 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongR: Unleashing Long-Context Reasoning via Reinforcement Learning with Dense Utility Rewards
Feb 05, 2026Reinforcement Learning has emerged as a key driver for LLM reasoning. This capability is equally pivotal in long-context scenarios--such as long-dialogue understanding and structured data analysis, where the challenge extends beyond consuming tokens to performing rigorous deduction. While existing efforts focus on data synthesis or architectural changes, recent work points out that relying solely on sparse, outcome-only rewards yields limited gains, as such coarse signals are often insufficient to effectively guide the complex long-context reasoning. To address this, we propose LongR, a unified framework that enhances long-context performance by integrating a dynamic "Think-and-Read" mechanism, which interleaves reasoning with document consultation, with a contextual density reward based on relative information gain to quantify the utility of the relevant documents. Empirically, LongR achieves a 9% gain on LongBench v2 and consistent improvements on RULER and InfiniteBench, demonstrating robust efficiency in navigating extensive contexts. Furthermore, LongR consistently enhances performance across diverse RL algorithms (e.g., DAPO, GSPO). Finally, we conduct in-depth analyses to investigate the impact of reasoning chain length on efficiency and the model's robustness against distractors.
AutoGPS: Automated Geometry Problem Solving via Multimodal Formalization and Deductive Reasoning
May 29, 2025Geometry problem solving presents distinctive challenges in artificial intelligence, requiring exceptional multimodal comprehension and rigorous mathematical reasoning capabilities. Existing approaches typically fall into two categories: neural-based and symbolic-based methods, both of which exhibit limitations in reliability and interpretability. To address this challenge, we propose AutoGPS, a neuro-symbolic collaborative framework that solves geometry problems with concise, reliable, and human-interpretable reasoning processes. Specifically, AutoGPS employs a Multimodal Problem Formalizer (MPF) and a Deductive Symbolic Reasoner (DSR). The MPF utilizes neural cross-modal comprehension to translate geometry problems into structured formal language representations, with feedback from DSR collaboratively. The DSR takes the formalization as input and formulates geometry problem solving as a hypergraph expansion task, executing mathematically rigorous and reliable derivation to produce minimal and human-readable stepwise solutions. Extensive experimental evaluations demonstrate that AutoGPS achieves state-of-the-art performance on benchmark datasets. Furthermore, human stepwise-reasoning evaluation confirms AutoGPS's impressive reliability and interpretability, with 99\% stepwise logical coherence. The project homepage is at https://jayce-ping.github.io/AutoGPS-homepage.
DecIF: Improving Instruction-Following through Meta-Decomposition
May 20, 2025Instruction-following has emerged as a crucial capability for large language models (LLMs). However, existing approaches often rely on pre-existing documents or external resources to synthesize instruction-following data, which limits their flexibility and generalizability. In this paper, we introduce DecIF, a fully autonomous, meta-decomposition guided framework that generates diverse and high-quality instruction-following data using only LLMs. DecIF is grounded in the principle of decomposition. For instruction generation, we guide LLMs to iteratively produce various types of meta-information, which are then combined with response constraints to form well-structured and semantically rich instructions. We further utilize LLMs to detect and resolve potential inconsistencies within the generated instructions. Regarding response generation, we decompose each instruction into atomic-level evaluation criteria, enabling rigorous validation and the elimination of inaccurate instruction-response pairs. Extensive experiments across a wide range of scenarios and settings demonstrate DecIF's superior performance on instruction-following tasks. Further analysis highlights its strong flexibility, scalability, and generalizability in automatically synthesizing high-quality instruction data.
LongDPO: Unlock Better Long-form Generation Abilities for LLMs via Critique-augmented Stepwise Information
Feb 04, 2025



Long-form generation is crucial for academic writing papers and repo-level code generation. Despite this, current models, including GPT-4o, still exhibit unsatisfactory performance. Existing methods that utilize preference learning with outcome supervision often fail to provide detailed feedback for extended contexts. This shortcoming can lead to content that does not fully satisfy query requirements, resulting in issues like length deviations, and diminished quality. In this paper, we propose enhancing long-form generation by incorporating process supervision. We employ Monte Carlo Tree Search to gather stepwise preference pairs, utilizing a global memory pool to maintain consistency. To address the issue of suboptimal candidate selection, we integrate external critiques to refine and improve the quality of the preference pairs. Finally, we apply step-level DPO using the collected stepwise preference pairs. Experimental results show that our method improves length and quality on long-form generation benchmarks, with almost lossless performance on general benchmarks across various model backbones.
Delta-CoMe: Training-Free Delta-Compression with Mixed-Precision for Large Language Models
Jun 13, 2024



Fine-tuning is a crucial process for adapting large language models (LLMs) to diverse applications. In certain scenarios, such as multi-tenant serving, deploying multiple LLMs becomes necessary to meet complex demands. Recent studies suggest decomposing a fine-tuned LLM into a base model and corresponding delta weights, which are then compressed using low-rank or low-bit approaches to reduce costs. In this work, we observe that existing low-rank and low-bit compression methods can significantly harm the model performance for task-specific fine-tuned LLMs (e.g., WizardMath for math problems). Motivated by the long-tail distribution of singular values in the delta weights, we propose a delta quantization approach using mixed-precision. This method employs higher-bit representation for singular vectors corresponding to larger singular values. We evaluate our approach on various fine-tuned LLMs, including math LLMs, code LLMs, chat LLMs, and even VLMs. Experimental results demonstrate that our approach performs comparably to full fine-tuned LLMs, surpassing both low-rank and low-bit baselines by a considerable margin. Additionally, we show that our method is compatible with various backbone LLMs, such as Llama-2, Llama-3, and Mistral, highlighting its generalizability.
LoRA-Flow: Dynamic LoRA Fusion for Large Language Models in Generative Tasks
Feb 18, 2024

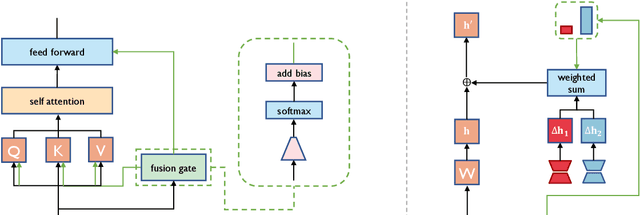
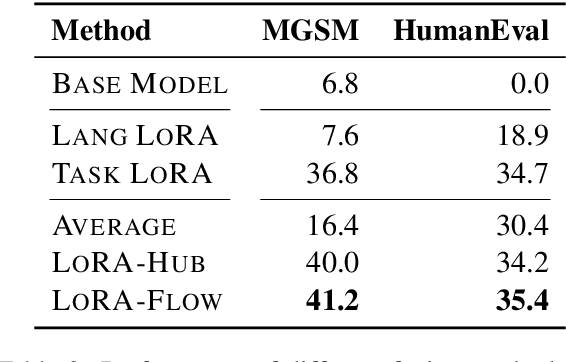
LoRA employs lightweight modules to customize large language models (LLMs) for each downstream task or domain, where different learned additional modules represent diverse skills. Combining existing LoRAs to address new tasks can enhance the reusability of learned LoRAs, particularly beneficial for tasks with limited annotated data. Most prior works on LoRA combination primarily rely on task-level weights for each involved LoRA, making different examples and tokens share the same LoRA weights. However, in generative tasks, different tokens may necessitate diverse skills to manage. Taking the Chinese math task as an example, understanding the problem description may depend more on the Chinese LoRA, while the calculation part may rely more on the math LoRA. To this end, we propose LoRA-Flow, which utilizes dynamic weights to adjust the impact of different LoRAs. The weights at each step are determined by a fusion gate with extremely few parameters, which can be learned with only 200 training examples. Experiments across six generative tasks demonstrate that our method consistently outperforms baselines with task-level fusion weights. This underscores the necessity of introducing dynamic fusion weights for LoRA combination.