (https://github.com/industryessentials/ymir).
Mobility-Aware Cluster Federated Learning in Hierarchical Wireless Networks
Aug 20, 2021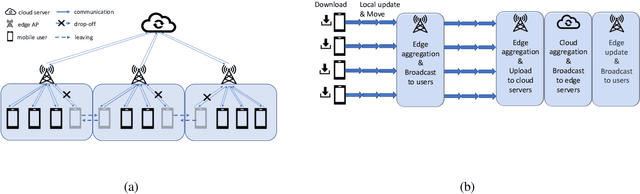

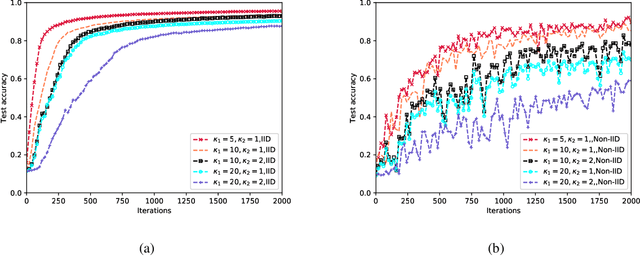
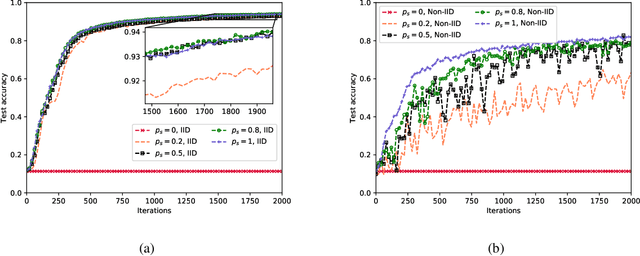
Implementing federated learning (FL) algorithms in wireless networks has garnered a wide range of attention. However, few works have considered the impact of user mobility on the learning performance. To fill this research gap, firstly, we develop a theoretical model to characterize the hierarchical federated learning (HFL) algorithm in wireless networks where the mobile users may roam across multiple edge access points, leading to incompletion of inconsistent FL training. Secondly, we provide the convergence analysis of HFL with user mobility. Our analysis proves that the learning performance of HFL deteriorates drastically with highly-mobile users. And this decline in the learning performance will be exacerbated with small number of participants and large data distribution divergences among local data of users. To circumvent these issues, we propose a mobility-aware cluster federated learning (MACFL) algorithm by redesigning the access mechanism, local update rule and model aggregation scheme. Finally, we provide experiments to evaluate the learning performance of HFL and our MACFL. The results show that our MACFL can enhance the learning performance, especially for three different cases, namely, the case of users with non-independent and identical distribution data, the case of users with high mobility, and the cases with a small number of users.