 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Data Classification for Security and Privacy
Paper and Code
Jul 06, 2020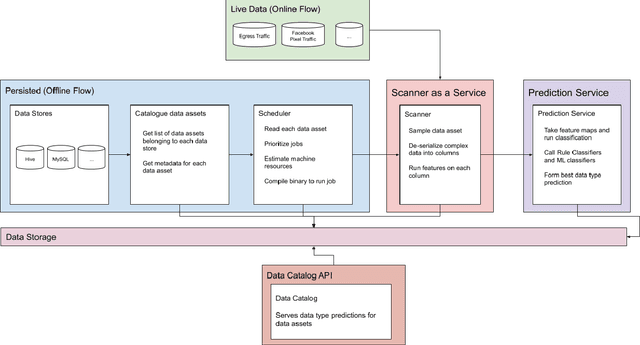


Content based data classification is an open challenge. Traditional Data Loss Prevention (DLP)-like systems solve this problem by fingerprinting the data in question and monitoring endpoints for the fingerprinted data. With a large number of constantly changing data assets in Facebook, this approach is both not scalable and ineffective in discovering what data is where. This paper is about an end-to-end system built to detect sensitive semantic types within Facebook at scale and enforce data retention and access controls automatically. The approach described here is our first end-to-end privacy system that attempts to solve this problem by incorporating data signals, machine learning, and traditional fingerprinting techniques to map out and classify all data within Facebook. The described system is in production achieving a 0.9+ average F2 scores across various privacy classes while handling a large number of data assets across dozens of data stores.