 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Reinforcement Learning Control using Conservative Soft Actor-Critic
May 06, 2025Reinforcement Learning (RL) has shown great potential in complex control tasks, particularly when combined with deep neural networks within the Actor-Critic (AC) framework. However, in practical applications, balancing exploration, learning stability, and sample efficiency remains a significant challenge. Traditional methods such as Soft Actor-Critic (SAC) and Proximal Policy Optimization (PPO) address these issues by incorporating entropy or relative entropy regularization, but often face problems of instability and low sample efficiency. In this paper, we propose the Conservative Soft Actor-Critic (CSAC) algorithm, which seamlessly integrates entropy and relative entropy regularization within the AC framework. CSAC improves exploration through entropy regularization while avoiding overly aggressive policy updates with the use of relative entropy regularization. Evaluations on benchmark tasks and real-world robotic simulations demonstrate that CSAC offers significant improvements in stability and efficiency over existing methods. These findings suggest that CSAC provides strong robustness and application potential in control tasks under dynamic environments.
IKSel: Selecting Good Seed Joint Values for Fast Numerical Inverse Kinematics Iterations
Mar 28, 2025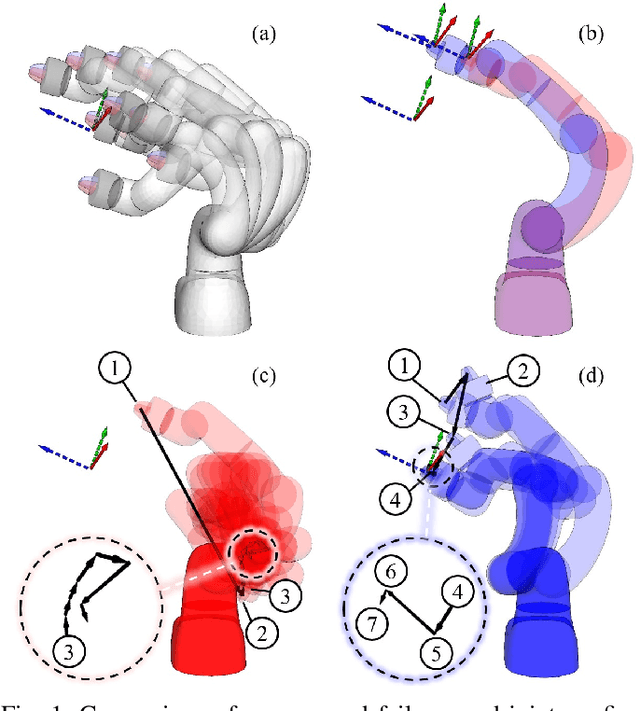
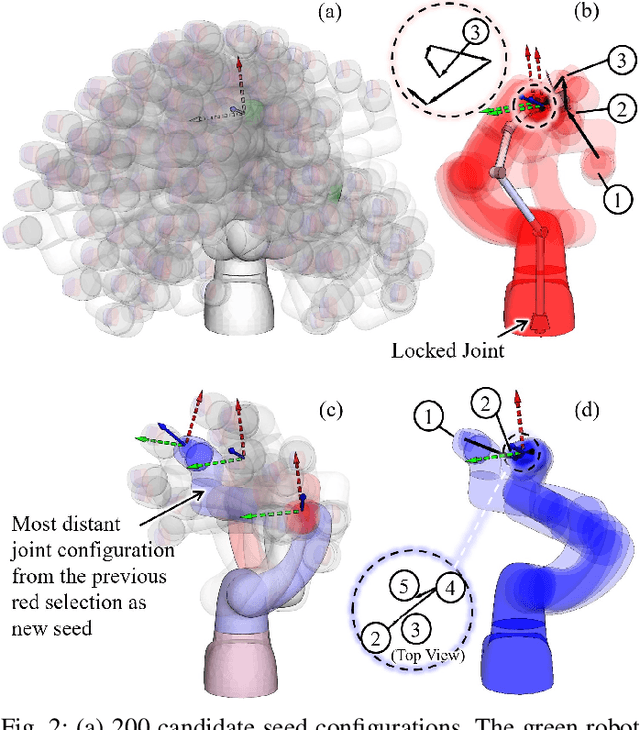
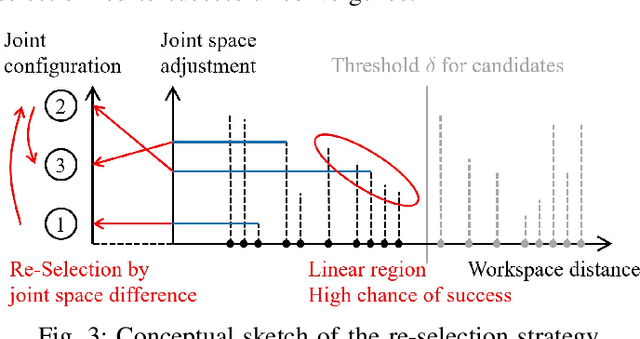
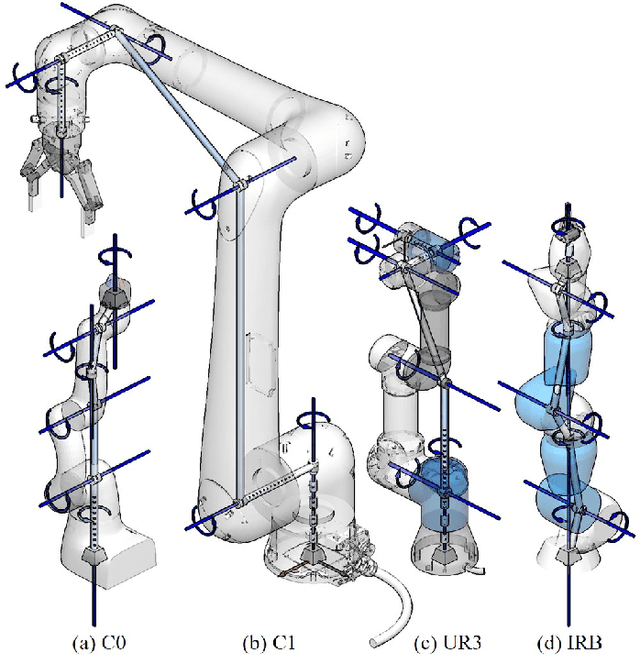
This paper revisits the numerical inverse kinematics (IK) problem, leveraging modern computational resources and refining the seed selection process to develop a solver that is competitive with analytical-based methods. The proposed seed selection strategy consists of three key stages: (1) utilizing a K-Dimensional Tree (KDTree) to identify seed candidates based on workspace proximity, (2) sorting candidates by joint space adjustment and attempting numerical iterations with the one requiring minimal adjustment, and (3) re-selecting the most distant joint configurations for new attempts in case of failures. The joint space adjustment-based seed selection increases the likelihood of rapid convergence, while the re-attempt strategy effectively helps circumvent local minima and joint limit constraints. Comparison results with both traditional numerical solvers and learning-based methods demonstrate the strengths of the proposed approach in terms of success rate, time efficiency, and accuracy. Additionally, we conduct detailed ablation studies to analyze the effects of various parameters and solver settings, providing practical insights for customization and optimization. The proposed method consistently exhibits high success rates and computational efficiency. It is suitable for time-sensitive applications.
Preference Aligned Diffusion Planner for Quadrupedal Locomotion Control
Oct 17, 2024



Diffusion models demonstrate superior performance in capturing complex distributions from large-scale datasets, providing a promising solution for quadrupedal locomotion control. However, offline policy is sensitive to Out-of-Distribution (OOD) states due to the limited state coverage in the datasets. In this work, we propose a two-stage learning framework combining offline learning and online preference alignment for legged locomotion control. Through the offline stage, the diffusion planner learns the joint distribution of state-action sequences from expert datasets without using reward labels. Subsequently, we perform the online interaction in the simulation environment based on the trained offline planer, which significantly addresses the OOD issues and improves the robustness. Specifically, we propose a novel weak preference labeling method without the ground-truth reward or human preferences. The proposed method exhibits superior stability and velocity tracking accuracy in pacing, trotting, and bounding gait under both slow- and high-speed scenarios and can perform zero-shot transfer to the real Unitree Go1 robots. The project website for this paper is at https://shangjaven.github.io/preference-aligned-diffusion-legged/.
Information-driven Path Planning for Hybrid Aerial Underwater Vehicles
Apr 08, 2022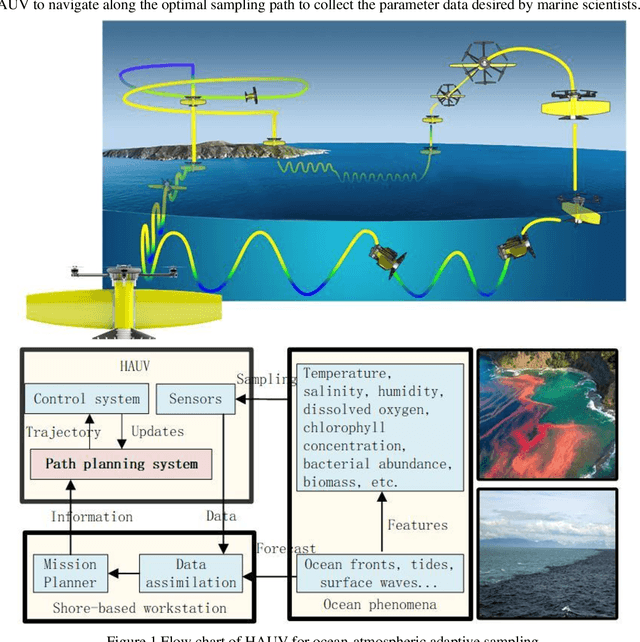
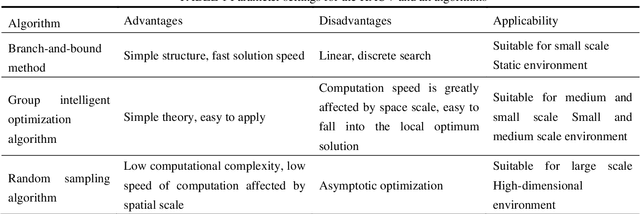

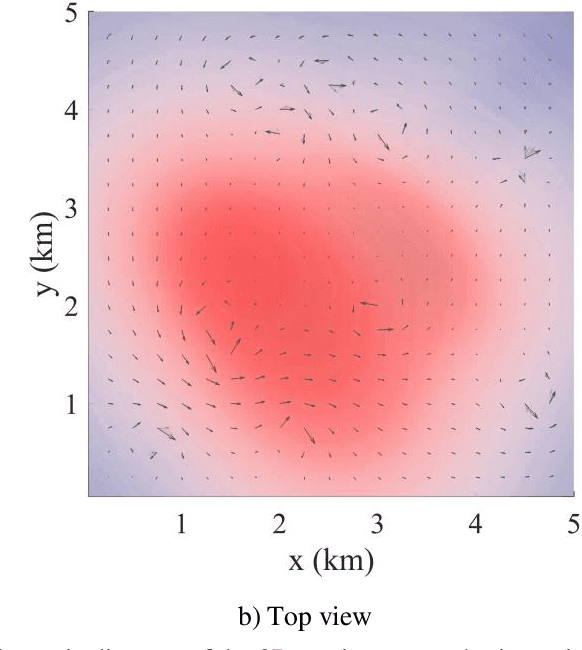
This paper presents a novel Rapidly-exploring Adaptive Sampling Tree (RAST) algorithm for the adaptive sampling mission of a hybrid aerial underwater vehicle (HAUV) in an air-sea 3D environment. This algorithm innovatively combines the tournament-based point selection sampling strategy, the information heuristic search process and the framework of Rapidly-exploring Random Tree (RRT) algorithm. Hence can guide the vehicle to the region of interest to scientists for sampling and generate a collision-free path for maximizing information collection by the HAUV under the constraints of environmental effects of currents or wind and limited budget. The simulation results show that the fast search adaptive sampling tree algorithm has higher optimization performance, faster solution speed and better stability than the Rapidly-exploring Information Gathering Tree (RIGT) algorithm and the particle swarm optimization (PSO) algorithm.