 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecIF: Improving Instruction-Following through Meta-Decomposition
May 20, 2025



Instruction-following has emerged as a crucial capability for large language models (LLMs). However, existing approaches often rely on pre-existing documents or external resources to synthesize instruction-following data, which limits their flexibility and generalizability. In this paper, we introduce DecIF, a fully autonomous, meta-decomposition guided framework that generates diverse and high-quality instruction-following data using only LLMs. DecIF is grounded in the principle of decomposition. For instruction generation, we guide LLMs to iteratively produce various types of meta-information, which are then combined with response constraints to form well-structured and semantically rich instructions. We further utilize LLMs to detect and resolve potential inconsistencies within the generated instructions. Regarding response generation, we decompose each instruction into atomic-level evaluation criteria, enabling rigorous validation and the elimination of inaccurate instruction-response pairs. Extensive experiments across a wide range of scenarios and settings demonstrate DecIF's superior performance on instruction-following tasks. Further analysis highlights its strong flexibility, scalability, and generalizability in automatically synthesizing high-quality instruction data.
Smaller Language Models Are Better Instruction Evolvers
Dec 15, 2024



Instruction tuning has been widely used to unleash the complete potential of large language models. Notably, complex and diverse instructions are of significant importance as they can effectively align models with various downstream tasks. However, current approaches to constructing large-scale instructions predominantly favour powerful models such as GPT-4 or those with over 70 billion parameters, under the empirical presumption that such larger language models (LLMs) inherently possess enhanced capabilities. In this study, we question this prevalent assumption and conduct an in-depth exploration into the potential of smaller language models (SLMs) in the context of instruction evolution. Extensive experiments across three scenarios of instruction evolution reveal that smaller language models (SLMs) can synthesize more effective instructions than LLMs. Further analysis demonstrates that SLMs possess a broader output space during instruction evolution, resulting in more complex and diverse variants. We also observe that the existing metrics fail to focus on the impact of the instructions. Thus, we propose Instruction Complex-Aware IFD (IC-IFD), which introduces instruction complexity in the original IFD score to evaluate the effectiveness of instruction data more accurately. Our source code is available at: \href{https://github.com/HypherX/Evolution-Analysis}{https://github.com/HypherX/Evolution-Analysis}
MotionGPT-2: A General-Purpose Motion-Language Model for Motion Generation and Understanding
Oct 29, 2024



Generating lifelike human motions from descriptive texts has experienced remarkable research focus in the recent years, propelled by the emerging requirements of digital humans.Despite impressive advances, existing approaches are often constrained by limited control modalities, task specificity, and focus solely on body motion representations.In this paper, we present MotionGPT-2, a unified Large Motion-Language Model (LMLM) that addresses these limitations. MotionGPT-2 accommodates multiple motion-relevant tasks and supporting multimodal control conditions through pre-trained Large Language Models (LLMs). It quantizes multimodal inputs-such as text and single-frame poses-into discrete, LLM-interpretable tokens, seamlessly integrating them into the LLM's vocabulary. These tokens are then organized into unified prompts, guiding the LLM to generate motion outputs through a pretraining-then-finetuning paradigm. We also show that the proposed MotionGPT-2 is highly adaptable to the challenging 3D holistic motion generation task, enabled by the innovative motion discretization framework, Part-Aware VQVAE, which ensures fine-grained representations of body and hand movements. Extensive experiments and visualizations validate the effectiveness of our method, demonstrating the adaptability of MotionGPT-2 across motion generation, motion captioning, and generalized motion completion tasks.
CountMamba: Exploring Multi-directional Selective State-Space Models for Plant Counting
Oct 10, 2024


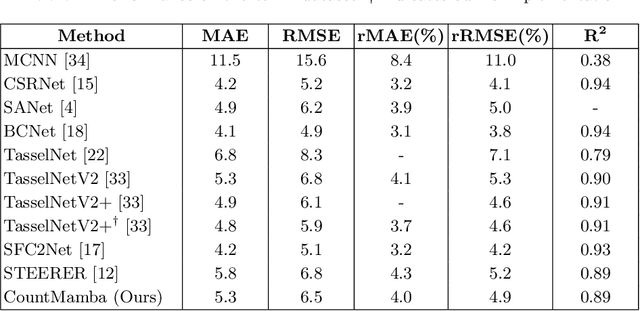
Plant counting is essential in every stage of agriculture, including seed breeding, germination, cultivation, fertilization, pollination yield estimation, and harvesting. Inspired by the fact that humans count objects in high-resolution images by sequential scanning, we explore the potential of handling plant counting tasks via state space models (SSMs) for generating counting results. In this paper, we propose a new counting approach named CountMamba that constructs multiple counting experts to scan from various directions simultaneously. Specifically, we design a Multi-directional State-Space Group to process the image patch sequences in multiple orders and aim to simulate different counting experts. We also design Global-Local Adaptive Fusion to adaptively aggregate global features extracted from multiple directions and local features extracted from the CNN branch in a sample-wise manner. Extensive experiments demonstrate that the proposed CountMamba performs competitively on various plant counting tasks, including maize tassels, wheat ears, and sorghum head counting.
MotionGPT: Finetuned LLMs are General-Purpose Motion Generators
Jun 19, 2023
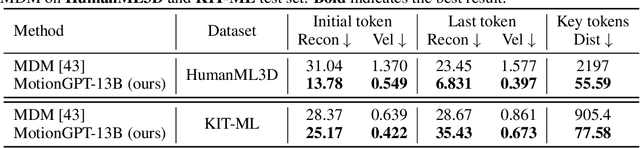
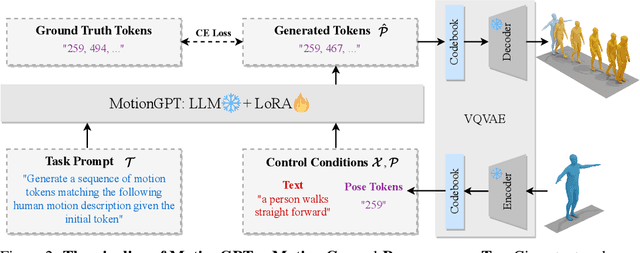
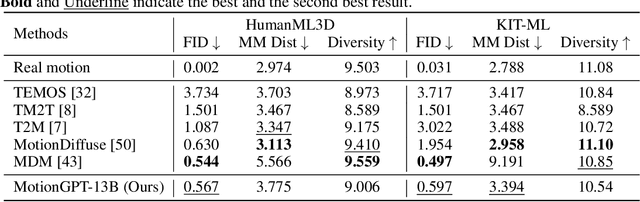
Generating realistic human motion from given action descriptions has experienced significant advancements because of the emerging requirement of digital humans. While recent works have achieved impressive results in generating motion directly from textual action descriptions, they often support only a single modality of the control signal, which limits their application in the real digital human industry. This paper presents a Motion General-Purpose generaTor (MotionGPT) that can use multimodal control signals, e.g., text and single-frame poses, for generating consecutive human motions by treating multimodal signals as special input tokens in large language models (LLMs). Specifically, we first quantize multimodal control signals into discrete codes and then formulate them in a unified prompt instruction to ask the LLMs to generate the motion answer. Our MotionGPT demonstrates a unified human motion generation model with multimodal control signals by tuning a mere 0.4% of LLM parameters. To the best of our knowledge, MotionGPT is the first method to generate human motion by multimodal control signals, which we hope can shed light on this new direction. Codes shall be released upon acceptance.
EVOPOSE: A Recursive Transformer For 3D Human Pose Estimation With Kinematic Structure Priors
Jun 16, 2023



Transformer is popular in recent 3D human pose estimation, which utilizes long-term modeling to lift 2D keypoints into the 3D space. However, current transformer-based methods do not fully exploit the prior knowledge of the human skeleton provided by the kinematic structure. In this paper, we propose a novel transformer-based model EvoPose to introduce the human body prior knowledge for 3D human pose estimation effectively. Specifically, a Structural Priors Representation (SPR) module represents human priors as structural features carrying rich body patterns, e.g. joint relationships. The structural features are interacted with 2D pose sequences and help the model to achieve more informative spatiotemporal features. Moreover, a Recursive Refinement (RR) module is applied to refine the 3D pose outputs by utilizing estimated results and further injects human priors simultaneously. Extensive experiments demonstrate the effectiveness of EvoPose which achieves a new state of the art on two most popular benchmarks, Human3.6M and MPI-INF-3DHP.
Serving Recurrent Neural Networks Efficiently with a Spatial Accelerator
Sep 26, 2019
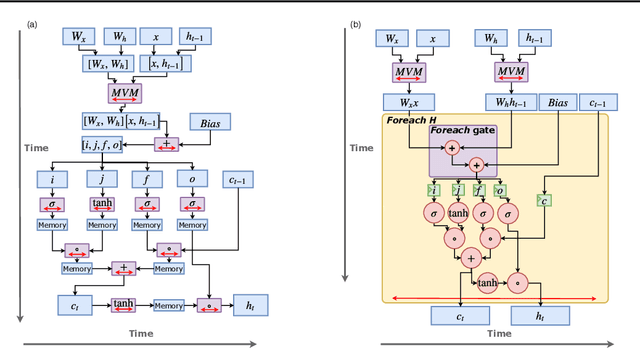

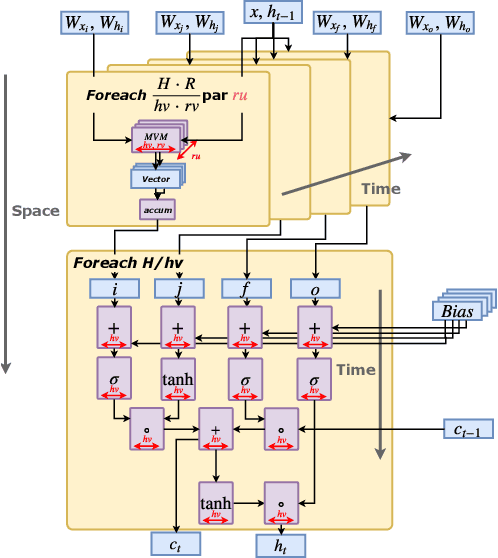
Recurrent Neural Network (RNN) applications form a major class of AI-powered, low-latency data center workloads. Most execution models for RNN acceleration break computation graphs into BLAS kernels, which lead to significant inter-kernel data movement and resource underutilization. We show that by supporting more general loop constructs that capture design parameters in accelerators, it is possible to improve resource utilization using cross-kernel optimization without sacrificing programmability. Such abstraction level enables a design space search that can lead to efficient usage of on-chip resources on a spatial architecture across a range of problem sizes. We evaluate our optimization strategy on such abstraction with DeepBench using a configurable spatial accelerator. We demonstrate that this implementation provides a geometric speedup of 30x in performance, 1.6x in area, and 2x in power efficiency compared to a Tesla V100 GPU, and a geometric speedup of 2x compared to Microsoft Brainwave implementation on a Stratix 10 FPGA.