 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementation of an Automated Learning System for Non-experts
Mar 26, 2022



Automated machine learning systems for non-experts could be critical for industries to adopt artificial intelligence to their own applications. This paper detailed the engineering system implementation of an automated machine learning system called YMIR, which completely relies on graphical interface to interact with users. After importing training/validation data into the system, a user without AI knowledge can label the data, train models, perform data mining and evaluation by simply clicking buttons. The paper described: 1) Open implementation of model training and inference through docker containers. 2) Implementation of task and resource management. 3) Integration of Labeling software. 4) Implementation of HCI (Human Computer Interaction) with a rebuilt collaborative development paradigm. We also provide subsequent case study on training models with the system. We hope this paper can facilitate the prosperity of our automated machine learning community from industry application perspective. The code of the system has already been released to GitHub (https://github.com/industryessentials/ymir).
YMIR: A Rapid Data-centric Development Platform for Vision Applications
Nov 27, 2021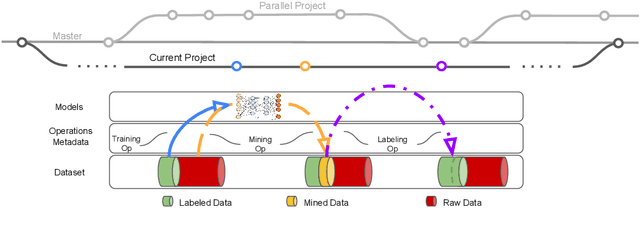
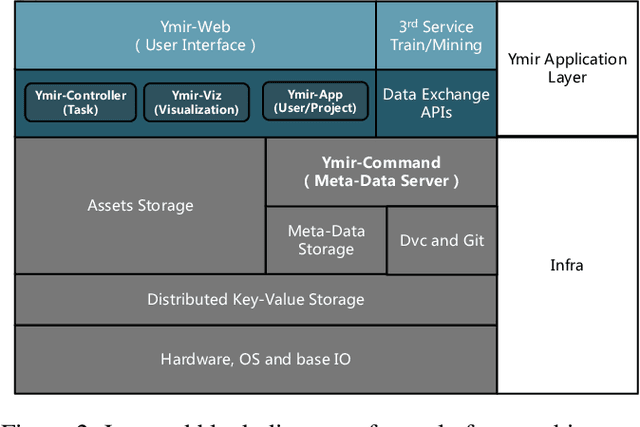
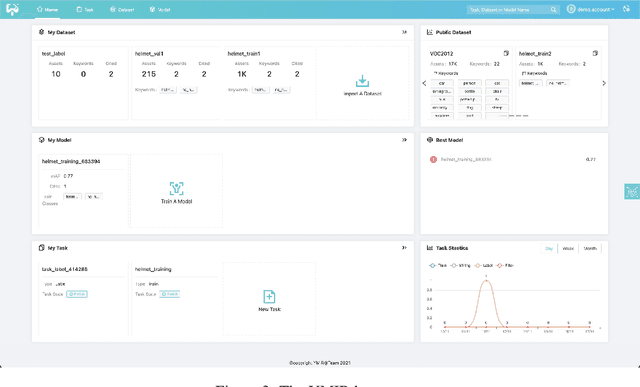
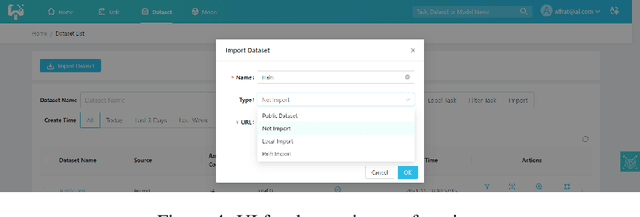
This paper introduces an open source platform to support the rapid development of computer vision applications at scale. The platform puts the efficient data development at the center of the machine learning development process, integrates active learning methods, data and model version control, and uses concepts such as projects to enable fast iterations of multiple task specific datasets in parallel. This platform abstracts the development process into core states and operations, and integrates third party tools via open APIs as implementations of the operations. This open design reduces the development cost and adoption cost for ML teams with existing tools. At the same time, the platform supports recording project development histories, through which successful projects can be shared to further boost model production efficiency on similar tasks. The platform is open source and is already used internally to meet the increasing demand for different real world computer vision applications.
Automatic Spatially-aware Fashion Concept Discovery
Aug 03, 2017



This paper proposes an automatic spatially-aware concept discovery approach using weakly labeled image-text data from shopping websites. We first fine-tune GoogleNet by jointly modeling clothing images and their corresponding descriptions in a visual-semantic embedding space. Then, for each attribute (word), we generate its spatially-aware representation by combining its semantic word vector representation with its spatial representation derived from the convolutional maps of the fine-tuned network. The resulting spatially-aware representations are further used to cluster attributes into multiple groups to form spatially-aware concepts (e.g., the neckline concept might consist of attributes like v-neck, round-neck, etc). Finally, we decompose the visual-semantic embedding space into multiple concept-specific subspaces, which facilitates structured browsing and attribute-feedback product retrieval by exploiting multimodal linguistic regularities. We conducted extensive experiments on our newly collected Fashion200K dataset, and results on clustering quality evaluation and attribute-feedback product retrieval task demonstrate the effectiveness of our automatically discovered spatially-aware concepts.