 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCNet: Hierarchical Context Network for Semantic Segmentation
Oct 20, 2020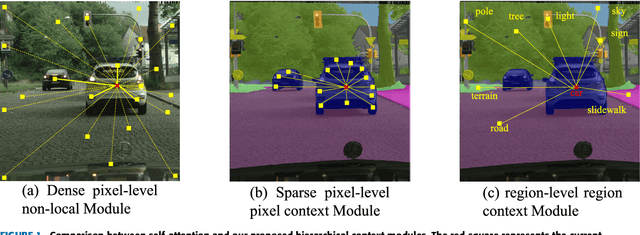


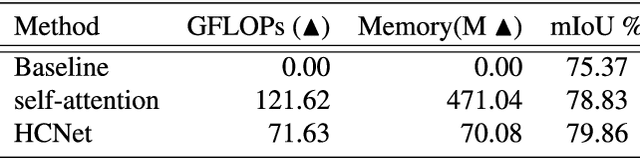
Global context information is vital in visual understanding problems, especially in pixel-level semantic segmentation. The mainstream methods adopt the self-attention mechanism to model global context information. However, pixels belonging to different classes usually have weak feature correlation. Modeling the global pixel-level correlation matrix indiscriminately is extremely redundant in the self-attention mechanism. In order to solve the above problem, we propose a hierarchical context network to differentially model homogeneous pixels with strong correlations and heterogeneous pixels with weak correlations. Specifically, we first propose a multi-scale guided pre-segmentation module to divide the entire feature map into different classed-based homogeneous regions. Within each homogeneous region, we design the pixel context module to capture pixel-level correlations. Subsequently, different from the self-attention mechanism that still models weak heterogeneous correlations in a dense pixel-level manner, the region context module is proposed to model sparse region-level dependencies using a unified representation of each region. Through aggregating fine-grained pixel context features and coarse-grained region context features, our proposed network can not only hierarchically model global context information but also harvest multi-granularity representations to more robustly identify multi-scale objects. We evaluate our approach on Cityscapes and the ISPRS Vaihingen dataset. Without Bells or Whistles, our approach realizes a mean IoU of 82.8% and overall accuracy of 91.4% on Cityscapes and ISPRS Vaihingen test set, achieving state-of-the-art results.