 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFutureX-Pro: Extending Future Prediction to High-Value Vertical Domains
Jan 18, 2026Building upon FutureX, which established a live benchmark for general-purpose future prediction, this report introduces FutureX-Pro, including FutureX-Finance, FutureX-Retail, FutureX-PublicHealth, FutureX-NaturalDisaster, and FutureX-Search. These together form a specialized framework extending agentic future prediction to high-value vertical domains. While generalist agents demonstrate proficiency in open-domain search, their reliability in capital-intensive and safety-critical sectors remains under-explored. FutureX-Pro targets four economically and socially pivotal verticals: Finance, Retail, Public Health, and Natural Disaster. We benchmark agentic Large Language Models (LLMs) on entry-level yet foundational prediction tasks -- ranging from forecasting market indicators and supply chain demands to tracking epidemic trends and natural disasters. By adapting the contamination-free, live-evaluation pipeline of FutureX, we assess whether current State-of-the-Art (SOTA) agentic LLMs possess the domain grounding necessary for industrial deployment. Our findings reveal the performance gap between generalist reasoning and the precision required for high-value vertical applications.
BoxSeg: Quality-Aware and Peer-Assisted Learning for Box-supervised Instance Segmentation
Apr 07, 2025Box-supervised instance segmentation methods aim to achieve instance segmentation with only box annotations. Recent methods have demonstrated the effectiveness of acquiring high-quality pseudo masks under the teacher-student framework. Building upon this foundation, we propose a BoxSeg framework involving two novel and general modules named the Quality-Aware Module (QAM) and the Peer-assisted Copy-paste (PC). The QAM obtains high-quality pseudo masks and better measures the mask quality to help reduce the effect of noisy masks, by leveraging the quality-aware multi-mask complementation mechanism. The PC imitates Peer-Assisted Learning to further improve the quality of the low-quality masks with the guidance of the obtained high-quality pseudo masks. Theoretical and experimental analyses demonstrate the proposed QAM and PC are effective. Extensive experimental results show the superiority of our BoxSeg over the state-of-the-art methods, and illustrate the QAM and PC can be applied to improve other models.
MatchDet: A Collaborative Framework for Image Matching and Object Detection
Dec 18, 2023Image matching and object detection are two fundamental and challenging tasks, while many related applications consider them two individual tasks (i.e. task-individual). In this paper, a collaborative framework called MatchDet (i.e. task-collaborative) is proposed for image matching and object detection to obtain mutual improvements. To achieve the collaborative learning of the two tasks, we propose three novel modules, including a Weighted Spatial Attention Module (WSAM) for Detector, and Weighted Attention Module (WAM) and Box Filter for Matcher. Specifically, the WSAM highlights the foreground regions of target image to benefit the subsequent detector, the WAM enhances the connection between the foreground regions of pair images to ensure high-quality matches, and Box Filter mitigates the impact of false matches. We evaluate the approaches on a new benchmark with two datasets called Warp-COCO and miniScanNet. Experimental results show our approaches are effective and achieve competitive improvements.
The Energy Prediction Smart-Meter Dataset: Analysis of Previous Competitions and Beyond
Nov 07, 2023



This paper presents the real-world smart-meter dataset and offers an analysis of solutions derived from the Energy Prediction Technical Challenges, focusing primarily on two key competitions: the IEEE Computational Intelligence Society (IEEE-CIS) Technical Challenge on Energy Prediction from Smart Meter data in 2020 (named EP) and its follow-up challenge at the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) in 2021 (named as XEP). These competitions focus on accurate energy consumption forecasting and the importance of interpretability in understanding the underlying factors. The challenge aims to predict monthly and yearly estimated consumption for households, addressing the accurate billing problem with limited historical smart meter data. The dataset comprises 3,248 smart meters, with varying data availability ranging from a minimum of one month to a year. This paper delves into the challenges, solutions and analysing issues related to the provided real-world smart meter data, developing accurate predictions at the household level, and introducing evaluation criteria for assessing interpretability. Additionally, this paper discusses aspects beyond the competitions: opportunities for energy disaggregation and pattern detection applications at the household level, significance of communicating energy-driven factors for optimised billing, and emphasising the importance of responsible AI and data privacy considerations. These aspects provide insights into the broader implications and potential advancements in energy consumption prediction. Overall, these competitions provide a dataset for residential energy research and serve as a catalyst for exploring accurate forecasting, enhancing interpretability, and driving progress towards the discussion of various aspects such as energy disaggregation, demand response programs or behavioural interventions.
Clustered-patch Element Connection for Few-shot Learning
Apr 20, 2023



Weak feature representation problem has influenced the performance of few-shot classification task for a long time. To alleviate this problem, recent researchers build connections between support and query instances through embedding patch features to generate discriminative representations. However, we observe that there exists semantic mismatches (foreground/ background) among these local patches, because the location and size of the target object are not fixed. What is worse, these mismatches result in unreliable similarity confidences, and complex dense connection exacerbates the problem. According to this, we propose a novel Clustered-patch Element Connection (CEC) layer to correct the mismatch problem. The CEC layer leverages Patch Cluster and Element Connection operations to collect and establish reliable connections with high similarity patch features, respectively. Moreover, we propose a CECNet, including CEC layer based attention module and distance metric. The former is utilized to generate a more discriminative representation benefiting from the global clustered-patch features, and the latter is introduced to reliably measure the similarity between pair-features. Extensive experiments demonstrate that our CECNet outperforms the state-of-the-art methods on classification benchmark. Furthermore, our CEC approach can be extended into few-shot segmentation and detection tasks, which achieves competitive performances.
SpatialFormer: Semantic and Target Aware Attentions for Few-Shot Learning
Mar 15, 2023Recent Few-Shot Learning (FSL) methods put emphasis on generating a discriminative embedding features to precisely measure the similarity between support and query sets. Current CNN-based cross-attention approaches generate discriminative representations via enhancing the mutually semantic similar regions of support and query pairs. However, it suffers from two problems: CNN structure produces inaccurate attention map based on local features, and mutually similar backgrounds cause distraction. To alleviate these problems, we design a novel SpatialFormer structure to generate more accurate attention regions based on global features. Different from the traditional Transformer modeling intrinsic instance-level similarity which causes accuracy degradation in FSL, our SpatialFormer explores the semantic-level similarity between pair inputs to boost the performance. Then we derive two specific attention modules, named SpatialFormer Semantic Attention (SFSA) and SpatialFormer Target Attention (SFTA), to enhance the target object regions while reduce the background distraction. Particularly, SFSA highlights the regions with same semantic information between pair features, and SFTA finds potential foreground object regions of novel feature that are similar to base categories. Extensive experiments show that our methods are effective and achieve new state-of-the-art results on few-shot classification benchmarks.
Global Meets Local: Effective Multi-Label Image Classification via Category-Aware Weak Supervision
Nov 23, 2022Multi-label image classification, which can be categorized into label-dependency and region-based methods, is a challenging problem due to the complex underlying object layouts. Although region-based methods are less likely to encounter issues with model generalizability than label-dependency methods, they often generate hundreds of meaningless or noisy proposals with non-discriminative information, and the contextual dependency among the localized regions is often ignored or over-simplified. This paper builds a unified framework to perform effective noisy-proposal suppression and to interact between global and local features for robust feature learning. Specifically, we propose category-aware weak supervision to concentrate on non-existent categories so as to provide deterministic information for local feature learning, restricting the local branch to focus on more high-quality regions of interest. Moreover, we develop a cross-granularity attention module to explore the complementary information between global and local features, which can build the high-order feature correlation containing not only global-to-local, but also local-to-local relations. Both advantages guarantee a boost in the performance of the whole network. Extensive experiments on two large-scale datasets (MS-COCO and VOC 2007) demonstrate that our framework achieves superior performance over state-of-the-art methods.
* 12 pages, 10 figures, published in ACMMM 2022
tSF: Transformer-based Semantic Filter for Few-Shot Learning
Nov 02, 2022Few-Shot Learning (FSL) alleviates the data shortage challenge via embedding discriminative target-aware features among plenty seen (base) and few unseen (novel) labeled samples. Most feature embedding modules in recent FSL methods are specially designed for corresponding learning tasks (e.g., classification, segmentation, and object detection), which limits the utility of embedding features. To this end, we propose a light and universal module named transformer-based Semantic Filter (tSF), which can be applied for different FSL tasks. The proposed tSF redesigns the inputs of a transformer-based structure by a semantic filter, which not only embeds the knowledge from whole base set to novel set but also filters semantic features for target category. Furthermore, the parameters of tSF is equal to half of a standard transformer block (less than 1M). In the experiments, our tSF is able to boost the performances in different classic few-shot learning tasks (about 2% improvement), especially outperforms the state-of-the-arts on multiple benchmark datasets in few-shot classification task.
Adaptive Assignment for Geometry Aware Local Feature Matching
Jul 18, 2022
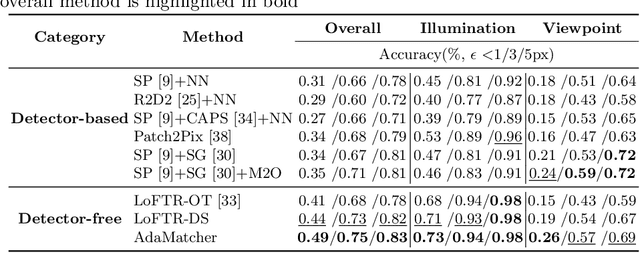
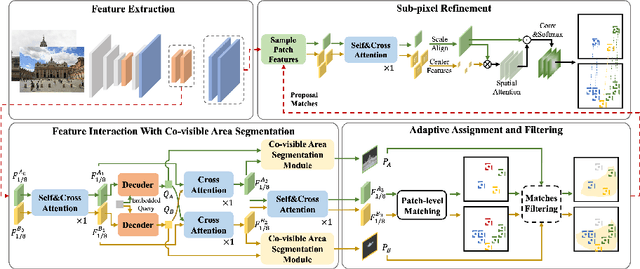
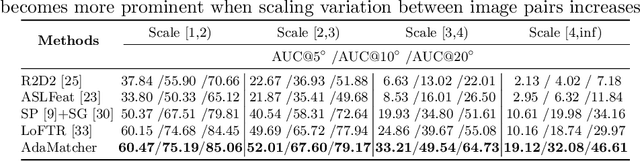
Local image feature matching, aiming to identify and correspond similar regions from image pairs, is an essential concept in computer vision. Most existing image matching approaches follow a one-to-one assignment principle and employ mutual nearest neighbor to guarantee unique correspondence between local features across images. However, images from different conditions may hold large-scale variations or viewpoint diversification so that one-to-one assignment may cause ambiguous or missing representations in dense matching. In this paper, we introduce AdaMatcher, a novel detector-free local feature matching method, which first correlates dense features by a lightweight feature interaction module and estimates co-visible area of the paired images, then performs a patch-level many-to-one assignment to predict match proposals, and finally refines them based on a one-to-one refinement module. Extensive experiments show that AdaMatcher outperforms solid baselines and achieves state-of-the-art results on many downstream tasks. Additionally, the many-to-one assignment and one-to-one refinement module can be used as a refinement network for other matching methods, such as SuperGlue, to boost their performance further. Code will be available upon publication.
StreamSoNG: A Soft Streaming Classification Approach
Oct 01, 2020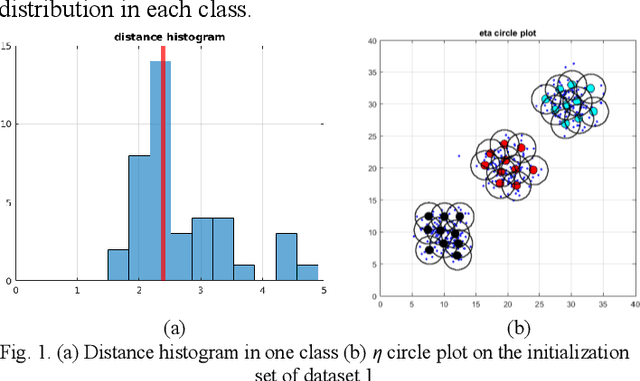
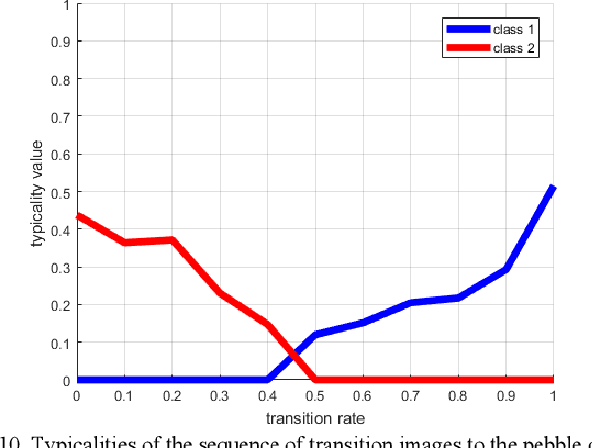
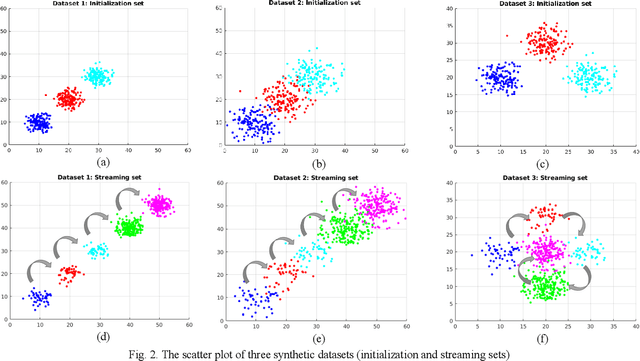
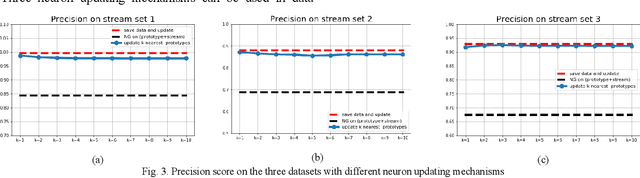
Examining most streaming clustering algorithms leads to the understanding that they are actually incremental classification models. They model existing and newly discovered structures via summary information that we call footprints. Incoming data is normally assigned crisp labels (into one of the structures) and that structure's footprints are incrementally updated. There is no reason that these assignments need to be crisp. In this paper, we propose a new streaming classification algorithm that uses Neural Gas prototypes as footprints and produces a possibilistic label vector (typicalities) for each incoming vector. These typicalities are generated by a modified possibilistic k-nearest neighbor algorithm. The approach is tested on synthetic and real image datasets with excellent results.