 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Guided Dialogue State Tracking with Sparse Supervision
Jan 28, 2021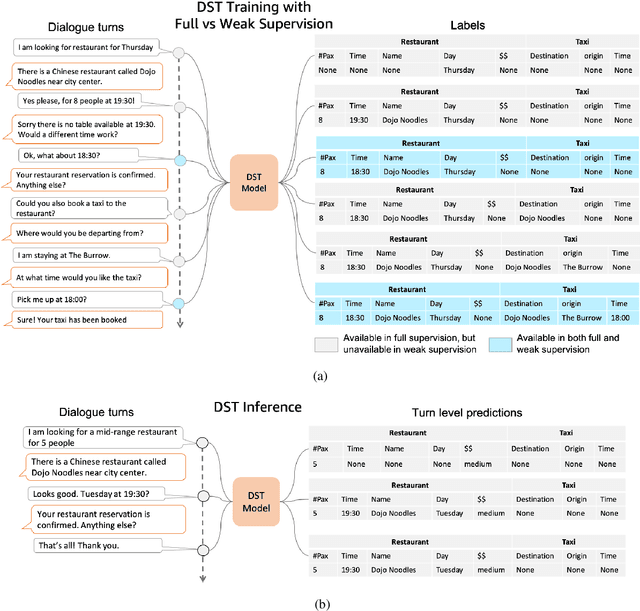

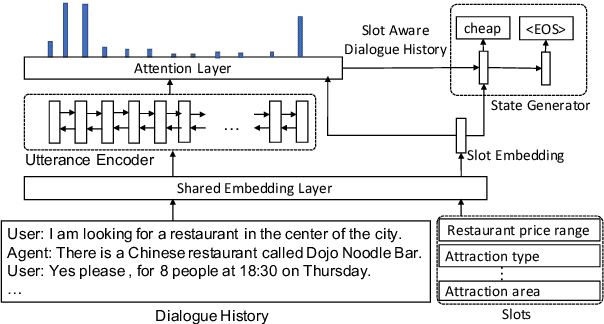
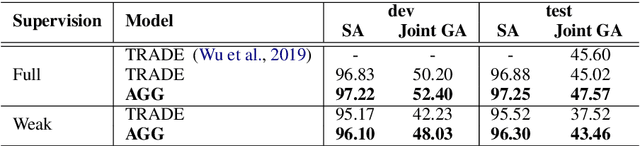
Existing approaches to Dialogue State Tracking (DST) rely on turn level dialogue state annotations, which are expensive to acquire in large scale. In call centers, for tasks like managing bookings or subscriptions, the user goal can be associated with actions (e.g.~API calls) issued by customer service agents. These action logs are available in large volumes and can be utilized for learning dialogue states. However, unlike turn-level annotations, such logged actions are only available sparsely across the dialogue, providing only a form of weak supervision for DST models. To efficiently learn DST with sparse labels, we extend a state-of-the-art encoder-decoder model. The model learns a slot-aware representation of dialogue history, which focuses on relevant turns to guide the decoder. We present results on two public multi-domain DST datasets (MultiWOZ and Schema Guided Dialogue) in both settings i.e. training with turn-level and with sparse supervision. The proposed approach improves over baseline in both settings. More importantly, our model trained with sparse supervision is competitive in performance to fully supervised baselines, while being more data and cost efficient.
SemEval-2020 Task 4: Commonsense Validation and Explanation
Jul 01, 2020



In this paper, we present SemEval-2020 Task 4, Commonsense Validation and Explanation (ComVE), which includes three subtasks, aiming to evaluate whether a system can distinguish a natural language statement that makes sense to human from one that does not, and provide the reasons. Specifically, in our first subtask, the participating systems are required to choose from two natural language statements of similar wording the one that makes sense and the one does not. The second subtask additionally asks a system to select the key reason from three options why a given statement does not make sense. In the third subtask, a participating system needs to generate the reason automatically.
Does It Make Sense? And Why? A Pilot Study for Sense Making and Explanation
Jun 02, 2019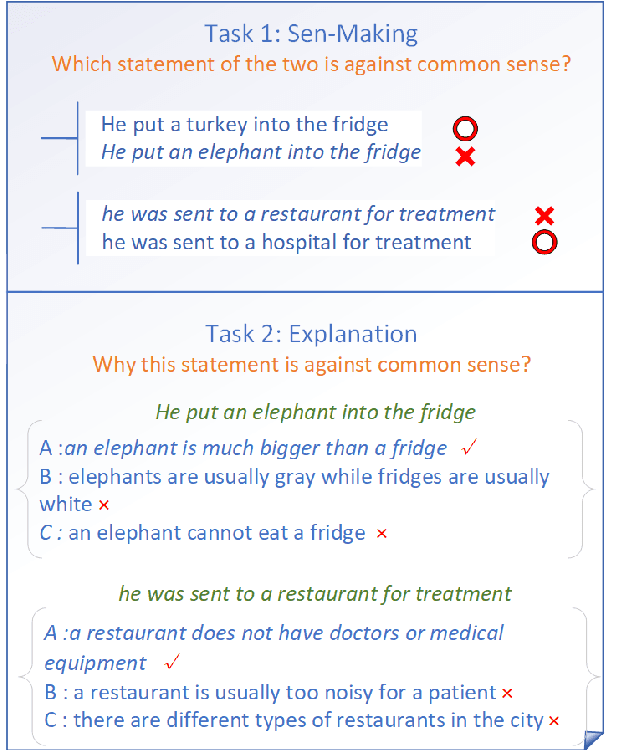
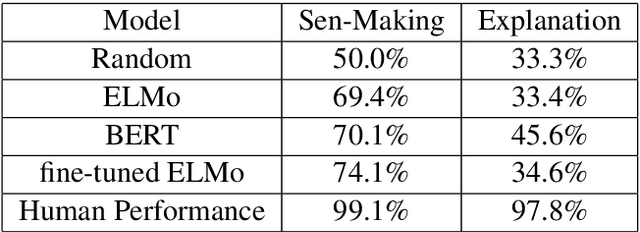
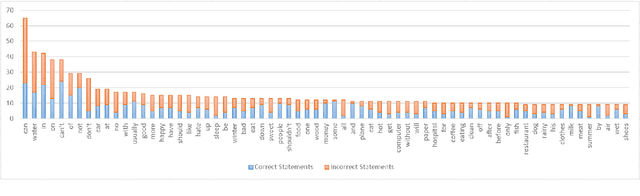
Introducing common sense to natural language understanding systems has received increasing research attention. It remains a fundamental question on how to evaluate whether a system has a sense making capability. Existing benchmarks measures commonsense knowledge indirectly and without explanation. In this paper, we release a benchmark to directly test whether a system can differentiate natural language statements that make sense from those that do not make sense. In addition, a system is asked to identify the most crucial reason why a statement does not make sense. We evaluate models trained over large-scale language modeling tasks as well as human performance, showing that there are different challenges for system sense making.
Who Blames Whom in a Crisis? Detecting Blame Ties from News Articles Using Neural Networks
Apr 24, 2019
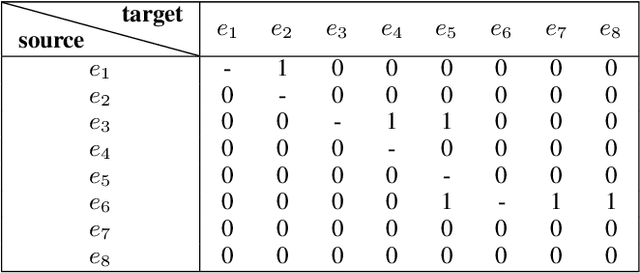
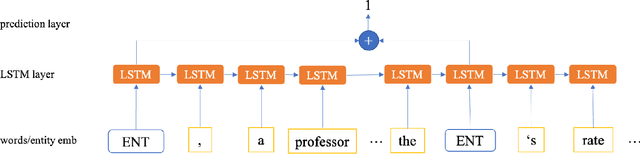
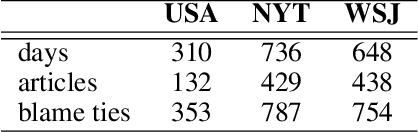
Blame games tend to follow major disruptions, be they financial crises, natural disasters or terrorist attacks. To study how the blame game evolves and shapes the dominant crisis narratives is of great significance, as sense-making processes can affect regulatory outcomes, social hierarchies, and cultural norms. However, it takes tremendous time and efforts for social scientists to manually examine each relevant news article and extract the blame ties (A blames B). In this study, we define a new task, Blame Tie Extraction, and construct a new dataset related to the United States financial crisis (2007-2010) from The New York Times, The Wall Street Journal and USA Today. We build a Bi-directional Long Short-Term Memory (BiLSTM) network for contexts where the entities appear in and it learns to automatically extract such blame ties at the document level. Leveraging the large unsupervised model such as GloVe and ELMo, our best model achieves an F1 score of 70% on the test set for blame tie extraction, making it a useful tool for social scientists to extract blame ties more efficiently.
Subword Encoding in Lattice LSTM for Chinese Word Segmentation
Oct 30, 2018

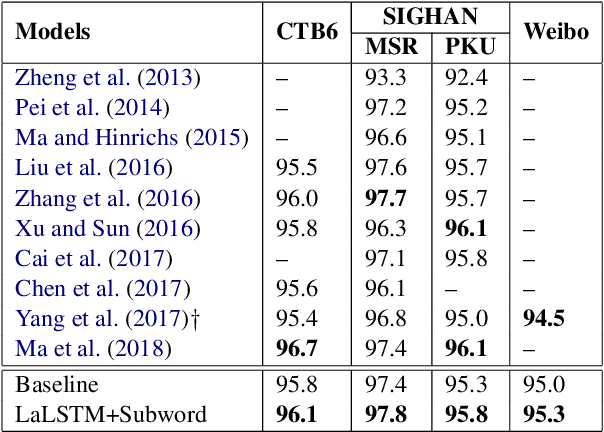
We investigate a lattice LSTM network for Chinese word segmentation (CWS) to utilize words or subwords. It integrates the character sequence features with all subsequences information matched from a lexicon. The matched subsequences serve as information shortcut tunnels which link their start and end characters directly. Gated units are used to control the contribution of multiple input links. Through formula derivation and comparison, we show that the lattice LSTM is an extension of the standard LSTM with the ability to take multiple inputs. Previous lattice LSTM model takes word embeddings as the lexicon input, we prove that subword encoding can give the comparable performance and has the benefit of not relying on any external segmentor. The contribution of lattice LSTM comes from both lexicon and pretrained embeddings information, we find that the lexicon information contributes more than the pretrained embeddings information through controlled experiments. Our experiments show that the lattice structure with subword encoding gives competitive or better results with previous state-of-the-art methods on four segmentation benchmarks. Detailed analyses are conducted to compare the performance of word encoding and subword encoding in lattice LSTM. We also investigate the performance of lattice LSTM structure under different circumstances and when this model works or fails.
Design Challenges and Misconceptions in Neural Sequence Labeling
Jul 12, 2018
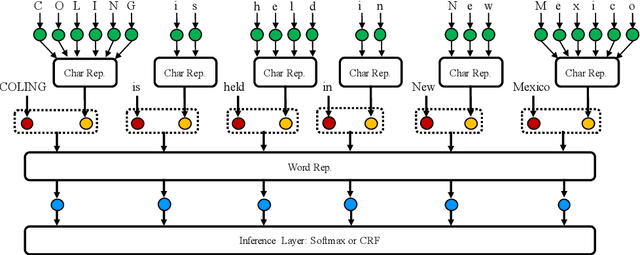
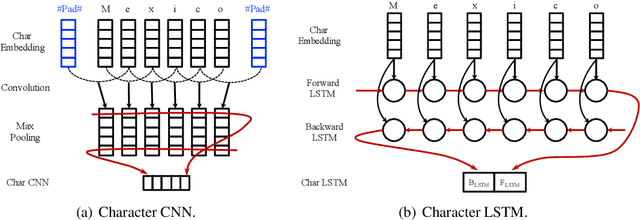
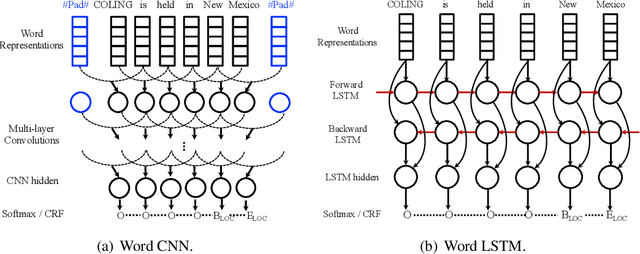
We investigate the design challenges of constructing effective and efficient neural sequence labeling systems, by reproducing twelve neural sequence labeling models, which include most of the state-of-the-art structures, and conduct a systematic model comparison on three benchmarks (i.e. NER, Chunking, and POS tagging). Misconceptions and inconsistent conclusions in existing literature are examined and clarified under statistical experiments. In the comparison and analysis process, we reach several practical conclusions which can be useful to practitioners.