 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Energy Prediction Smart-Meter Dataset: Analysis of Previous Competitions and Beyond
Nov 07, 2023



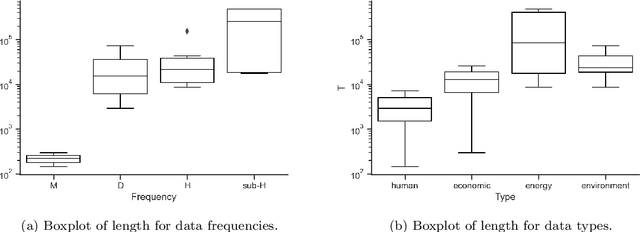
This paper presents the real-world smart-meter dataset and offers an analysis of solutions derived from the Energy Prediction Technical Challenges, focusing primarily on two key competitions: the IEEE Computational Intelligence Society (IEEE-CIS) Technical Challenge on Energy Prediction from Smart Meter data in 2020 (named EP) and its follow-up challenge at the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) in 2021 (named as XEP). These competitions focus on accurate energy consumption forecasting and the importance of interpretability in understanding the underlying factors. The challenge aims to predict monthly and yearly estimated consumption for households, addressing the accurate billing problem with limited historical smart meter data. The dataset comprises 3,248 smart meters, with varying data availability ranging from a minimum of one month to a year. This paper delves into the challenges, solutions and analysing issues related to the provided real-world smart meter data, developing accurate predictions at the household level, and introducing evaluation criteria for assessing interpretability. Additionally, this paper discusses aspects beyond the competitions: opportunities for energy disaggregation and pattern detection applications at the household level, significance of communicating energy-driven factors for optimised billing, and emphasising the importance of responsible AI and data privacy considerations. These aspects provide insights into the broader implications and potential advancements in energy consumption prediction. Overall, these competitions provide a dataset for residential energy research and serve as a catalyst for exploring accurate forecasting, enhancing interpretability, and driving progress towards the discussion of various aspects such as energy disaggregation, demand response programs or behavioural interventions.
Forecast Evaluation for Data Scientists: Common Pitfalls and Best Practices
Apr 04, 2022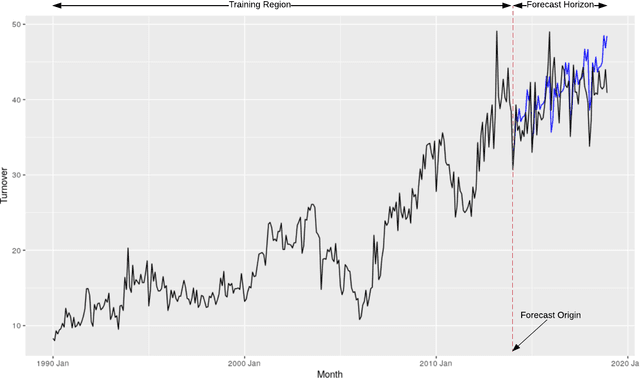
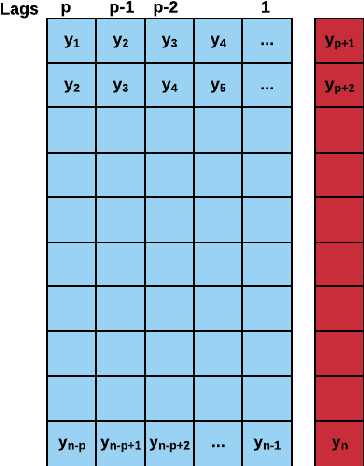

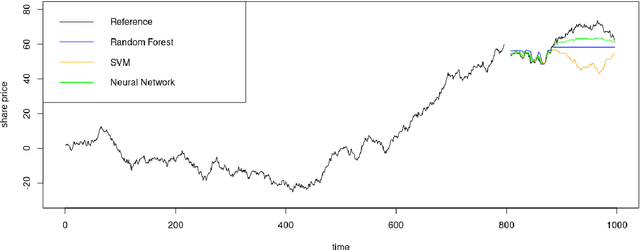
Machine Learning (ML) and Deep Learning (DL) methods are increasingly replacing traditional methods in many domains involved with important decision making activities. DL techniques tailor-made for specific tasks such as image recognition, signal processing, or speech analysis are being introduced at a fast pace with many improvements. However, for the domain of forecasting, the current state in the ML community is perhaps where other domains such as Natural Language Processing and Computer Vision were at several years ago. The field of forecasting has mainly been fostered by statisticians/econometricians; consequently the related concepts are not the mainstream knowledge among general ML practitioners. The different non-stationarities associated with time series challenge the data-driven ML models. Nevertheless, recent trends in the domain have shown that with the availability of massive amounts of time series, ML techniques are quite competent in forecasting, when related pitfalls are properly handled. Therefore, in this work we provide a tutorial-like compilation of the details of one of the most important steps in the overall forecasting process, namely the evaluation. This way, we intend to impart the information of forecast evaluation to fit the context of ML, as means of bridging the knowledge gap between traditional methods of forecasting and state-of-the-art ML techniques. We elaborate on the different problematic characteristics of time series such as non-normalities and non-stationarities and how they are associated with common pitfalls in forecast evaluation. Best practices in forecast evaluation are outlined with respect to the different steps such as data partitioning, error calculation, statistical testing, and others. Further guidelines are also provided along selecting valid and suitable error measures depending on the specific characteristics of the dataset at hand.
NeuralProphet: Explainable Forecasting at Scale
Nov 29, 2021
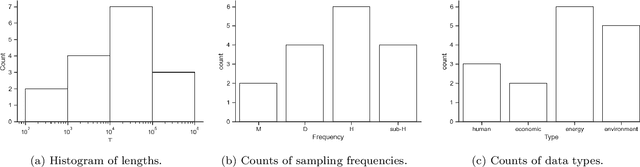
We introduce NeuralProphet, a successor to Facebook Prophet, which set an industry standard for explainable, scalable, and user-friendly forecasting frameworks. With the proliferation of time series data, explainable forecasting remains a challenging task for business and operational decision making. Hybrid solutions are needed to bridge the gap between interpretable classical methods and scalable deep learning models. We view Prophet as a precursor to such a solution. However, Prophet lacks local context, which is essential for forecasting the near-term future and is challenging to extend due to its Stan backend. NeuralProphet is a hybrid forecasting framework based on PyTorch and trained with standard deep learning methods, making it easy for developers to extend the framework. Local context is introduced with auto-regression and covariate modules, which can be configured as classical linear regression or as Neural Networks. Otherwise, NeuralProphet retains the design philosophy of Prophet and provides the same basic model components. Our results demonstrate that NeuralProphet produces interpretable forecast components of equivalent or superior quality to Prophet on a set of generated time series. NeuralProphet outperforms Prophet on a diverse collection of real-world datasets. For short to medium-term forecasts, NeuralProphet improves forecast accuracy by 55 to 92 percent.
A Look at the Evaluation Setup of the M5 Forecasting Competition
Aug 08, 2021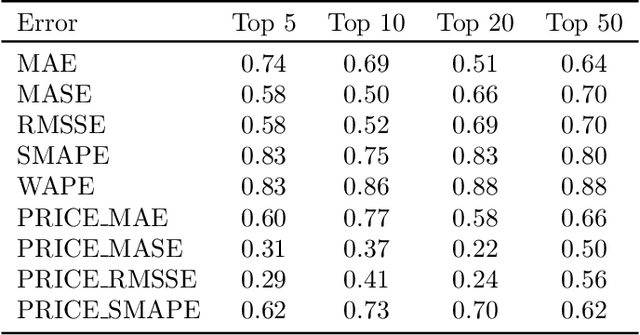
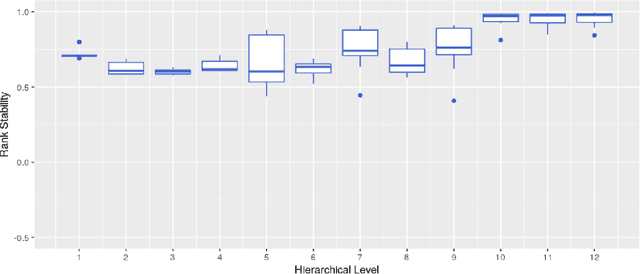
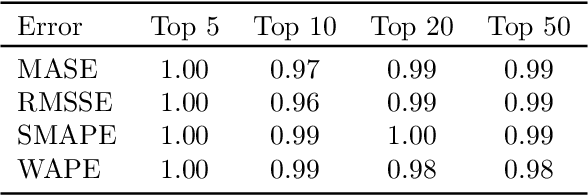
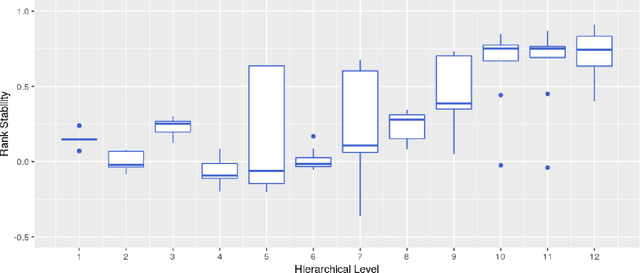
Forecast evaluation plays a key role in how empirical evidence shapes the development of the discipline. Domain experts are interested in error measures relevant for their decision making needs. Such measures may produce unreliable results. Although reliability properties of several metrics have already been discussed, it has hardly been quantified in an objective way. We propose a measure named Rank Stability, which evaluates how much the rankings of an experiment differ in between similar datasets, when the models and errors are constant. We use this to study the evaluation setup of the M5. We find that the evaluation setup of the M5 is less reliable than other measures. The main drivers of instability are hierarchical aggregation and scaling. Price-weighting reduces the stability of all tested error measures. Scale normalization of the M5 error measure results in less stability than other scale-free errors. Hierarchical levels taken separately are less stable with more aggregation, and their combination is even less stable than individual levels. We also show positive tradeoffs of retaining aggregation importance without affecting stability. Aggregation and stability can be linked to the influence of much debated magic numbers. Many of our findings can be applied to general hierarchical forecast benchmarking.
Global Models for Time Series Forecasting: A Simulation Study
Dec 23, 2020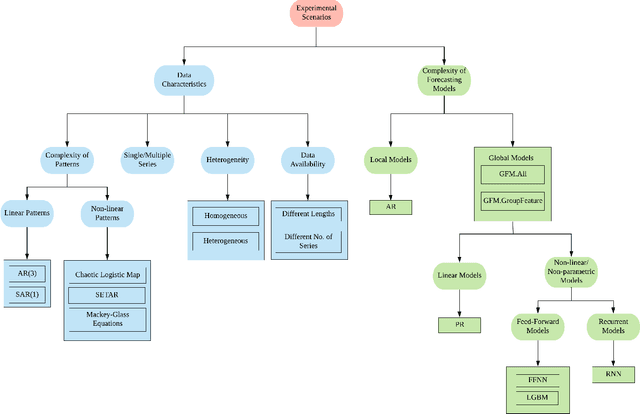
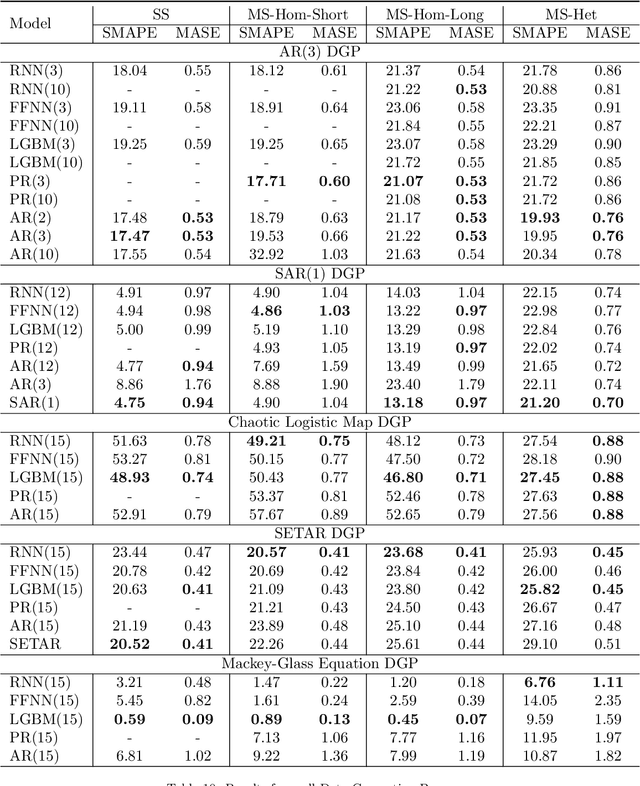
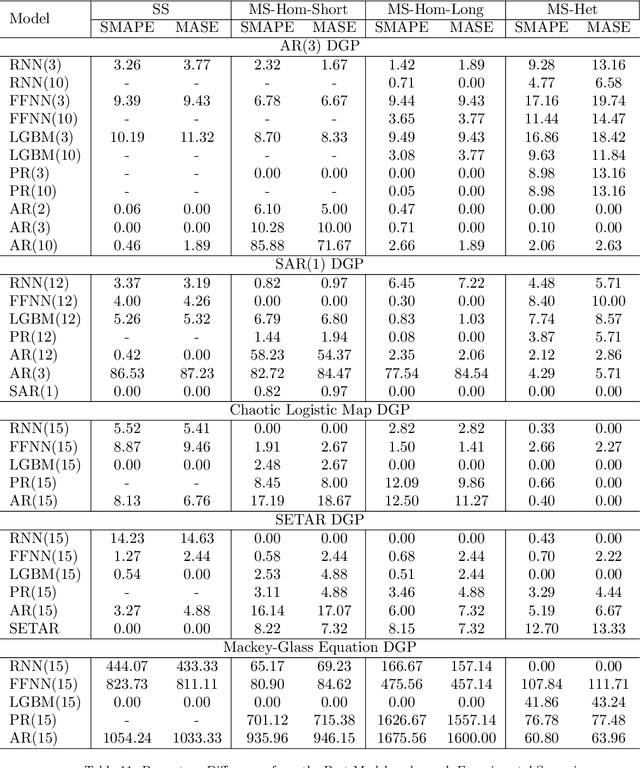
In the current context of Big Data, the nature of many forecasting problems has changed from predicting isolated time series to predicting many time series from similar sources. This has opened up the opportunity to develop competitive global forecasting models that simultaneously learn from many time series. But, it still remains unclear when global forecasting models can outperform the univariate benchmarks, especially along the dimensions of the homogeneity/heterogeneity of series, the complexity of patterns in the series, the complexity of forecasting models, and the lengths/number of series. Our study attempts to address this problem through investigating the effect from these factors, by simulating a number of datasets that have controllable time series characteristics. Specifically, we simulate time series from simple data generating processes (DGP), such as Auto Regressive (AR) and Seasonal AR, to complex DGPs, such as Chaotic Logistic Map, Self-Exciting Threshold Auto-Regressive, and Mackey-Glass Equations. The data heterogeneity is introduced by mixing time series generated from several DGPs into a single dataset. The lengths and the number of series in the dataset are varied in different scenarios. We perform experiments on these datasets using global forecasting models including Recurrent Neural Networks (RNN), Feed-Forward Neural Networks, Pooled Regression (PR) models and Light Gradient Boosting Models (LGBM), and compare their performance against standard statistical univariate forecasting techniques. Our experiments demonstrate that when trained as global forecasting models, techniques such as RNNs and LGBMs, which have complex non-linear modelling capabilities, are competitive methods in general under challenging forecasting scenarios such as series having short lengths, datasets with heterogeneous series and having minimal prior knowledge of the patterns of the series.
Improving the Accuracy of Global Forecasting Models using Time Series Data Augmentation
Aug 06, 2020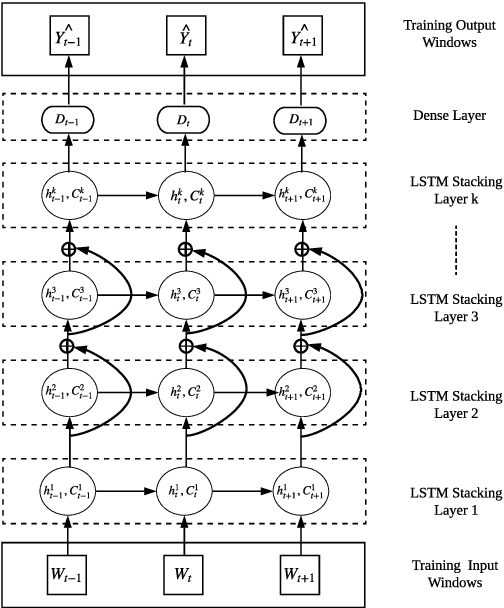

Forecasting models that are trained across sets of many time series, known as Global Forecasting Models (GFM), have shown recently promising results in forecasting competitions and real-world applications, outperforming many state-of-the-art univariate forecasting techniques. In most cases, GFMs are implemented using deep neural networks, and in particular Recurrent Neural Networks (RNN), which require a sufficient amount of time series to estimate their numerous model parameters. However, many time series databases have only a limited number of time series. In this study, we propose a novel, data augmentation based forecasting framework that is capable of improving the baseline accuracy of the GFM models in less data-abundant settings. We use three time series augmentation techniques: GRATIS, moving block bootstrap (MBB), and dynamic time warping barycentric averaging (DBA) to synthetically generate a collection of time series. The knowledge acquired from these augmented time series is then transferred to the original dataset using two different approaches: the pooled approach and the transfer learning approach. When building GFMs, in the pooled approach, we train a model on the augmented time series alongside the original time series dataset, whereas in the transfer learning approach, we adapt a pre-trained model to the new dataset. In our evaluation on competition and real-world time series datasets, our proposed variants can significantly improve the baseline accuracy of GFM models and outperform state-of-the-art univariate forecasting methods.
Recurrent Neural Networks for Time Series Forecasting: Current Status and Future Directions
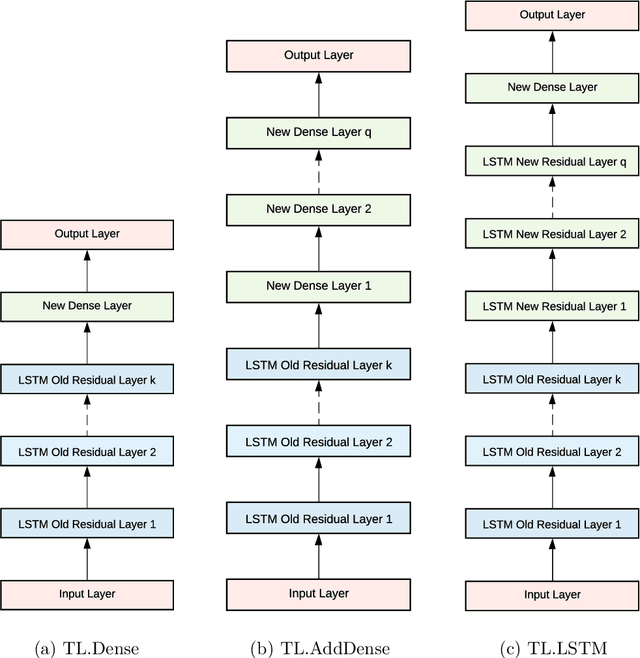
Sep 24, 2019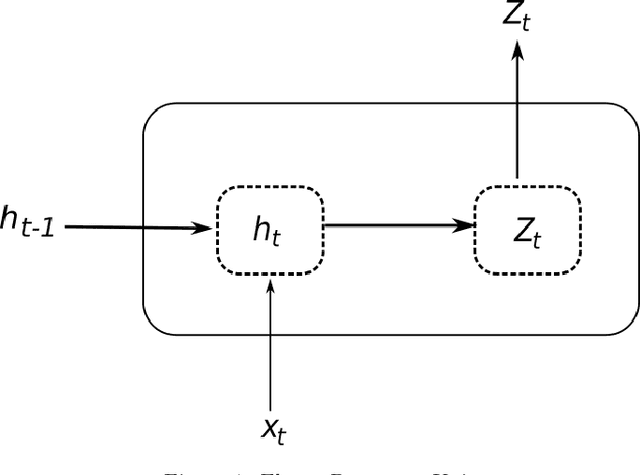



Recurrent Neural Networks (RNN) have become competitive forecasting methods, as most notably shown in the winning method of the recent M4 competition. However, established statistical models such as ETS and ARIMA gain their popularity not only from their high accuracy, but they are also suitable for non-expert users as they are robust, efficient, and automatic. In these areas, RNNs have still a long way to go. We present an extensive empirical study and an open-source software framework of existing RNN architectures for forecasting, that allow us to develop guidelines and best practices for their use. For example, we conclude that RNNs are capable of modelling seasonality directly if the series in the dataset possess homogeneous seasonal patterns, otherwise we recommend a deseasonalization step. Comparisons against ETS and ARIMA demonstrate that the implemented (semi-)automatic RNN models are no silver bullets, but they are competitive alternatives in many situations.
LSTM-MSNet: Leveraging Forecasts on Sets of Related Time Series with Multiple Seasonal Patterns
Sep 10, 2019
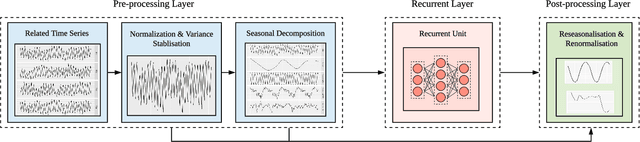
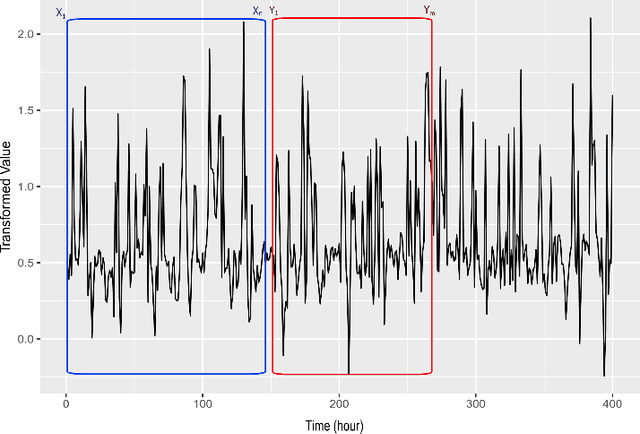
Generating forecasts for time series with multiple seasonal cycles is an important use-case for many industries nowadays. Accounting for the multi-seasonal patterns becomes necessary to generate more accurate and meaningful forecasts in these contexts. In this paper, we propose Long Short-Term Memory Multi-Seasonal Net (LSTM-MSNet), a decompositionbased, unified prediction framework to forecast time series with multiple seasonal patterns. The current state of the art in this space are typically univariate methods, in which the model parameters of each time series are estimated independently. Consequently, these models are unable to include key patterns and structures that may be shared by a collection of time series. In contrast, LSTM-MSNet is a globally trained Long Short-Term Memory network (LSTM), where a single prediction model is built across all the available time series to exploit the crossseries knowledge in a group of related time series. Furthermore, our methodology combines a series of state-of-the-art multiseasonal decomposition techniques to supplement the LSTM learning procedure. In our experiments, we are able to show that on datasets from disparate data sources, like e.g. the popular M4 forecasting competition, a decomposition step is beneficial, whereas in the common real-world situation of homogeneous series from a single application, exogenous seasonal variables or no seasonal preprocessing at all are better choices. All options are readily included in the framework and allow us to achieve competitive results for both cases, outperforming many state-ofthe-art multi-seasonal forecasting methods
Sales Demand Forecast in E-commerce using a Long Short-Term Memory Neural Network Methodology
Jan 13, 2019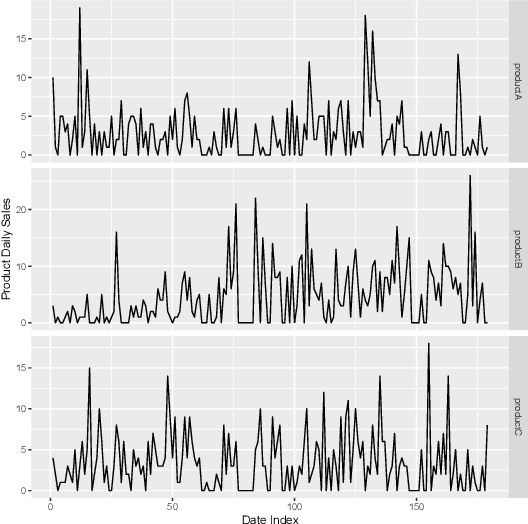

Generating accurate and reliable sales forecasts is crucial in the E-commerce business. The current state-of-the-art techniques are typically univariate methods, which produce forecasts considering only the historical sales data of a single product. However, in a situation where large quantities of related time series are available, conditioning the forecast of an individual time series on past behaviour of similar, related time series can be beneficial. Given that the product assortment hierarchy in an E-commerce platform contains large numbers of related products, in which the sales demand patterns can be correlated, our attempt is to incorporate this cross-series information in a unified model. We achieve this by globally training a Long Short-Term Memory network (LSTM) that exploits the nonlinear demand relationships available in an E-commerce product assortment hierarchy. Aside from the forecasting engine, we propose a systematic pre-processing framework to overcome the challenges in an E-commerce setting. We also introduce several product grouping strategies to supplement the LSTM learning schemes, in situations where sales patterns in a product portfolio are disparate. We empirically evaluate the proposed forecasting framework on a real-world online marketplace dataset from Walmart. com. Our method achieves competitive results on category level and super-departmental level datasets, outperforming state-of-the-art techniques.