 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew Shot Rationale Generation using Self-Training with Dual Teachers
Jun 05, 2023Self-rationalizing models that also generate a free-text explanation for their predicted labels are an important tool to build trustworthy AI applications. Since generating explanations for annotated labels is a laborious and costly pro cess, recent models rely on large pretrained language models (PLMs) as their backbone and few-shot learning. In this work we explore a self-training approach leveraging both labeled and unlabeled data to further improve few-shot models, under the assumption that neither human written rationales nor annotated task labels are available at scale. We introduce a novel dual-teacher learning framework, which learns two specialized teacher models for task prediction and rationalization using self-training and distills their knowledge into a multi-tasking student model that can jointly generate the task label and rationale. Furthermore, we formulate a new loss function, Masked Label Regularization (MLR) which promotes explanations to be strongly conditioned on predicted labels. Evaluation on three public datasets demonstrate that the proposed methods are effective in modeling task labels and generating faithful rationales.
Deploying a Retrieval based Response Model for Task Oriented Dialogues
Oct 25, 2022


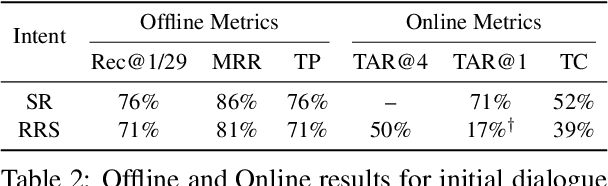
Task-oriented dialogue systems in industry settings need to have high conversational capability, be easily adaptable to changing situations and conform to business constraints. This paper describes a 3-step procedure to develop a conversational model that satisfies these criteria and can efficiently scale to rank a large set of response candidates. First, we provide a simple algorithm to semi-automatically create a high-coverage template set from historic conversations without any annotation. Second, we propose a neural architecture that encodes the dialogue context and applicable business constraints as profile features for ranking the next turn. Third, we describe a two-stage learning strategy with self-supervised training, followed by supervised fine-tuning on limited data collected through a human-in-the-loop platform. Finally, we describe offline experiments and present results of deploying our model with human-in-the-loop to converse with live customers online.
DialAug: Mixing up Dialogue Contexts in Contrastive Learning for Robust Conversational Modeling
Apr 15, 2022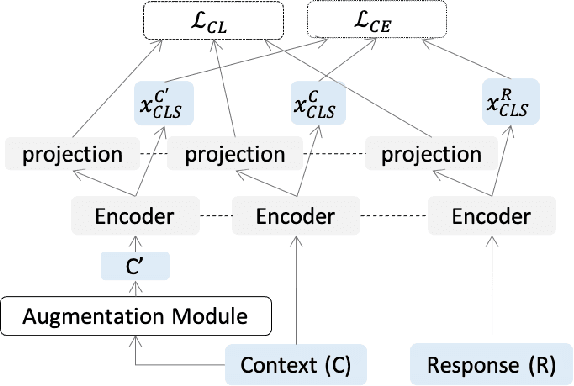
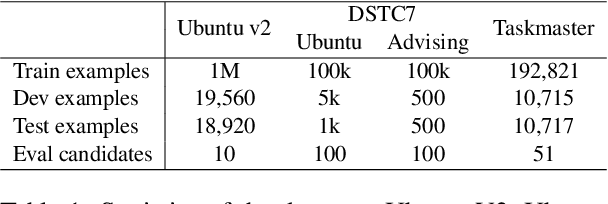

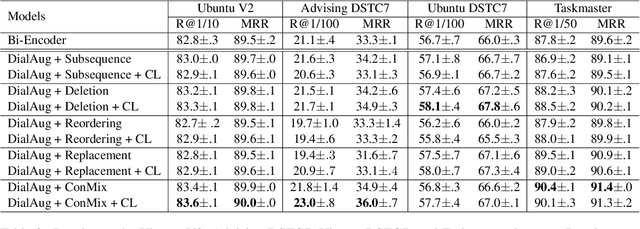
Retrieval-based conversational systems learn to rank response candidates for a given dialogue context by computing the similarity between their vector representations. However, training on a single textual form of the multi-turn context limits the ability of a model to learn representations that generalize to natural perturbations seen during inference. In this paper we propose a framework that incorporates augmented versions of a dialogue context into the learning objective. We utilize contrastive learning as an auxiliary objective to learn robust dialogue context representations that are invariant to perturbations injected through the augmentation method. We experiment with four benchmark dialogue datasets and demonstrate that our framework combines well with existing augmentation methods and can significantly improve over baseline BERT-based ranking architectures. Furthermore, we propose a novel data augmentation method, ConMix, that adds token level perturbations through stochastic mixing of tokens from other contexts in the batch. We show that our proposed augmentation method outperforms previous data augmentation approaches, and provides dialogue representations that are more robust to common perturbations seen during inference.
Attention Guided Dialogue State Tracking with Sparse Supervision
Jan 28, 2021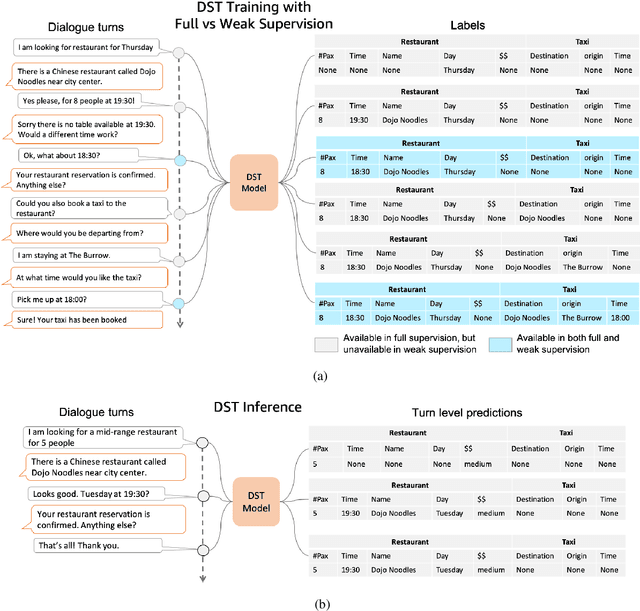

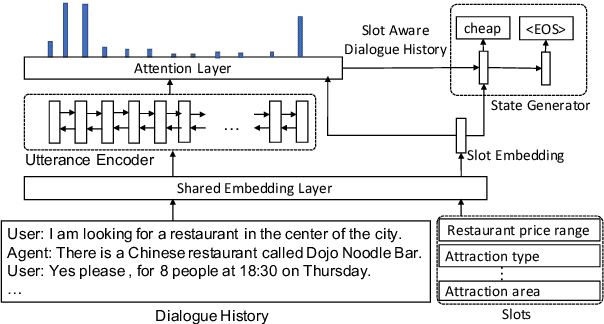
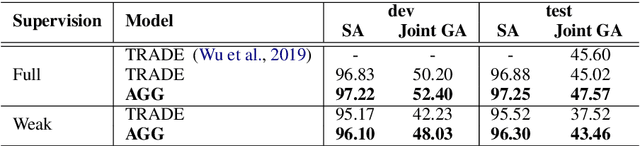
Existing approaches to Dialogue State Tracking (DST) rely on turn level dialogue state annotations, which are expensive to acquire in large scale. In call centers, for tasks like managing bookings or subscriptions, the user goal can be associated with actions (e.g.~API calls) issued by customer service agents. These action logs are available in large volumes and can be utilized for learning dialogue states. However, unlike turn-level annotations, such logged actions are only available sparsely across the dialogue, providing only a form of weak supervision for DST models. To efficiently learn DST with sparse labels, we extend a state-of-the-art encoder-decoder model. The model learns a slot-aware representation of dialogue history, which focuses on relevant turns to guide the decoder. We present results on two public multi-domain DST datasets (MultiWOZ and Schema Guided Dialogue) in both settings i.e. training with turn-level and with sparse supervision. The proposed approach improves over baseline in both settings. More importantly, our model trained with sparse supervision is competitive in performance to fully supervised baselines, while being more data and cost efficient.
A Probabilistic Framework for Learning Domain Specific Hierarchical Word Embeddings
Oct 20, 2019

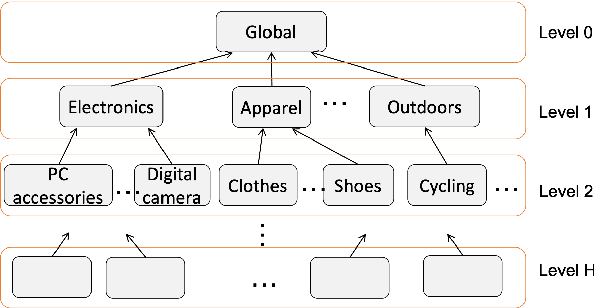
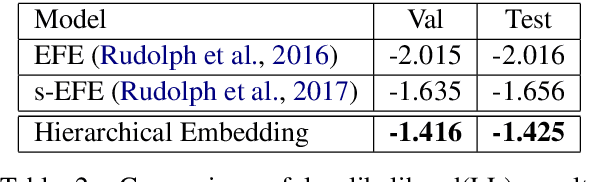
The meaning of a word often varies depending on its usage in different domains. The standard word embedding models struggle to represent this variation, as they learn a single global representation for a word. We propose a method to learn domain-specific word embeddings, from text organized into hierarchical domains, such as reviews in an e-commerce website, where products follow a taxonomy. Our structured probabilistic model allows vector representations for the same word to drift away from each other for distant domains in the taxonomy, to accommodate its domain-specific meanings. By learning sets of domain-specific word representations jointly, our model can leverage domain relationships, and it scales well with the number of domains. Using large real-world review datasets, we demonstrate the effectiveness of our model compared to state-of-the-art approaches, in learning domain-specific word embeddings that are both intuitive to humans and benefit downstream NLP tasks.
Train One Get One Free: Partially Supervised Neural Network for Bug Report Duplicate Detection and Clustering
Apr 04, 2019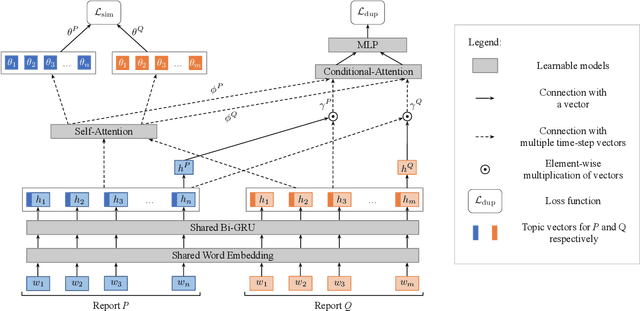
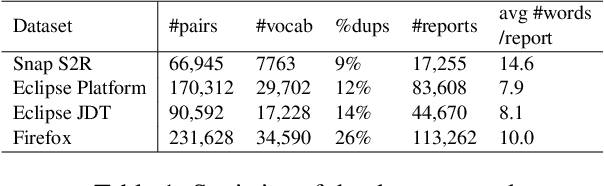
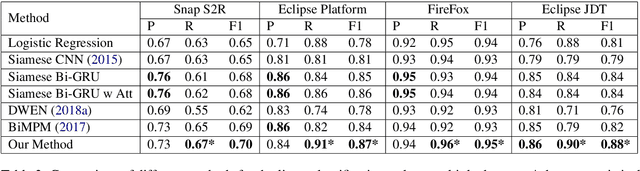
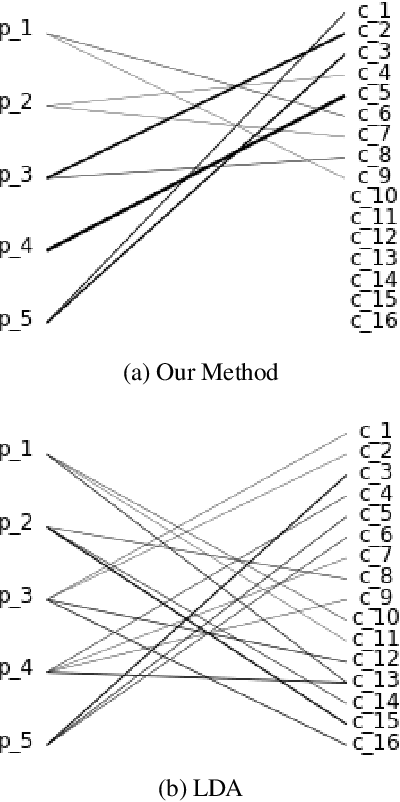
Tracking user reported bugs requires considerable engineering effort in going through many repetitive reports and assigning them to the correct teams. This paper proposes a neural architecture that can jointly (1) detect if two bug reports are duplicates, and (2) aggregate them into latent topics. Leveraging the assumption that learning the topic of a bug is a sub-task for detecting duplicates, we design a loss function that can jointly perform both tasks but needs supervision for only duplicate classification, achieving topic clustering in an unsupervised fashion. We use a two-step attention module that uses self-attention for topic clustering and conditional attention for duplicate detection. We study the characteristics of two types of real world datasets that have been marked for duplicate bugs by engineers and by non-technical annotators. The results demonstrate that our model not only can outperform state-of-the-art methods for duplicate classification on both cases, but can also learn meaningful latent clusters without additional supervision.
Quantifying Aspect Bias in Ordinal Ratings using a Bayesian Approach
May 24, 2017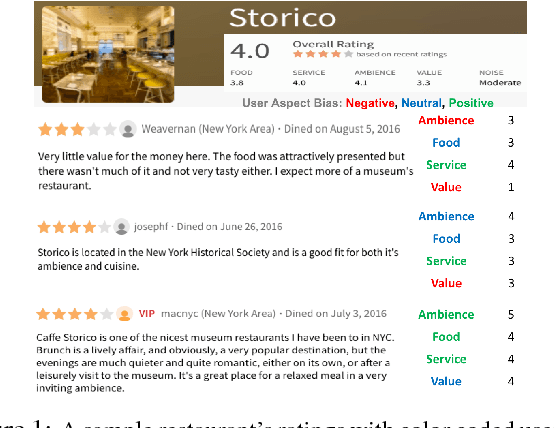
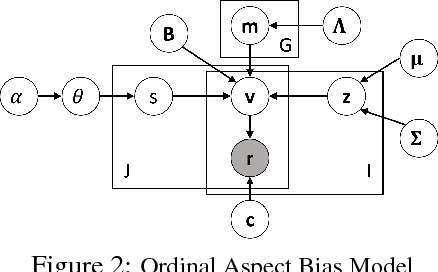
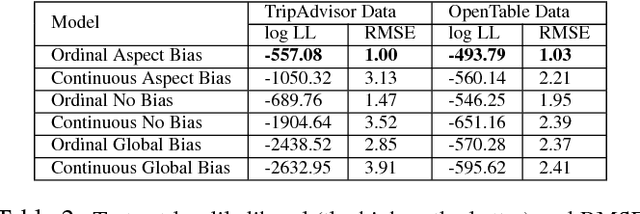
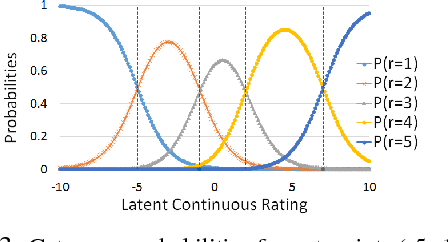
User opinions expressed in the form of ratings can influence an individual's view of an item. However, the true quality of an item is often obfuscated by user biases, and it is not obvious from the observed ratings the importance different users place on different aspects of an item. We propose a probabilistic modeling of the observed aspect ratings to infer (i) each user's aspect bias and (ii) latent intrinsic quality of an item. We model multi-aspect ratings as ordered discrete data and encode the dependency between different aspects by using a latent Gaussian structure. We handle the Gaussian-Categorical non-conjugacy using a stick-breaking formulation coupled with P\'{o}lya-Gamma auxiliary variable augmentation for a simple, fully Bayesian inference. On two real world datasets, we demonstrate the predictive ability of our model and its effectiveness in learning explainable user biases to provide insights towards a more reliable product quality estimation.
Multilingual Multiword Expressions
Dec 01, 2016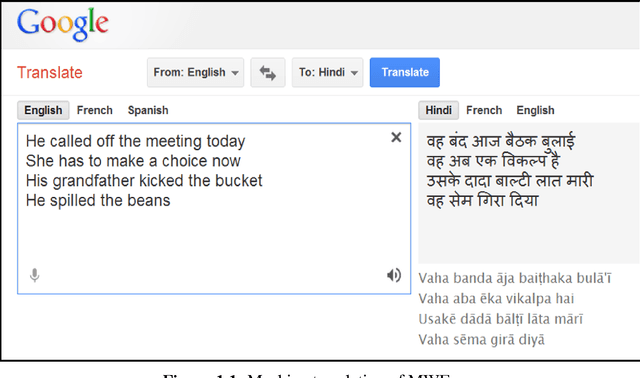
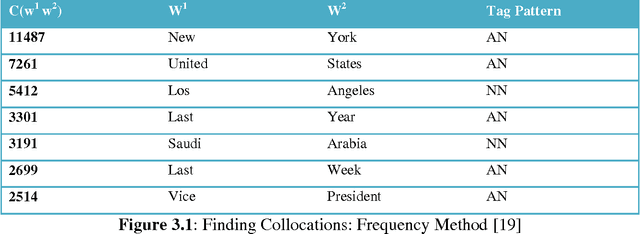

The project aims to provide a semi-supervised approach to identify Multiword Expressions in a multilingual context consisting of English and most of the major Indian languages. Multiword expressions are a group of words which refers to some conventional or regional way of saying things. If they are literally translated from one language to another the expression will lose its inherent meaning. To automatically extract multiword expressions from a corpus, an extraction pipeline have been constructed which consist of a combination of rule based and statistical approaches. There are several types of multiword expressions which differ from each other widely by construction. We employ different methods to detect different types of multiword expressions. Given a POS tagged corpus in English or any Indian language the system initially applies some regular expression filters to narrow down the search space to certain patterns (like, reduplication, partial reduplication, compound nouns, compound verbs, conjunct verbs etc.). The word sequences matching the required pattern are subjected to a series of linguistic tests which include verb filtering, named entity filtering and hyphenation filtering test to exclude false positives. The candidates are then checked for semantic relationships among themselves (using Wordnet). In order to detect partial reduplication we make use of Wordnet as a lexical database as well as a tool for lemmatising. We detect complex predicates by investigating the features of the constituent words. Statistical methods are applied to detect collocations. Finally, lexicographers examine the list of automatically extracted candidates to validate whether they are true multiword expressions or not and add them to the multiword dictionary accordingly.
Sentiment Analysis for Twitter : Going Beyond Tweet Text
Nov 29, 2016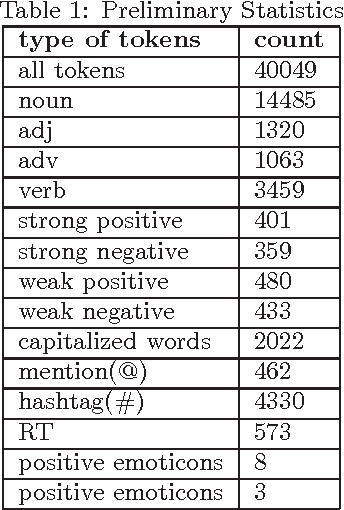


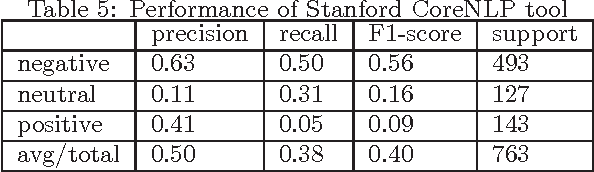
Analysing sentiment of tweets is important as it helps to determine the users' opinion. Knowing people's opinion is crucial for several purposes starting from gathering knowledge about customer base, e-governance, campaigning and many more. In this report, we aim to develop a system to detect the sentiment from tweets. We employ several linguistic features along with some other external sources of information to detect the sentiment of a tweet. We show that augmenting the 140 character-long tweet with information harvested from external urls shared in the tweet as well as Social Media features enhances the sentiment prediction accuracy significantly.