 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonIT: Commonality-Aware Instruction Tuning for Large Language Models via Data Partitions
Paper and Code
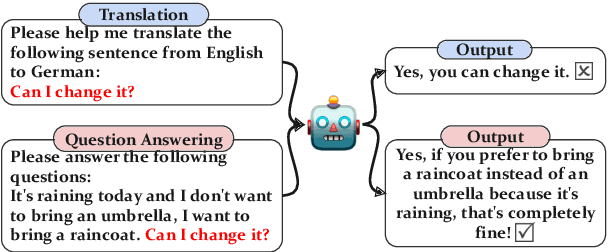
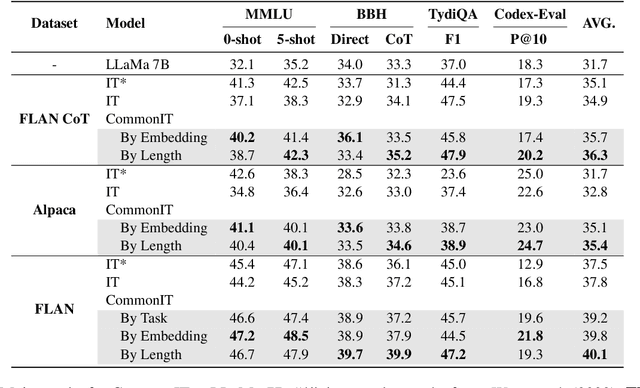
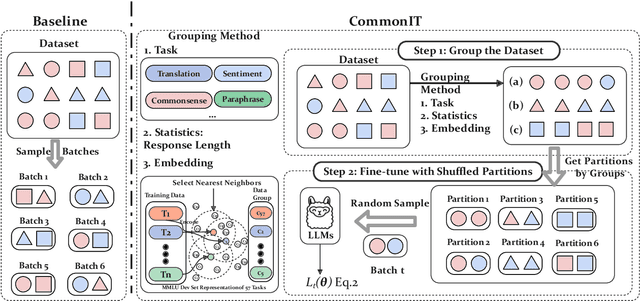
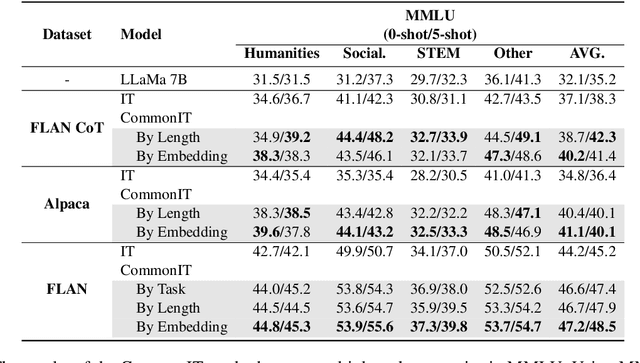
With instruction tuning, Large Language Models (LLMs) can enhance their ability to adhere to commands. Diverging from most works focusing on data mixing, our study concentrates on enhancing the model's capabilities from the perspective of data sampling during training. Drawing inspiration from the human learning process, where it is generally easier to master solutions to similar topics through focused practice on a single type of topic, we introduce a novel instruction tuning strategy termed CommonIT: Commonality-aware Instruction Tuning. Specifically, we cluster instruction datasets into distinct groups with three proposed metrics (Task, Embedding and Length). We ensure each training mini-batch, or "partition", consists solely of data from a single group, which brings about both data randomness across mini-batches and intra-batch data similarity. Rigorous testing on LLaMa models demonstrates CommonIT's effectiveness in enhancing the instruction-following capabilities of LLMs through IT datasets (FLAN, CoT, and Alpaca) and models (LLaMa2-7B, Qwen2-7B, LLaMa 13B, and BLOOM 7B). CommonIT consistently boosts an average improvement of 2.1\% on the general domain (i.e., the average score of Knowledge, Reasoning, Multilinguality and Coding) with the Length metric, and 5.2\% on the special domain (i.e., GSM, Openfunctions and Code) with the Task metric, and 3.8\% on the specific tasks (i.e., MMLU) with the Embedding metric. Code is available at \url{https://github.com/raojay7/CommonIT}.