 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain One Get One Free: Partially Supervised Neural Network for Bug Report Duplicate Detection and Clustering
Apr 04, 2019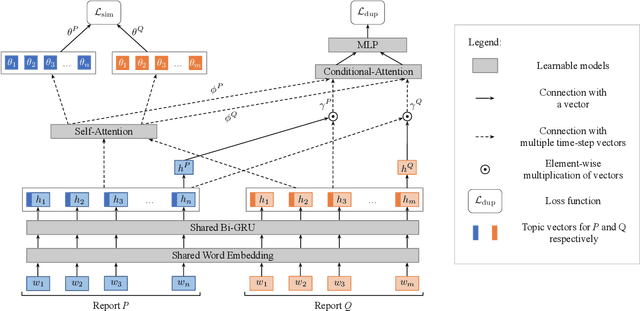
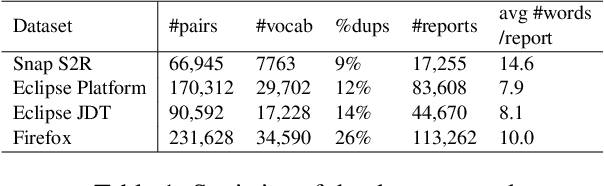
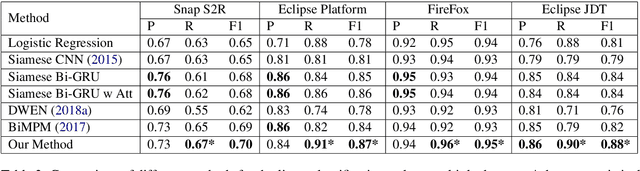
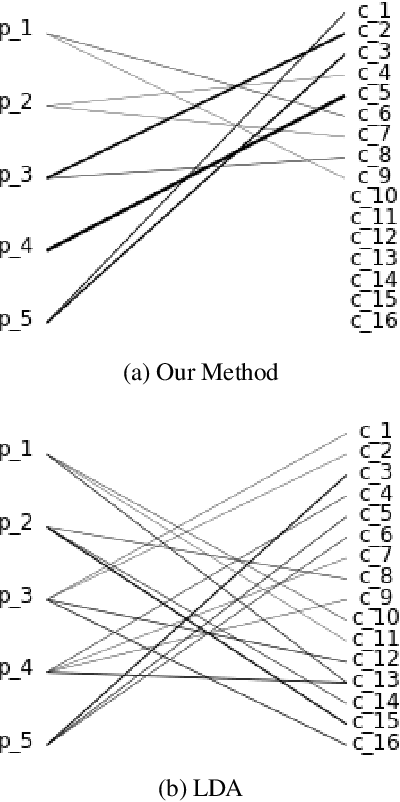
Tracking user reported bugs requires considerable engineering effort in going through many repetitive reports and assigning them to the correct teams. This paper proposes a neural architecture that can jointly (1) detect if two bug reports are duplicates, and (2) aggregate them into latent topics. Leveraging the assumption that learning the topic of a bug is a sub-task for detecting duplicates, we design a loss function that can jointly perform both tasks but needs supervision for only duplicate classification, achieving topic clustering in an unsupervised fashion. We use a two-step attention module that uses self-attention for topic clustering and conditional attention for duplicate detection. We study the characteristics of two types of real world datasets that have been marked for duplicate bugs by engineers and by non-technical annotators. The results demonstrate that our model not only can outperform state-of-the-art methods for duplicate classification on both cases, but can also learn meaningful latent clusters without additional supervision.
Exploring Emoji Usage and Prediction Through a Temporal Variation Lens
May 02, 2018
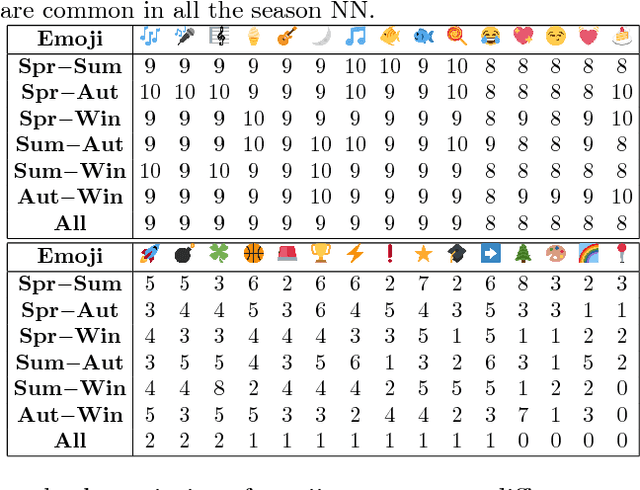

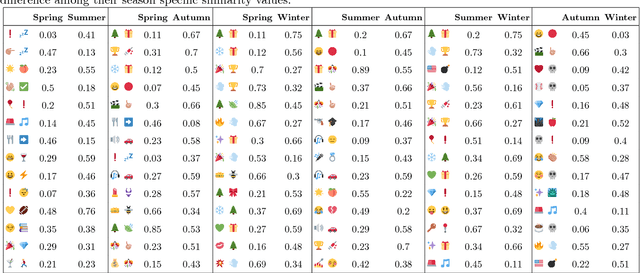
The frequent use of Emojis on social media platforms has created a new form of multimodal social interaction. Developing methods for the study and representation of emoji semantics helps to improve future multimodal communication systems. In this paper, we explore the usage and semantics of emojis over time. We compare emoji embeddings trained on a corpus of different seasons and show that some emojis are used differently depending on the time of the year. Moreover, we propose a method to take into account the time information for emoji prediction systems, outperforming state-of-the-art systems. We show that, using the time information, the accuracy of some emojis can be significantly improved.
Co-Multistage of Multiple Classifiers for Imbalanced Multiclass Learning
Jan 24, 2014
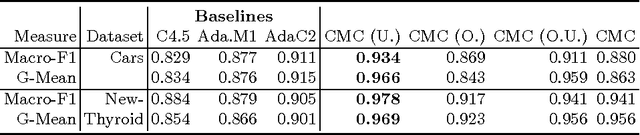

In this work, we propose two stochastic architectural models (CMC and CMC-M) with two layers of classifiers applicable to datasets with one and multiple skewed classes. This distinction becomes important when the datasets have a large number of classes. Therefore, we present a novel solution to imbalanced multiclass learning with several skewed majority classes, which improves minority classes identification. This fact is particularly important for text classification tasks, such as event detection. Our models combined with pre-processing sampling techniques improved the classification results on six well-known datasets. Finally, we have also introduced a new metric SG-Mean to overcome the multiplication by zero limitation of G-Mean.
Recognition of Named-Event Passages in News Articles
Jun 20, 2013

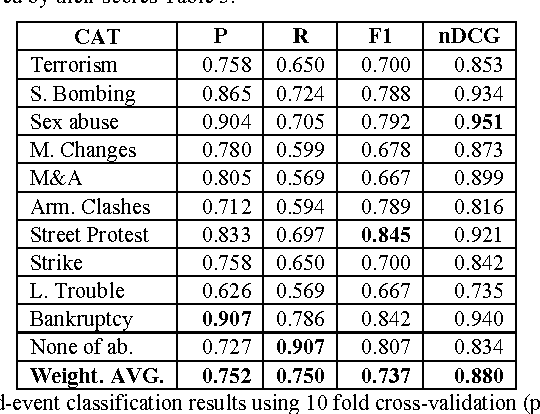

We extend the concept of Named Entities to Named Events - commonly occurring events such as battles and earthquakes. We propose a method for finding specific passages in news articles that contain information about such events and report our preliminary evaluation results. Collecting "Gold Standard" data presents many problems, both practical and conceptual. We present a method for obtaining such data using the Amazon Mechanical Turk service.
Key Phrase Extraction of Lightly Filtered Broadcast News
Jun 20, 2013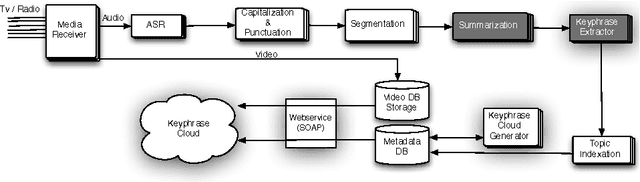
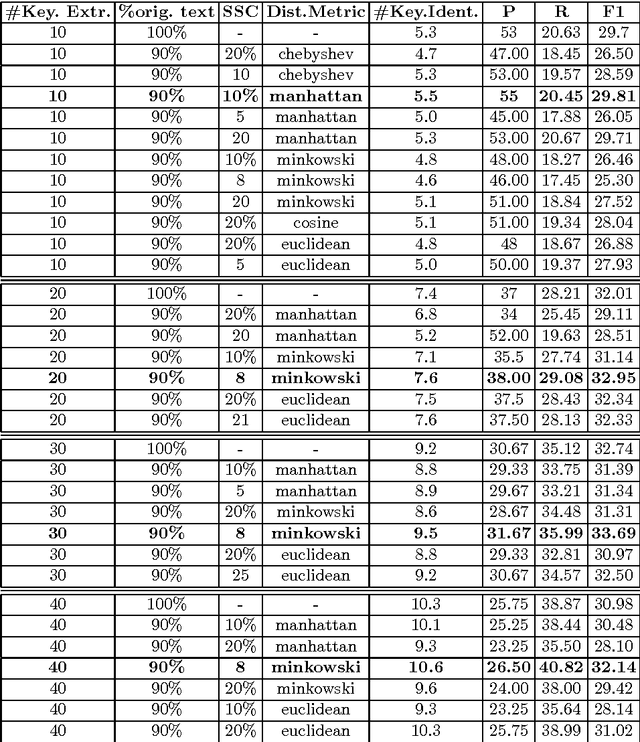
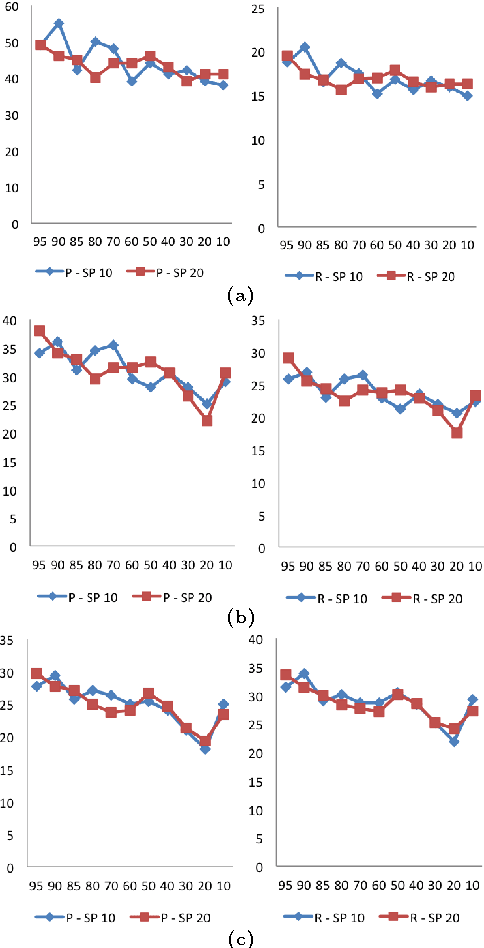
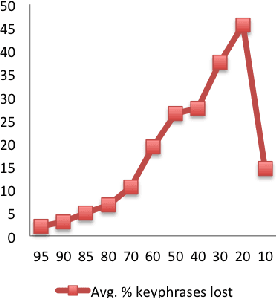
This paper explores the impact of light filtering on automatic key phrase extraction (AKE) applied to Broadcast News (BN). Key phrases are words and expressions that best characterize the content of a document. Key phrases are often used to index the document or as features in further processing. This makes improvements in AKE accuracy particularly important. We hypothesized that filtering out marginally relevant sentences from a document would improve AKE accuracy. Our experiments confirmed this hypothesis. Elimination of as little as 10% of the document sentences lead to a 2% improvement in AKE precision and recall. AKE is built over MAUI toolkit that follows a supervised learning approach. We trained and tested our AKE method on a gold standard made of 8 BN programs containing 110 manually annotated news stories. The experiments were conducted within a Multimedia Monitoring Solution (MMS) system for TV and radio news/programs, running daily, and monitoring 12 TV and 4 radio channels.
Supervised Topical Key Phrase Extraction of News Stories using Crowdsourcing, Light Filtering and Co-reference Normalization
Jun 20, 2013
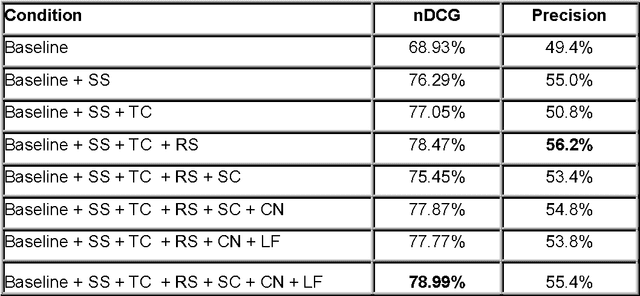
Fast and effective automated indexing is critical for search and personalized services. Key phrases that consist of one or more words and represent the main concepts of the document are often used for the purpose of indexing. In this paper, we investigate the use of additional semantic features and pre-processing steps to improve automatic key phrase extraction. These features include the use of signal words and freebase categories. Some of these features lead to significant improvements in the accuracy of the results. We also experimented with 2 forms of document pre-processing that we call light filtering and co-reference normalization. Light filtering removes sentences from the document, which are judged peripheral to its main content. Co-reference normalization unifies several written forms of the same named entity into a unique form. We also needed a "Gold Standard" - a set of labeled documents for training and evaluation. While the subjective nature of key phrase selection precludes a true "Gold Standard", we used Amazon's Mechanical Turk service to obtain a useful approximation. Our data indicates that the biggest improvements in performance were due to shallow semantic features, news categories, and rhetorical signals (nDCG 78.47% vs. 68.93%). The inclusion of deeper semantic features such as Freebase sub-categories was not beneficial by itself, but in combination with pre-processing, did cause slight improvements in the nDCG scores.