 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
CommonIT: Commonality-Aware Instruction Tuning for Large Language Models via Data Partitions
Oct 04, 2024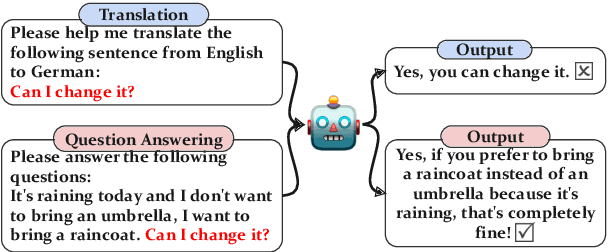
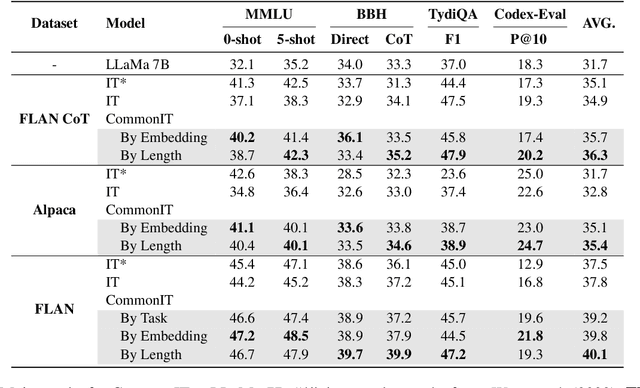
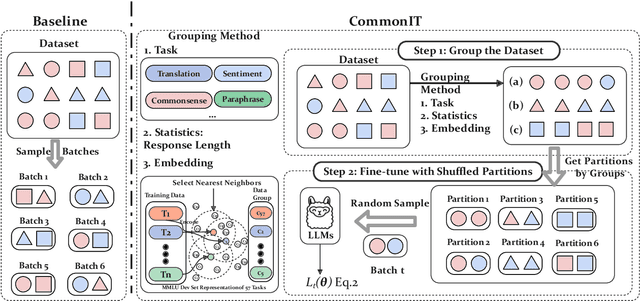
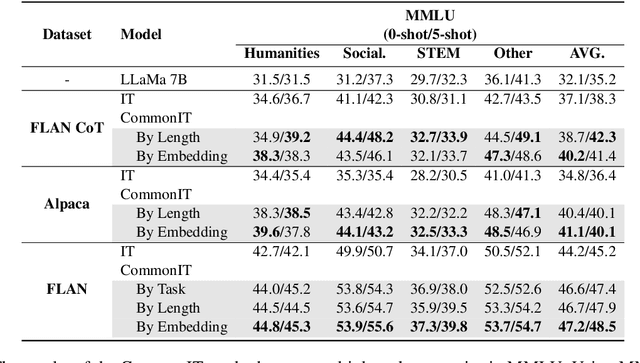
With instruction tuning, Large Language Models (LLMs) can enhance their ability to adhere to commands. Diverging from most works focusing on data mixing, our study concentrates on enhancing the model's capabilities from the perspective of data sampling during training. Drawing inspiration from the human learning process, where it is generally easier to master solutions to similar topics through focused practice on a single type of topic, we introduce a novel instruction tuning strategy termed CommonIT: Commonality-aware Instruction Tuning. Specifically, we cluster instruction datasets into distinct groups with three proposed metrics (Task, Embedding and Length). We ensure each training mini-batch, or "partition", consists solely of data from a single group, which brings about both data randomness across mini-batches and intra-batch data similarity. Rigorous testing on LLaMa models demonstrates CommonIT's effectiveness in enhancing the instruction-following capabilities of LLMs through IT datasets (FLAN, CoT, and Alpaca) and models (LLaMa2-7B, Qwen2-7B, LLaMa 13B, and BLOOM 7B). CommonIT consistently boosts an average improvement of 2.1\% on the general domain (i.e., the average score of Knowledge, Reasoning, Multilinguality and Coding) with the Length metric, and 5.2\% on the special domain (i.e., GSM, Openfunctions and Code) with the Task metric, and 3.8\% on the specific tasks (i.e., MMLU) with the Embedding metric. Code is available at \url{https://github.com/raojay7/CommonIT}.