 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Multiword Expressions
Paper and Code
Dec 01, 2016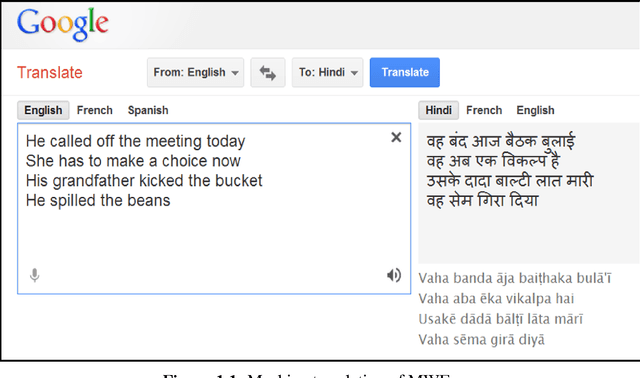
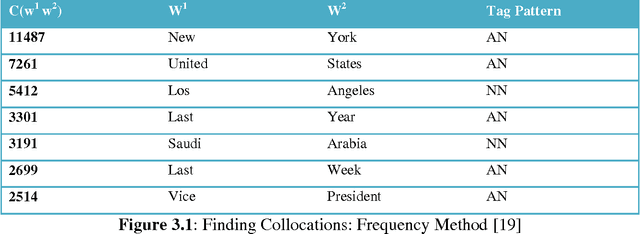

The project aims to provide a semi-supervised approach to identify Multiword Expressions in a multilingual context consisting of English and most of the major Indian languages. Multiword expressions are a group of words which refers to some conventional or regional way of saying things. If they are literally translated from one language to another the expression will lose its inherent meaning. To automatically extract multiword expressions from a corpus, an extraction pipeline have been constructed which consist of a combination of rule based and statistical approaches. There are several types of multiword expressions which differ from each other widely by construction. We employ different methods to detect different types of multiword expressions. Given a POS tagged corpus in English or any Indian language the system initially applies some regular expression filters to narrow down the search space to certain patterns (like, reduplication, partial reduplication, compound nouns, compound verbs, conjunct verbs etc.). The word sequences matching the required pattern are subjected to a series of linguistic tests which include verb filtering, named entity filtering and hyphenation filtering test to exclude false positives. The candidates are then checked for semantic relationships among themselves (using Wordnet). In order to detect partial reduplication we make use of Wordnet as a lexical database as well as a tool for lemmatising. We detect complex predicates by investigating the features of the constituent words. Statistical methods are applied to detect collocations. Finally, lexicographers examine the list of automatically extracted candidates to validate whether they are true multiword expressions or not and add them to the multiword dictionary accordingly.