 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Classifier for Boosting Few-shot Object Detection and Instance Segmentation
May 20, 2025This paper focus on few-shot object detection~(FSOD) and instance segmentation~(FSIS), which requires a model to quickly adapt to novel classes with a few labeled instances. The existing methods severely suffer from bias classification because of the missing label issue which naturally exists in an instance-level few-shot scenario and is first formally proposed by us. Our analysis suggests that the standard classification head of most FSOD or FSIS models needs to be decoupled to mitigate the bias classification. Therefore, we propose an embarrassingly simple but effective method that decouples the standard classifier into two heads. Then, these two individual heads are capable of independently addressing clear positive samples and noisy negative samples which are caused by the missing label. In this way, the model can effectively learn novel classes while mitigating the effects of noisy negative samples. Without bells and whistles, our model without any additional computation cost and parameters consistently outperforms its baseline and state-of-the-art by a large margin on PASCAL VOC and MS-COCO benchmarks for FSOD and FSIS tasks. The Code is available at https://csgaobb.github.io/Projects/DCFS.
MatchDet: A Collaborative Framework for Image Matching and Object Detection
Dec 18, 2023Image matching and object detection are two fundamental and challenging tasks, while many related applications consider them two individual tasks (i.e. task-individual). In this paper, a collaborative framework called MatchDet (i.e. task-collaborative) is proposed for image matching and object detection to obtain mutual improvements. To achieve the collaborative learning of the two tasks, we propose three novel modules, including a Weighted Spatial Attention Module (WSAM) for Detector, and Weighted Attention Module (WAM) and Box Filter for Matcher. Specifically, the WSAM highlights the foreground regions of target image to benefit the subsequent detector, the WAM enhances the connection between the foreground regions of pair images to ensure high-quality matches, and Box Filter mitigates the impact of false matches. We evaluate the approaches on a new benchmark with two datasets called Warp-COCO and miniScanNet. Experimental results show our approaches are effective and achieve competitive improvements.
HCNet: Hierarchical Context Network for Semantic Segmentation
Oct 20, 2020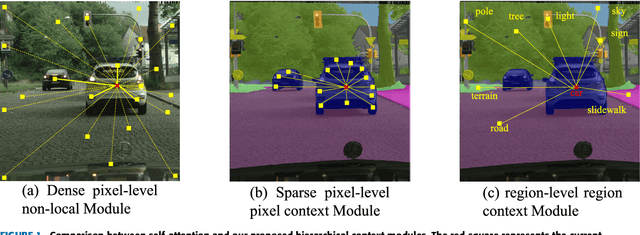


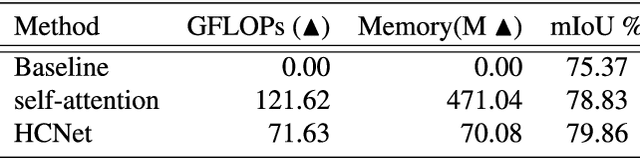
Global context information is vital in visual understanding problems, especially in pixel-level semantic segmentation. The mainstream methods adopt the self-attention mechanism to model global context information. However, pixels belonging to different classes usually have weak feature correlation. Modeling the global pixel-level correlation matrix indiscriminately is extremely redundant in the self-attention mechanism. In order to solve the above problem, we propose a hierarchical context network to differentially model homogeneous pixels with strong correlations and heterogeneous pixels with weak correlations. Specifically, we first propose a multi-scale guided pre-segmentation module to divide the entire feature map into different classed-based homogeneous regions. Within each homogeneous region, we design the pixel context module to capture pixel-level correlations. Subsequently, different from the self-attention mechanism that still models weak heterogeneous correlations in a dense pixel-level manner, the region context module is proposed to model sparse region-level dependencies using a unified representation of each region. Through aggregating fine-grained pixel context features and coarse-grained region context features, our proposed network can not only hierarchically model global context information but also harvest multi-granularity representations to more robustly identify multi-scale objects. We evaluate our approach on Cityscapes and the ISPRS Vaihingen dataset. Without Bells or Whistles, our approach realizes a mean IoU of 82.8% and overall accuracy of 91.4% on Cityscapes and ISPRS Vaihingen test set, achieving state-of-the-art results.