 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating Verbalized Probabilities for Large Language Models
Oct 09, 2024


Calibrating verbalized probabilities presents a novel approach for reliably assessing and leveraging outputs from black-box Large Language Models (LLMs). Recent methods have demonstrated improved calibration by applying techniques like Platt scaling or temperature scaling to the confidence scores generated by LLMs. In this paper, we explore the calibration of verbalized probability distributions for discriminative tasks. First, we investigate the capability of LLMs to generate probability distributions over categorical labels. We theoretically and empirically identify the issue of re-softmax arising from the scaling of verbalized probabilities, and propose using the invert softmax trick to approximate the "logit" by inverting verbalized probabilities. Through extensive evaluation on three public datasets, we demonstrate: (1) the robust capability of LLMs in generating class distributions, and (2) the effectiveness of the invert softmax trick in estimating logits, which, in turn, facilitates post-calibration adjustments.
Taming Continuous Posteriors for Latent Variational Dialogue Policies
May 16, 2022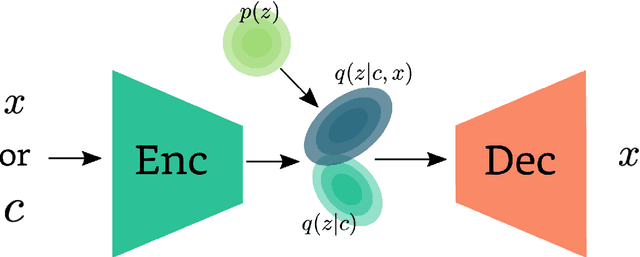


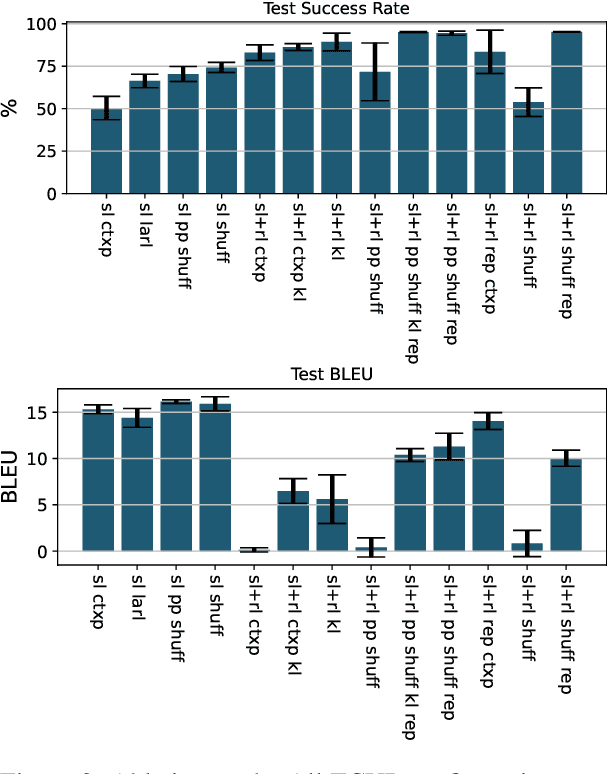
Utilizing amortized variational inference for latent-action reinforcement learning (RL) has been shown to be an effective approach in Task-oriented Dialogue (ToD) systems for optimizing dialogue success. Until now, categorical posteriors have been argued to be one of the main drivers of performance. In this work we revisit Gaussian variational posteriors for latent-action RL and show that they can yield even better performance than categoricals. We achieve this by simplifying the training procedure and propose ways to regularize the latent dialogue policy to retain good response coherence. Using continuous latent representations our model achieves state of the art dialogue success rate on the MultiWOZ benchmark, and also compares well to categorical latent methods in response coherence.
Attention Guided Dialogue State Tracking with Sparse Supervision
Jan 28, 2021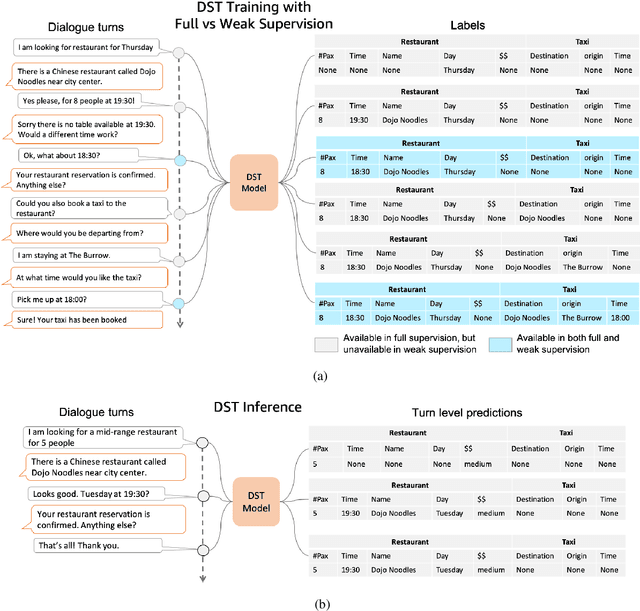

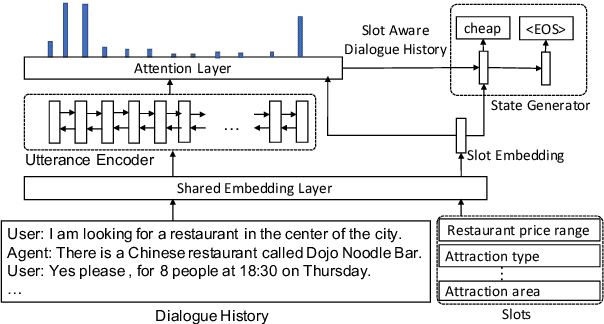
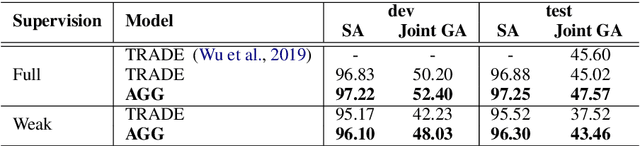
Existing approaches to Dialogue State Tracking (DST) rely on turn level dialogue state annotations, which are expensive to acquire in large scale. In call centers, for tasks like managing bookings or subscriptions, the user goal can be associated with actions (e.g.~API calls) issued by customer service agents. These action logs are available in large volumes and can be utilized for learning dialogue states. However, unlike turn-level annotations, such logged actions are only available sparsely across the dialogue, providing only a form of weak supervision for DST models. To efficiently learn DST with sparse labels, we extend a state-of-the-art encoder-decoder model. The model learns a slot-aware representation of dialogue history, which focuses on relevant turns to guide the decoder. We present results on two public multi-domain DST datasets (MultiWOZ and Schema Guided Dialogue) in both settings i.e. training with turn-level and with sparse supervision. The proposed approach improves over baseline in both settings. More importantly, our model trained with sparse supervision is competitive in performance to fully supervised baselines, while being more data and cost efficient.