 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionCreator-R1: A Reflection-Enhanced Native Visual-Generation Agentic Model
Mar 09, 2026Visual content generation has advanced from single-image to multi-image workflows, yet existing agents remain largely plan-driven and lack systematic reflection mechanisms to correct mid-trajectory visual errors. To address this limitation, we propose VisionCreator-R1, a native visual generation agent with explicit reflection, together with a Reflection-Plan Co-Optimization (RPCO) training methodology. Through extensive experiments and trajectory-level analysis, we uncover reflection-plan optimization asymmetry in reinforcement learning (RL): planning can be reliably optimized via plan rewards, while reflection learning is hindered by noisy credit assignment. Guided by this insight, our RPCO first trains on the self-constructed VCR-SFT dataset with reflection-strong single-image trajectories and planning-strong multi-image trajectories, then co-optimization on VCR-RL dataset via RL. This yields our unified VisionCreator-R1 agent, which consistently outperforms Gemini2.5Pro on existing benchmarks and our VCR-bench covering single-image and multi-image tasks.
VisionCreator: A Native Visual-Generation Agentic Model with Understanding, Thinking, Planning and Creation
Mar 03, 2026Visual content creation tasks demand a nuanced understanding of design conventions and creative workflows-capabilities challenging for general models, while workflow-based agents lack specialized knowledge for autonomous creative planning. To overcome these challenges, we propose VisionCreator, a native visual-generation agentic model that unifies Understanding, Thinking, Planning, and Creation (UTPC) capabilities within an end-to-end learnable framework. Our work introduces four key contributions: (i) VisGenData-4k and its construction methodology using metacognition-based VisionAgent to generate high-quality creation trajectories with explicit UTPC structures; (ii) The VisionCreator agentic model, optimized through Progressive Specialization Training (PST) and Virtual Reinforcement Learning (VRL) within a high-fidelity simulated environment, enabling stable and efficient acquisition of UTPC capabilities for complex creation tasks; (iii) VisGenBench, a comprehensive benchmark featuring 1.2k test samples across diverse scenarios for standardized evaluation of multi-step visual creation capabilities; (iv) Remarkably, our VisionCreator-8B/32B models demonstrate superior performance over larger closed-source models across multiple evaluation dimensions. Overall, this work provides a foundation for future research in visual-generation agentic systems.
Decoupling Classifier for Boosting Few-shot Object Detection and Instance Segmentation
May 20, 2025This paper focus on few-shot object detection~(FSOD) and instance segmentation~(FSIS), which requires a model to quickly adapt to novel classes with a few labeled instances. The existing methods severely suffer from bias classification because of the missing label issue which naturally exists in an instance-level few-shot scenario and is first formally proposed by us. Our analysis suggests that the standard classification head of most FSOD or FSIS models needs to be decoupled to mitigate the bias classification. Therefore, we propose an embarrassingly simple but effective method that decouples the standard classifier into two heads. Then, these two individual heads are capable of independently addressing clear positive samples and noisy negative samples which are caused by the missing label. In this way, the model can effectively learn novel classes while mitigating the effects of noisy negative samples. Without bells and whistles, our model without any additional computation cost and parameters consistently outperforms its baseline and state-of-the-art by a large margin on PASCAL VOC and MS-COCO benchmarks for FSOD and FSIS tasks. The Code is available at https://csgaobb.github.io/Projects/DCFS.
BoxSeg: Quality-Aware and Peer-Assisted Learning for Box-supervised Instance Segmentation
Apr 07, 2025Box-supervised instance segmentation methods aim to achieve instance segmentation with only box annotations. Recent methods have demonstrated the effectiveness of acquiring high-quality pseudo masks under the teacher-student framework. Building upon this foundation, we propose a BoxSeg framework involving two novel and general modules named the Quality-Aware Module (QAM) and the Peer-assisted Copy-paste (PC). The QAM obtains high-quality pseudo masks and better measures the mask quality to help reduce the effect of noisy masks, by leveraging the quality-aware multi-mask complementation mechanism. The PC imitates Peer-Assisted Learning to further improve the quality of the low-quality masks with the guidance of the obtained high-quality pseudo masks. Theoretical and experimental analyses demonstrate the proposed QAM and PC are effective. Extensive experimental results show the superiority of our BoxSeg over the state-of-the-art methods, and illustrate the QAM and PC can be applied to improve other models.
Spider: Any-to-Many Multimodal LLM
Nov 14, 2024



Multimodal LLMs (MLLMs) have emerged as an extension of Large Language Models (LLMs), enabling the integration of various modalities. However, Any-to-Any MLLMs are limited to generating pairwise modalities 'Text + X' within a single response, such as Text + {Image or Audio or Video}. To address this limitation, we introduce Spider, a novel efficient Any-to-Many Modalities Generation (AMMG) framework, which can generate an arbitrary combination of modalities 'Text + Xs', such as Text + {Image and Audio and Video}. To achieve efficient AMMG, our Spider integrates three core components: a Base Model for basic X-to-X (i.e., Any-to-Any) modality processing, a novel Efficient Decoders-Controller for controlling multimodal Decoders to generate Xs (many-modal) contents, and an Any-to-Many Instruction Template designed for producing Xs signal prompts. To train Spider, we constructed a novel Text-formatted Many-Modal (TMM) dataset, which facilitates the learning of the X-to-Xs (i.e., Any-to-Many) capability necessary for AMMG. Ultimately, the well-trained Spider generates a pseudo X-to-Xs dataset, the first-ever X-to-Xs many-modal dataset, enhancing the potential for AMMG task in future research. Overall, this work not only pushes the boundary of multimodal interaction but also provides rich data support for advancing the field.
Enhancing Multi-Class Anomaly Detection via Diffusion Refinement with Dual Conditioning
Jul 02, 2024Anomaly detection, the technique of identifying abnormal samples using only normal samples, has attracted widespread interest in industry. Existing one-model-per-category methods often struggle with limited generalization capabilities due to their focus on a single category, and can fail when encountering variations in product. Recent feature reconstruction methods, as representatives in one-model-all-categories schemes, face challenges including reconstructing anomalous samples and blurry reconstructions. In this paper, we creatively combine a diffusion model and a transformer for multi-class anomaly detection. This approach leverages diffusion to obtain high-frequency information for refinement, greatly alleviating the blurry reconstruction problem while maintaining the sampling efficiency of the reverse diffusion process. The task is transformed into image inpainting to disconnect the input-output correlation, thereby mitigating the "identical shortcuts" problem and avoiding the model from reconstructing anomalous samples. Besides, we introduce category-awareness using dual conditioning to ensure the accuracy of prediction and reconstruction in the reverse diffusion process, preventing excessive deviation from the target category, thus effectively enabling multi-class anomaly detection. Futhermore, Spatio-temporal fusion is also employed to fuse heatmaps predicted at different timesteps and scales, enhancing the performance of multi-class anomaly detection. Extensive experiments on benchmark datasets demonstrate the superior performance and exceptional multi-class anomaly detection capabilities of our proposed method compared to others.
MatchDet: A Collaborative Framework for Image Matching and Object Detection
Dec 18, 2023Image matching and object detection are two fundamental and challenging tasks, while many related applications consider them two individual tasks (i.e. task-individual). In this paper, a collaborative framework called MatchDet (i.e. task-collaborative) is proposed for image matching and object detection to obtain mutual improvements. To achieve the collaborative learning of the two tasks, we propose three novel modules, including a Weighted Spatial Attention Module (WSAM) for Detector, and Weighted Attention Module (WAM) and Box Filter for Matcher. Specifically, the WSAM highlights the foreground regions of target image to benefit the subsequent detector, the WAM enhances the connection between the foreground regions of pair images to ensure high-quality matches, and Box Filter mitigates the impact of false matches. We evaluate the approaches on a new benchmark with two datasets called Warp-COCO and miniScanNet. Experimental results show our approaches are effective and achieve competitive improvements.
Clustered-patch Element Connection for Few-shot Learning
Apr 20, 2023



Weak feature representation problem has influenced the performance of few-shot classification task for a long time. To alleviate this problem, recent researchers build connections between support and query instances through embedding patch features to generate discriminative representations. However, we observe that there exists semantic mismatches (foreground/ background) among these local patches, because the location and size of the target object are not fixed. What is worse, these mismatches result in unreliable similarity confidences, and complex dense connection exacerbates the problem. According to this, we propose a novel Clustered-patch Element Connection (CEC) layer to correct the mismatch problem. The CEC layer leverages Patch Cluster and Element Connection operations to collect and establish reliable connections with high similarity patch features, respectively. Moreover, we propose a CECNet, including CEC layer based attention module and distance metric. The former is utilized to generate a more discriminative representation benefiting from the global clustered-patch features, and the latter is introduced to reliably measure the similarity between pair-features. Extensive experiments demonstrate that our CECNet outperforms the state-of-the-art methods on classification benchmark. Furthermore, our CEC approach can be extended into few-shot segmentation and detection tasks, which achieves competitive performances.
SpatialFormer: Semantic and Target Aware Attentions for Few-Shot Learning
Mar 15, 2023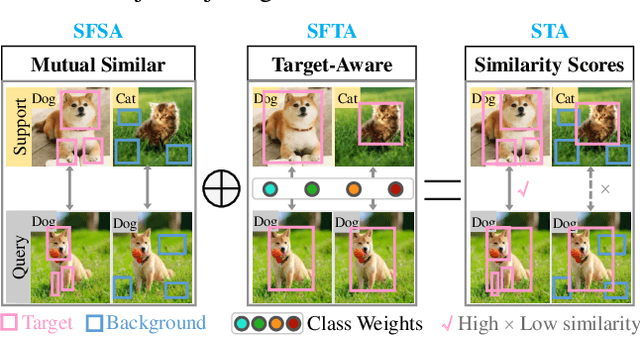

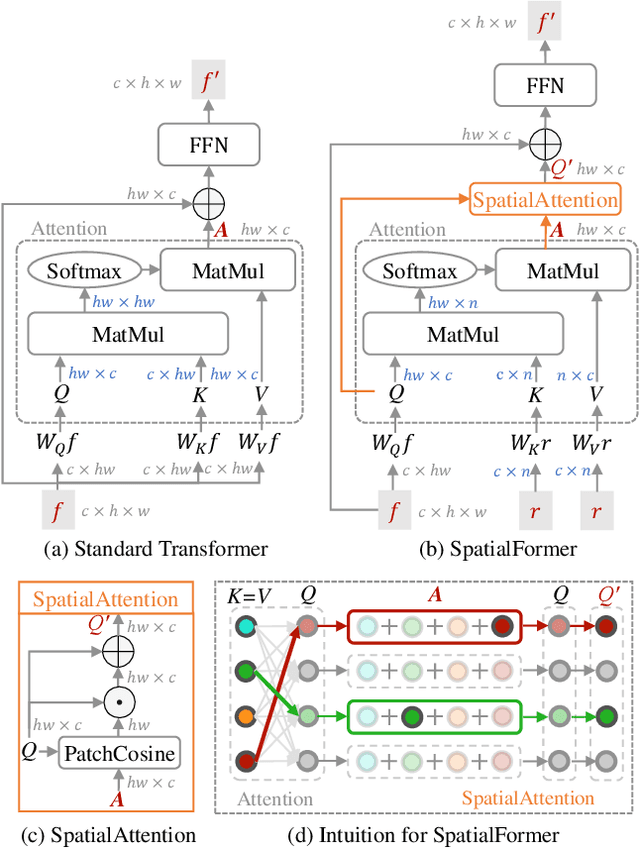

Recent Few-Shot Learning (FSL) methods put emphasis on generating a discriminative embedding features to precisely measure the similarity between support and query sets. Current CNN-based cross-attention approaches generate discriminative representations via enhancing the mutually semantic similar regions of support and query pairs. However, it suffers from two problems: CNN structure produces inaccurate attention map based on local features, and mutually similar backgrounds cause distraction. To alleviate these problems, we design a novel SpatialFormer structure to generate more accurate attention regions based on global features. Different from the traditional Transformer modeling intrinsic instance-level similarity which causes accuracy degradation in FSL, our SpatialFormer explores the semantic-level similarity between pair inputs to boost the performance. Then we derive two specific attention modules, named SpatialFormer Semantic Attention (SFSA) and SpatialFormer Target Attention (SFTA), to enhance the target object regions while reduce the background distraction. Particularly, SFSA highlights the regions with same semantic information between pair features, and SFTA finds potential foreground object regions of novel feature that are similar to base categories. Extensive experiments show that our methods are effective and achieve new state-of-the-art results on few-shot classification benchmarks.
tSF: Transformer-based Semantic Filter for Few-Shot Learning
Nov 02, 2022Few-Shot Learning (FSL) alleviates the data shortage challenge via embedding discriminative target-aware features among plenty seen (base) and few unseen (novel) labeled samples. Most feature embedding modules in recent FSL methods are specially designed for corresponding learning tasks (e.g., classification, segmentation, and object detection), which limits the utility of embedding features. To this end, we propose a light and universal module named transformer-based Semantic Filter (tSF), which can be applied for different FSL tasks. The proposed tSF redesigns the inputs of a transformer-based structure by a semantic filter, which not only embeds the knowledge from whole base set to novel set but also filters semantic features for target category. Furthermore, the parameters of tSF is equal to half of a standard transformer block (less than 1M). In the experiments, our tSF is able to boost the performances in different classic few-shot learning tasks (about 2% improvement), especially outperforms the state-of-the-arts on multiple benchmark datasets in few-shot classification task.