 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecast Evaluation for Data Scientists: Common Pitfalls and Best Practices
Paper and Code
Apr 04, 2022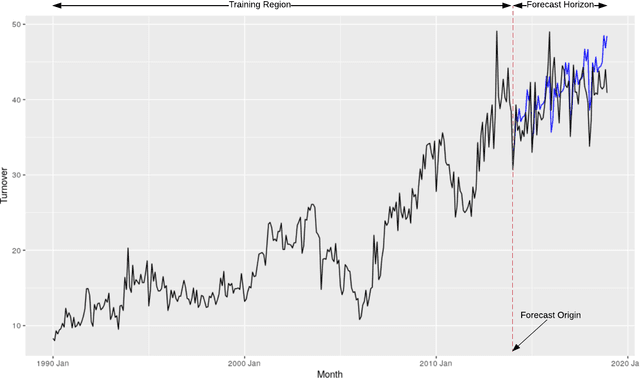
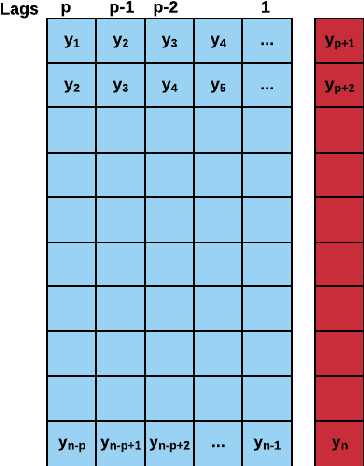

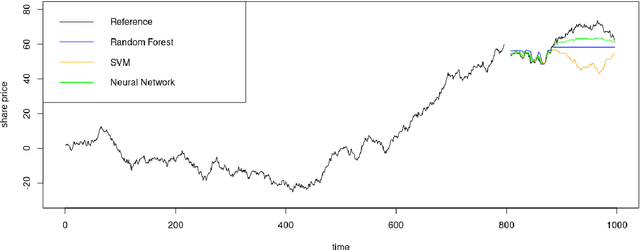
Machine Learning (ML) and Deep Learning (DL) methods are increasingly replacing traditional methods in many domains involved with important decision making activities. DL techniques tailor-made for specific tasks such as image recognition, signal processing, or speech analysis are being introduced at a fast pace with many improvements. However, for the domain of forecasting, the current state in the ML community is perhaps where other domains such as Natural Language Processing and Computer Vision were at several years ago. The field of forecasting has mainly been fostered by statisticians/econometricians; consequently the related concepts are not the mainstream knowledge among general ML practitioners. The different non-stationarities associated with time series challenge the data-driven ML models. Nevertheless, recent trends in the domain have shown that with the availability of massive amounts of time series, ML techniques are quite competent in forecasting, when related pitfalls are properly handled. Therefore, in this work we provide a tutorial-like compilation of the details of one of the most important steps in the overall forecasting process, namely the evaluation. This way, we intend to impart the information of forecast evaluation to fit the context of ML, as means of bridging the knowledge gap between traditional methods of forecasting and state-of-the-art ML techniques. We elaborate on the different problematic characteristics of time series such as non-normalities and non-stationarities and how they are associated with common pitfalls in forecast evaluation. Best practices in forecast evaluation are outlined with respect to the different steps such as data partitioning, error calculation, statistical testing, and others. Further guidelines are also provided along selecting valid and suitable error measures depending on the specific characteristics of the dataset at hand.