 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralProphet: Explainable Forecasting at Scale
Nov 29, 2021
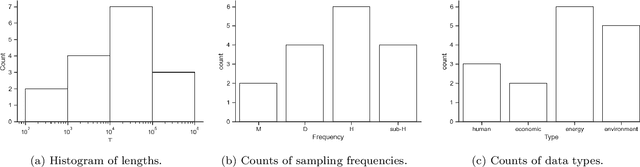
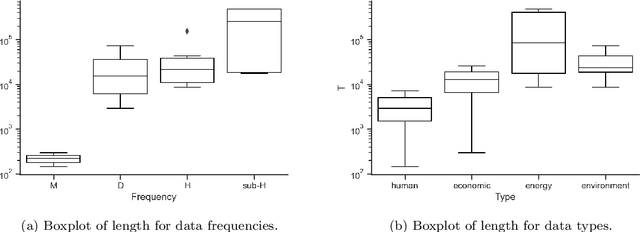
We introduce NeuralProphet, a successor to Facebook Prophet, which set an industry standard for explainable, scalable, and user-friendly forecasting frameworks. With the proliferation of time series data, explainable forecasting remains a challenging task for business and operational decision making. Hybrid solutions are needed to bridge the gap between interpretable classical methods and scalable deep learning models. We view Prophet as a precursor to such a solution. However, Prophet lacks local context, which is essential for forecasting the near-term future and is challenging to extend due to its Stan backend. NeuralProphet is a hybrid forecasting framework based on PyTorch and trained with standard deep learning methods, making it easy for developers to extend the framework. Local context is introduced with auto-regression and covariate modules, which can be configured as classical linear regression or as Neural Networks. Otherwise, NeuralProphet retains the design philosophy of Prophet and provides the same basic model components. Our results demonstrate that NeuralProphet produces interpretable forecast components of equivalent or superior quality to Prophet on a set of generated time series. NeuralProphet outperforms Prophet on a diverse collection of real-world datasets. For short to medium-term forecasts, NeuralProphet improves forecast accuracy by 55 to 92 percent.
Scalable Data Classification for Security and Privacy
Jul 06, 2020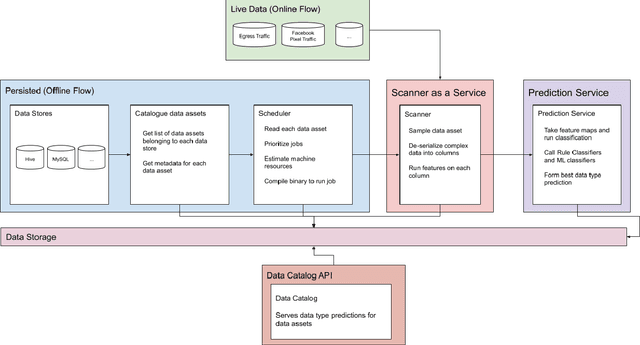


Content based data classification is an open challenge. Traditional Data Loss Prevention (DLP)-like systems solve this problem by fingerprinting the data in question and monitoring endpoints for the fingerprinted data. With a large number of constantly changing data assets in Facebook, this approach is both not scalable and ineffective in discovering what data is where. This paper is about an end-to-end system built to detect sensitive semantic types within Facebook at scale and enforce data retention and access controls automatically. The approach described here is our first end-to-end privacy system that attempts to solve this problem by incorporating data signals, machine learning, and traditional fingerprinting techniques to map out and classify all data within Facebook. The described system is in production achieving a 0.9+ average F2 scores across various privacy classes while handling a large number of data assets across dozens of data stores.
AR-Net: A simple Auto-Regressive Neural Network for time-series
Nov 27, 2019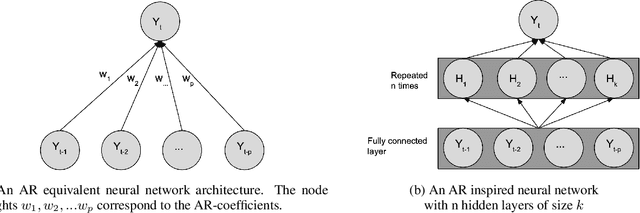
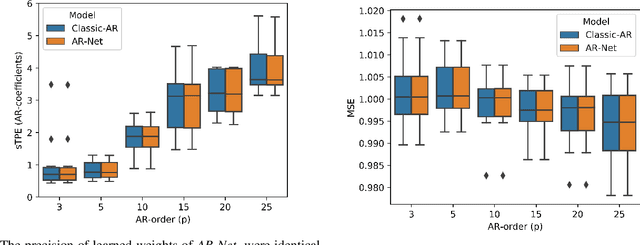
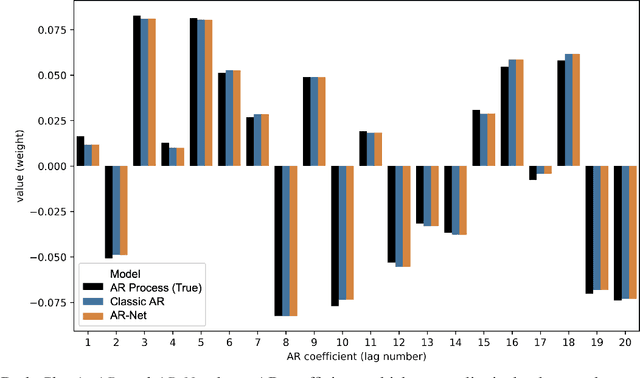

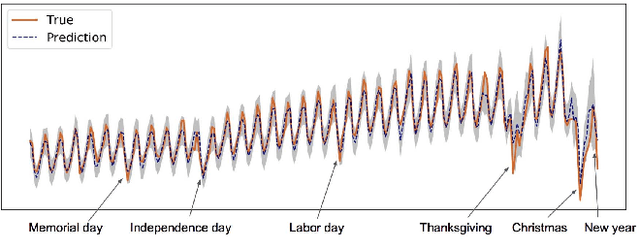
In this paper we present a new framework for time-series modeling that combines the best of traditional statistical models and neural networks. We focus on time-series with long-range dependencies, needed for monitoring fine granularity data (e.g. minutes, seconds, milliseconds), prevalent in operational use-cases. Traditional models, such as auto-regression fitted with least squares (Classic-AR) can model time-series with a concise and interpretable model. When dealing with long-range dependencies, Classic-AR models can become intractably slow to fit for large data. Recently, sequence-to-sequence models, such as Recurrent Neural Networks, which were originally intended for natural language processing, have become popular for time-series. However, they can be overly complex for typical time-series data and lack interpretability. A scalable and interpretable model is needed to bridge the statistical and deep learning-based approaches. As a first step towards this goal, we propose modelling AR-process dynamics using a feed-forward neural network approach, termed AR-Net. We show that AR-Net is as interpretable as Classic-AR but also scales to long-range dependencies. Our results lead to three major conclusions: First, AR-Net learns identical AR-coefficients as Classic-AR, thus being equally interpretable. Second, the computational complexity with respect to the order of the AR process, is linear for AR-Net as compared to a quadratic for Classic-AR. This makes it possible to model long-range dependencies within fine granularity data. Third, by introducing regularization, AR-Net automatically selects and learns sparse AR-coefficients. This eliminates the need to know the exact order of the AR-process and allows to learn sparse weights for a model with long-range dependencies.
Deep and Confident Prediction for Time Series at Uber
Sep 06, 2017


Reliable uncertainty estimation for time series prediction is critical in many fields, including physics, biology, and manufacturing. At Uber, probabilistic time series forecasting is used for robust prediction of number of trips during special events, driver incentive allocation, as well as real-time anomaly detection across millions of metrics. Classical time series models are often used in conjunction with a probabilistic formulation for uncertainty estimation. However, such models are hard to tune, scale, and add exogenous variables to. Motivated by the recent resurgence of Long Short Term Memory networks, we propose a novel end-to-end Bayesian deep model that provides time series prediction along with uncertainty estimation. We provide detailed experiments of the proposed solution on completed trips data, and successfully apply it to large-scale time series anomaly detection at Uber.
* To appear in DSBDA-2017 @ ICDM'17
Online Article Ranking as a Constrained, Dynamic, Multi-Objective Optimization Problem
May 16, 2017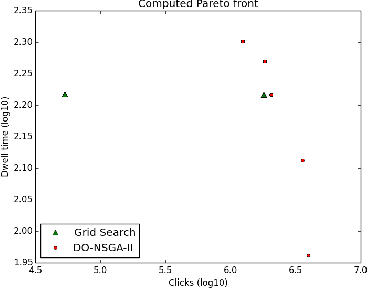

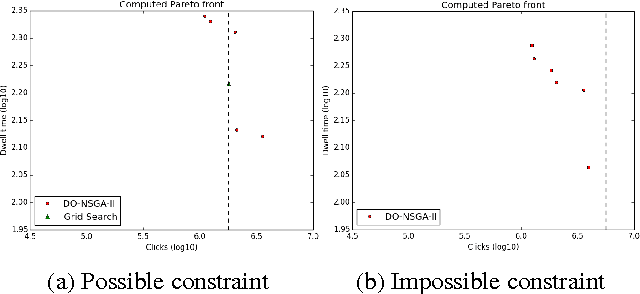
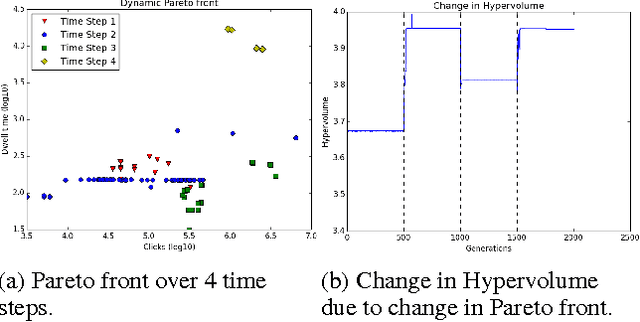
The content ranking problem in a social news website, is typically a function that maximizes a scalar metric of interest like dwell-time. However, like in most real-world applications we are interested in more than one metric---for instance simultaneously maximizing click-through rate, monetization metrics, dwell-time---and also satisfy the traffic requirements promised to different publishers. All this needs to be done on online data and under the settings where the objective function and the constraints can dynamically change; this could happen if for instance new publishers are added, some contracts are adjusted, or if some contracts are over. In this paper, we formulate this problem as a constrained, dynamic, multi-objective optimization problem. We propose a novel framework that extends a successful genetic optimization algorithm, NSGA-II, to solve this online, data-driven problem. We design the modules of NSGA-II to suit our problem. We evaluate optimization performance using Hypervolume and introduce a confidence interval metric for assessing the practicality of a solution. We demonstrate the application of this framework on a real-world Article Ranking problem. We observe that we make considerable improvements in both time and performance over a brute-force baseline technique that is currently in production.
Rank-to-engage: New Listwise Approaches to Maximize Engagement
Feb 24, 2017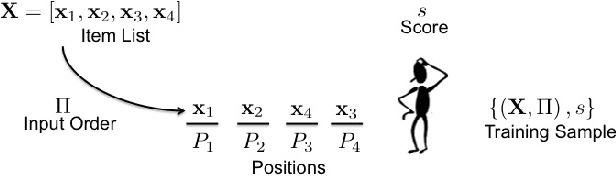



For many internet businesses, presenting a given list of items in an order that maximizes a certain metric of interest (e.g., click-through-rate, average engagement time etc.) is crucial. We approach the aforementioned task from a learning-to-rank perspective which reveals a new problem setup. In traditional learning-to-rank literature, it is implicitly assumed that during the training data generation one has access to the \emph{best or desired} order for the given list of items. In this work, we consider a problem setup where we do not observe the desired ranking. We present two novel solutions: the first solution is an extension of already existing listwise learning-to-rank technique--Listwise maximum likelihood estimation (ListMLE)--while the second one is a generic machine learning based framework that tackles the problem in its entire generality. We discuss several challenges associated with this generic framework, and propose a simple \emph{item-payoff} and \emph{positional-gain} model that addresses these challenges. We provide training algorithms, inference procedures, and demonstrate the effectiveness of the two approaches over traditional ListMLE on synthetic as well as on real-life setting of ranking news articles for increased dwell time.