 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYMIR: A Rapid Data-centric Development Platform for Vision Applications
Nov 27, 2021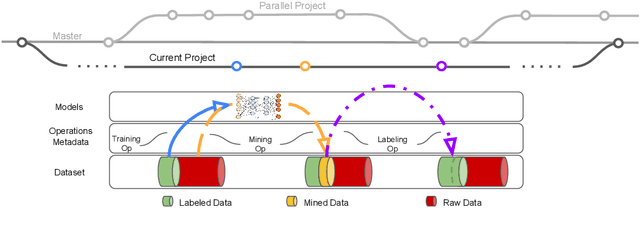
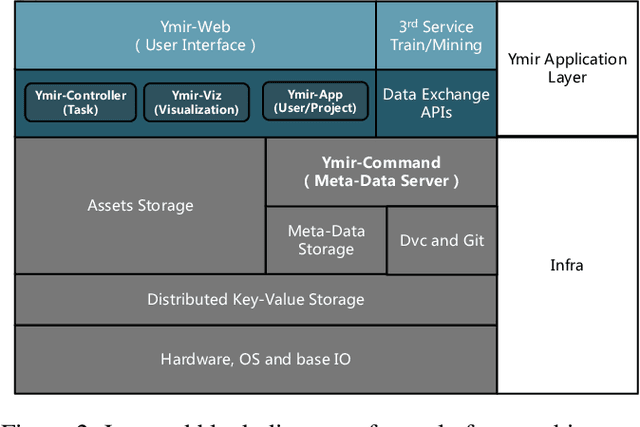
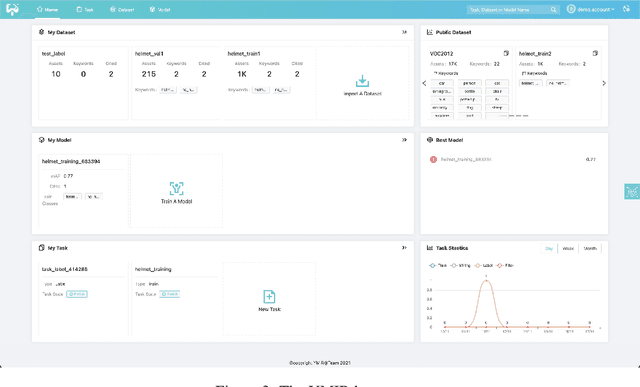
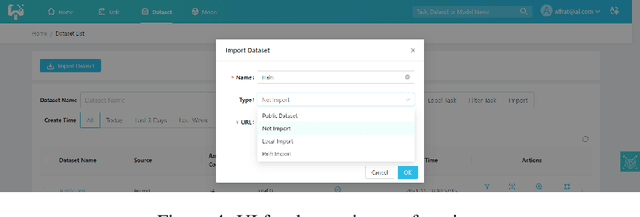
This paper introduces an open source platform to support the rapid development of computer vision applications at scale. The platform puts the efficient data development at the center of the machine learning development process, integrates active learning methods, data and model version control, and uses concepts such as projects to enable fast iterations of multiple task specific datasets in parallel. This platform abstracts the development process into core states and operations, and integrates third party tools via open APIs as implementations of the operations. This open design reduces the development cost and adoption cost for ML teams with existing tools. At the same time, the platform supports recording project development histories, through which successful projects can be shared to further boost model production efficiency on similar tasks. The platform is open source and is already used internally to meet the increasing demand for different real world computer vision applications.
Train One Get One Free: Partially Supervised Neural Network for Bug Report Duplicate Detection and Clustering
Apr 04, 2019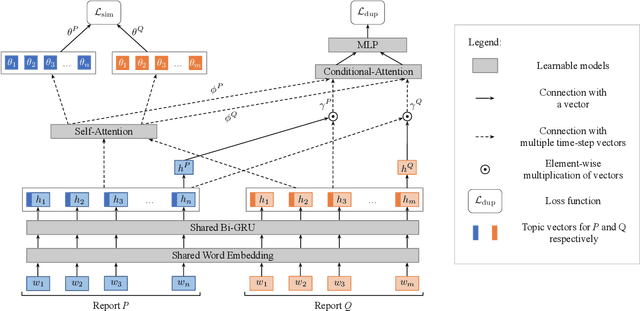
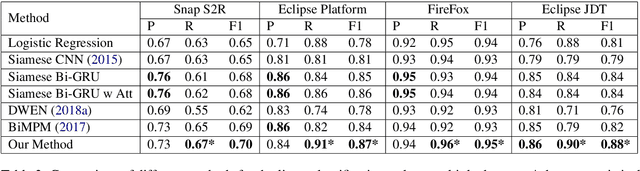
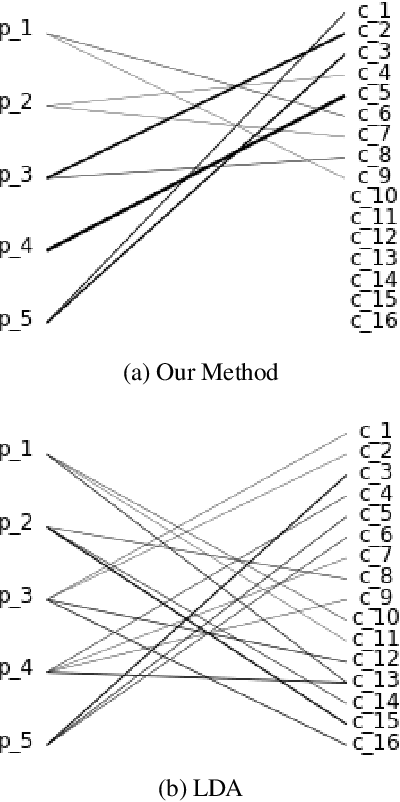
Tracking user reported bugs requires considerable engineering effort in going through many repetitive reports and assigning them to the correct teams. This paper proposes a neural architecture that can jointly (1) detect if two bug reports are duplicates, and (2) aggregate them into latent topics. Leveraging the assumption that learning the topic of a bug is a sub-task for detecting duplicates, we design a loss function that can jointly perform both tasks but needs supervision for only duplicate classification, achieving topic clustering in an unsupervised fashion. We use a two-step attention module that uses self-attention for topic clustering and conditional attention for duplicate detection. We study the characteristics of two types of real world datasets that have been marked for duplicate bugs by engineers and by non-technical annotators. The results demonstrate that our model not only can outperform state-of-the-art methods for duplicate classification on both cases, but can also learn meaningful latent clusters without additional supervision.
End-to-End Time-Lapse Video Synthesis from a Single Outdoor Image
Apr 01, 2019



Time-lapse videos usually contain visually appealing content but are often difficult and costly to create. In this paper, we present an end-to-end solution to synthesize a time-lapse video from a single outdoor image using deep neural networks. Our key idea is to train a conditional generative adversarial network based on existing datasets of time-lapse videos and image sequences. We propose a multi-frame joint conditional generation framework to effectively learn the correlation between the illumination change of an outdoor scene and the time of the day. We further present a multi-domain training scheme for robust training of our generative models from two datasets with different distributions and missing timestamp labels. Compared to alternative time-lapse video synthesis algorithms, our method uses the timestamp as the control variable and does not require a reference video to guide the synthesis of the final output. We conduct ablation studies to validate our algorithm and compare with state-of-the-art techniques both qualitatively and quantitatively.
Exploring Emoji Usage and Prediction Through a Temporal Variation Lens
May 02, 2018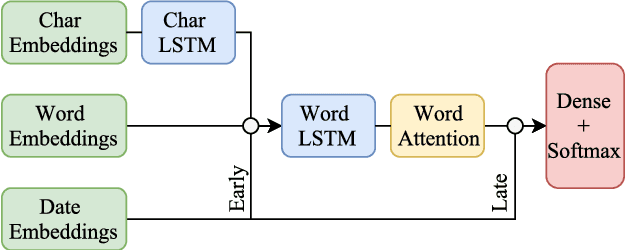
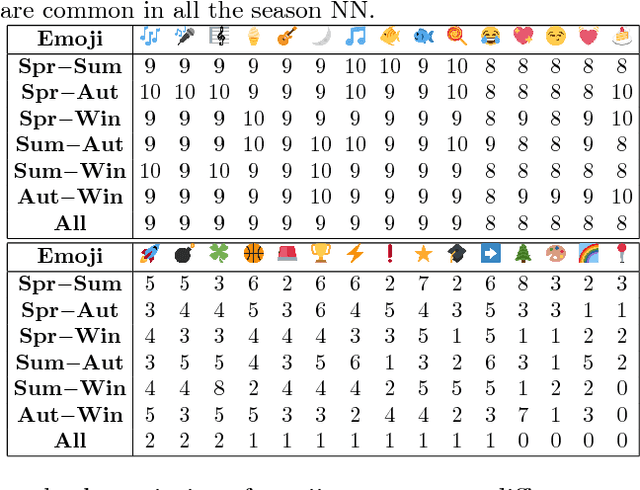

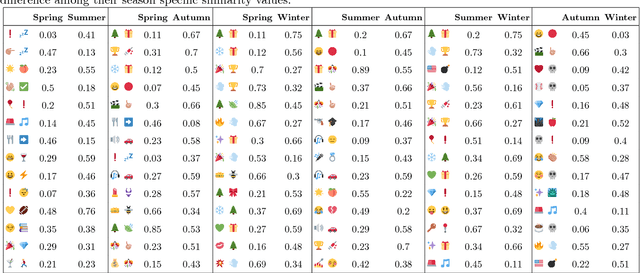
The frequent use of Emojis on social media platforms has created a new form of multimodal social interaction. Developing methods for the study and representation of emoji semantics helps to improve future multimodal communication systems. In this paper, we explore the usage and semantics of emojis over time. We compare emoji embeddings trained on a corpus of different seasons and show that some emojis are used differently depending on the time of the year. Moreover, we propose a method to take into account the time information for emoji prediction systems, outperforming state-of-the-art systems. We show that, using the time information, the accuracy of some emojis can be significantly improved.