 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence-Based Multiscale Temporal Modeling for Anomaly Detection in Cloud Services
Aug 20, 2025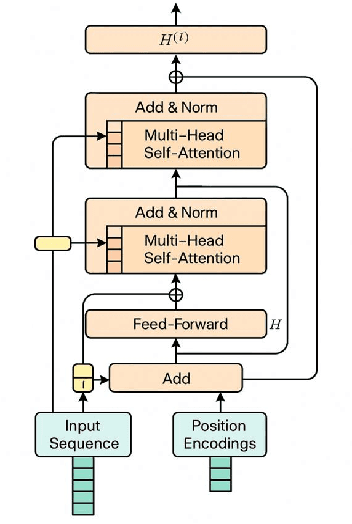
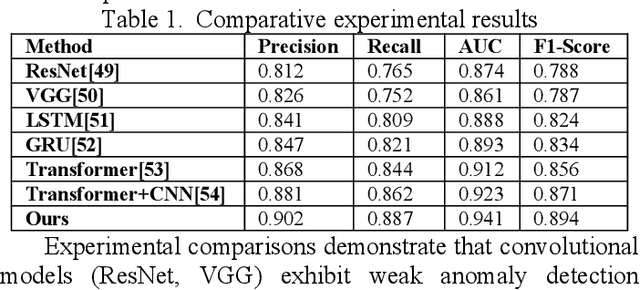
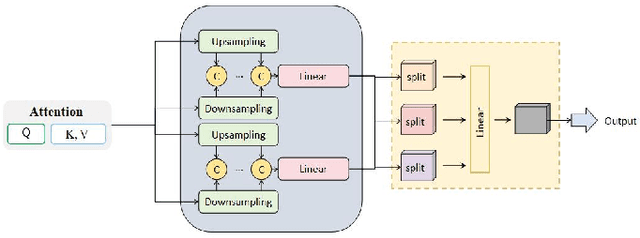
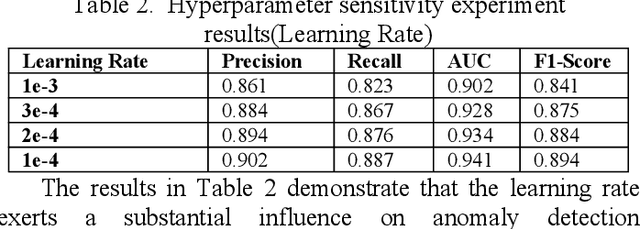
This study proposes an anomaly detection method based on the Transformer architecture with integrated multiscale feature perception, aiming to address the limitations of temporal modeling and scale-aware feature representation in cloud service environments. The method first employs an improved Transformer module to perform temporal modeling on high-dimensional monitoring data, using a self-attention mechanism to capture long-range dependencies and contextual semantics. Then, a multiscale feature construction path is introduced to extract temporal features at different granularities through downsampling and parallel encoding. An attention-weighted fusion module is designed to dynamically adjust the contribution of each scale to the final decision, enhancing the model's robustness in anomaly pattern modeling. In the input modeling stage, standardized multidimensional time series are constructed, covering core signals such as CPU utilization, memory usage, and task scheduling states, while positional encoding is used to strengthen the model's temporal awareness. A systematic experimental setup is designed to evaluate performance, including comparative experiments and hyperparameter sensitivity analysis, focusing on the impact of optimizers, learning rates, anomaly ratios, and noise levels. Experimental results show that the proposed method outperforms mainstream baseline models in key metrics, including precision, recall, AUC, and F1-score, and maintains strong stability and detection performance under various perturbation conditions, demonstrating its superior capability in complex cloud environments.
Semantic and Structural Analysis of Implicit Biases in Large Language Models: An Interpretable Approach
Aug 08, 2025This paper addresses the issue of implicit stereotypes that may arise during the generation process of large language models. It proposes an interpretable bias detection method aimed at identifying hidden social biases in model outputs, especially those semantic tendencies that are not easily captured through explicit linguistic features. The method combines nested semantic representation with a contextual contrast mechanism. It extracts latent bias features from the vector space structure of model outputs. Using attention weight perturbation, it analyzes the model's sensitivity to specific social attribute terms, thereby revealing the semantic pathways through which bias is formed. To validate the effectiveness of the method, this study uses the StereoSet dataset, which covers multiple stereotype dimensions including gender, profession, religion, and race. The evaluation focuses on several key metrics, such as bias detection accuracy, semantic consistency, and contextual sensitivity. Experimental results show that the proposed method achieves strong detection performance across various dimensions. It can accurately identify bias differences between semantically similar texts while maintaining high semantic alignment and output stability. The method also demonstrates high interpretability in its structural design. It helps uncover the internal bias association mechanisms within language models. This provides a more transparent and reliable technical foundation for bias detection. The approach is suitable for real-world applications where high trustworthiness of generated content is required.
Behavioral Anomaly Detection in Distributed Systems via Federated Contrastive Learning
Jun 24, 2025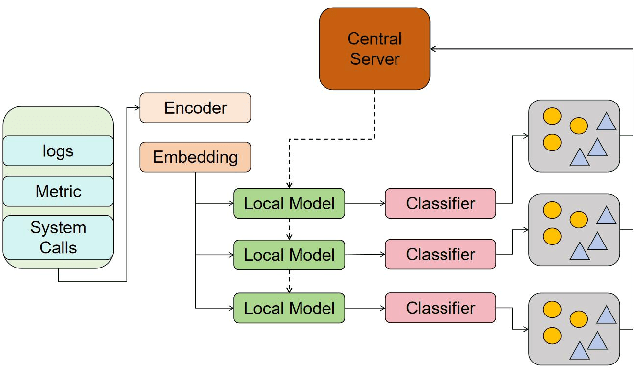
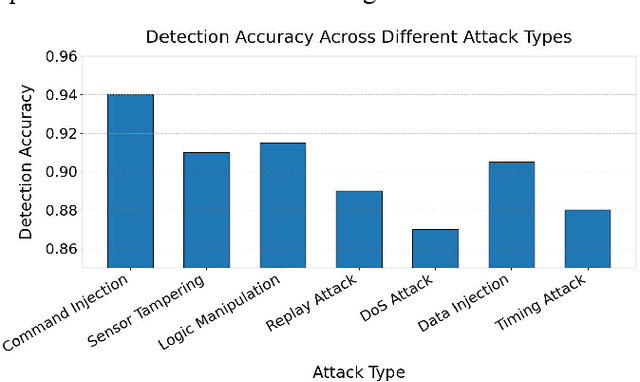
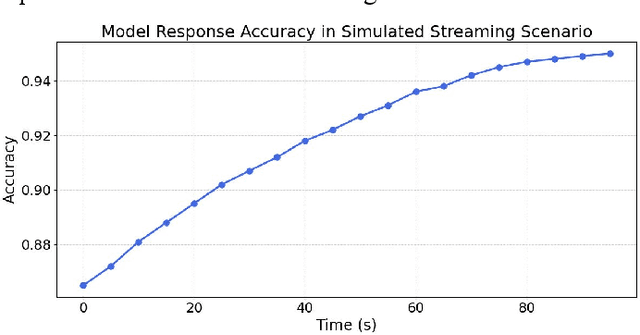
This paper addresses the increasingly prominent problem of anomaly detection in distributed systems. It proposes a detection method based on federated contrastive learning. The goal is to overcome the limitations of traditional centralized approaches in terms of data privacy, node heterogeneity, and anomaly pattern recognition. The proposed method combines the distributed collaborative modeling capabilities of federated learning with the feature discrimination enhancement of contrastive learning. It builds embedding representations on local nodes and constructs positive and negative sample pairs to guide the model in learning a more discriminative feature space. Without exposing raw data, the method optimizes a global model through a federated aggregation strategy. Specifically, the method uses an encoder to represent local behavior data in high-dimensional space. This includes system logs, operational metrics, and system calls. The model is trained using both contrastive loss and classification loss to improve its ability to detect fine-grained anomaly patterns. The method is evaluated under multiple typical attack types. It is also tested in a simulated real-time data stream scenario to examine its responsiveness. Experimental results show that the proposed method outperforms existing approaches across multiple performance metrics. It demonstrates strong detection accuracy and adaptability, effectively addressing complex anomalies in distributed environments. Through careful design of key modules and optimization of the training mechanism, the proposed method achieves a balance between privacy preservation and detection performance. It offers a feasible technical path for intelligent security management in distributed systems.
CommonIT: Commonality-Aware Instruction Tuning for Large Language Models via Data Partitions
Oct 04, 2024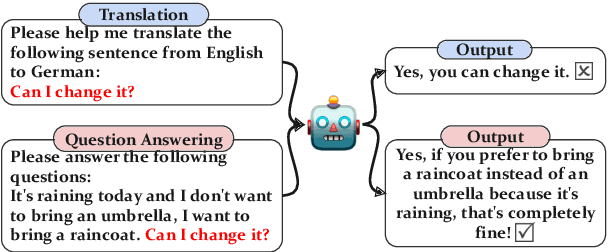
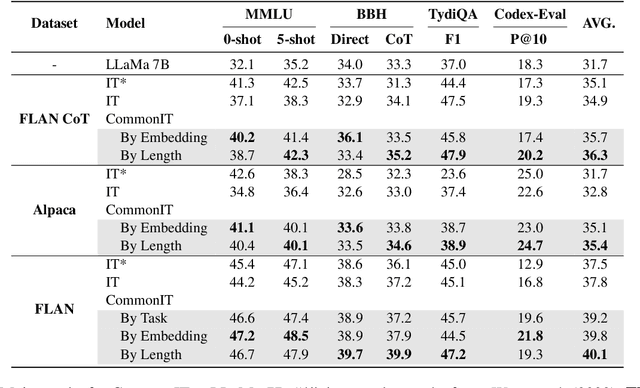
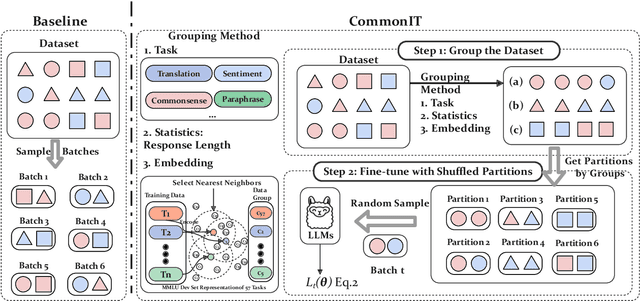
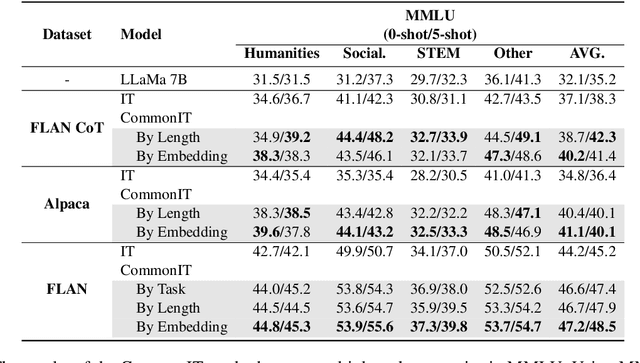
With instruction tuning, Large Language Models (LLMs) can enhance their ability to adhere to commands. Diverging from most works focusing on data mixing, our study concentrates on enhancing the model's capabilities from the perspective of data sampling during training. Drawing inspiration from the human learning process, where it is generally easier to master solutions to similar topics through focused practice on a single type of topic, we introduce a novel instruction tuning strategy termed CommonIT: Commonality-aware Instruction Tuning. Specifically, we cluster instruction datasets into distinct groups with three proposed metrics (Task, Embedding and Length). We ensure each training mini-batch, or "partition", consists solely of data from a single group, which brings about both data randomness across mini-batches and intra-batch data similarity. Rigorous testing on LLaMa models demonstrates CommonIT's effectiveness in enhancing the instruction-following capabilities of LLMs through IT datasets (FLAN, CoT, and Alpaca) and models (LLaMa2-7B, Qwen2-7B, LLaMa 13B, and BLOOM 7B). CommonIT consistently boosts an average improvement of 2.1\% on the general domain (i.e., the average score of Knowledge, Reasoning, Multilinguality and Coding) with the Length metric, and 5.2\% on the special domain (i.e., GSM, Openfunctions and Code) with the Task metric, and 3.8\% on the specific tasks (i.e., MMLU) with the Embedding metric. Code is available at \url{https://github.com/raojay7/CommonIT}.
Information-driven Path Planning for Hybrid Aerial Underwater Vehicles
Apr 08, 2022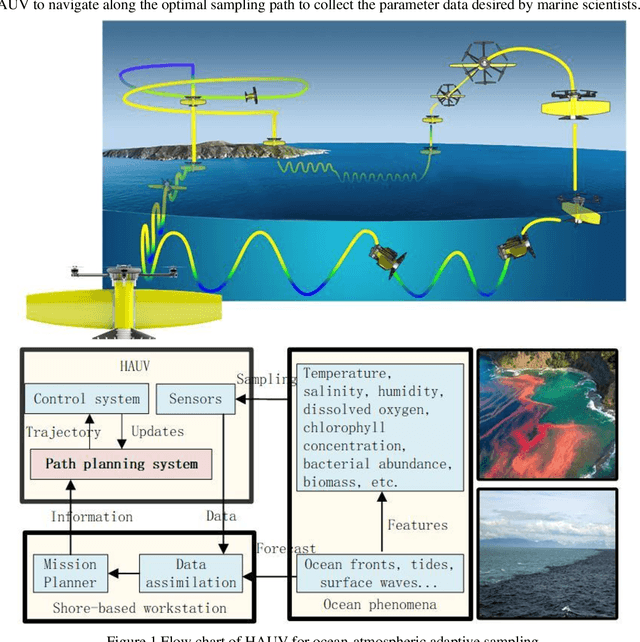
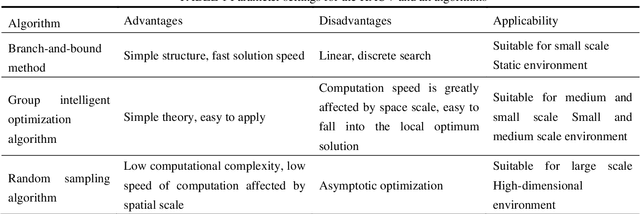

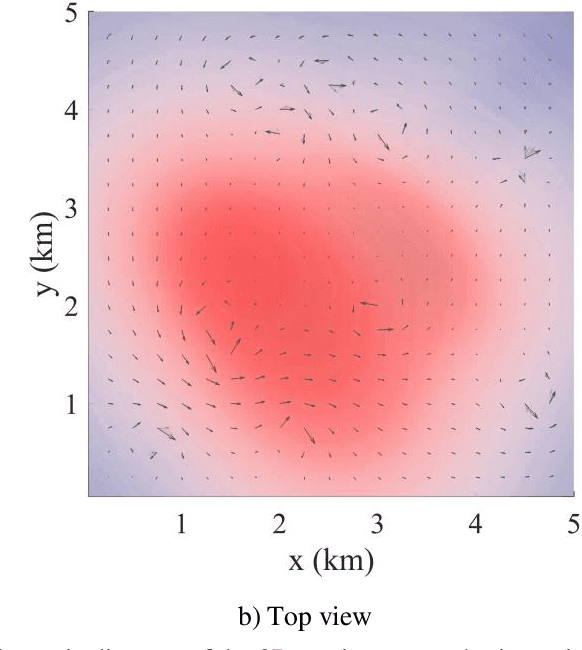
This paper presents a novel Rapidly-exploring Adaptive Sampling Tree (RAST) algorithm for the adaptive sampling mission of a hybrid aerial underwater vehicle (HAUV) in an air-sea 3D environment. This algorithm innovatively combines the tournament-based point selection sampling strategy, the information heuristic search process and the framework of Rapidly-exploring Random Tree (RRT) algorithm. Hence can guide the vehicle to the region of interest to scientists for sampling and generate a collision-free path for maximizing information collection by the HAUV under the constraints of environmental effects of currents or wind and limited budget. The simulation results show that the fast search adaptive sampling tree algorithm has higher optimization performance, faster solution speed and better stability than the Rapidly-exploring Information Gathering Tree (RIGT) algorithm and the particle swarm optimization (PSO) algorithm.