 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Calibration Network for Occluded Pedestrian Detection
Dec 12, 2022Pedestrian detection in the wild remains a challenging problem especially for scenes containing serious occlusion. In this paper, we propose a novel feature learning method in the deep learning framework, referred to as Feature Calibration Network (FC-Net), to adaptively detect pedestrians under various occlusions. FC-Net is based on the observation that the visible parts of pedestrians are selective and decisive for detection, and is implemented as a self-paced feature learning framework with a self-activation (SA) module and a feature calibration (FC) module. In a new self-activated manner, FC-Net learns features which highlight the visible parts and suppress the occluded parts of pedestrians. The SA module estimates pedestrian activation maps by reusing classifier weights, without any additional parameter involved, therefore resulting in an extremely parsimony model to reinforce the semantics of features, while the FC module calibrates the convolutional features for adaptive pedestrian representation in both pixel-wise and region-based ways. Experiments on CityPersons and Caltech datasets demonstrate that FC-Net improves detection performance on occluded pedestrians up to 10% while maintaining excellent performance on non-occluded instances.
CircleNet: Reciprocating Feature Adaptation for Robust Pedestrian Detection
Dec 12, 2022Pedestrian detection in the wild remains a challenging problem especially when the scene contains significant occlusion and/or low resolution of the pedestrians to be detected. Existing methods are unable to adapt to these difficult cases while maintaining acceptable performance. In this paper we propose a novel feature learning model, referred to as CircleNet, to achieve feature adaptation by mimicking the process humans looking at low resolution and occluded objects: focusing on it again, at a finer scale, if the object can not be identified clearly for the first time. CircleNet is implemented as a set of feature pyramids and uses weight sharing path augmentation for better feature fusion. It targets at reciprocating feature adaptation and iterative object detection using multiple top-down and bottom-up pathways. To take full advantage of the feature adaptation capability in CircleNet, we design an instance decomposition training strategy to focus on detecting pedestrian instances of various resolutions and different occlusion levels in each cycle. Specifically, CircleNet implements feature ensemble with the idea of hard negative boosting in an end-to-end manner. Experiments on two pedestrian detection datasets, Caltech and CityPersons, show that CircleNet improves the performance of occluded and low-resolution pedestrians with significant margins while maintaining good performance on normal instances.
HDNet: A Hierarchically Decoupled Network for Crowd Counting
Dec 12, 2022Recently, density map regression-based methods have dominated in crowd counting owing to their excellent fitting ability on density distribution. However, further improvement tends to saturate mainly because of the confusing background noise and the large density variation. In this paper, we propose a Hierarchically Decoupled Network (HDNet) to solve the above two problems within a unified framework. Specifically, a background classification sub-task is decomposed from the density map prediction task, which is then assigned to a Density Decoupling Module (DDM) to exploit its highly discriminative ability. For the remaining foreground prediction sub-task, it is further hierarchically decomposed to several density-specific sub-tasks by the DDM, which are then solved by the regression-based experts in a Foreground Density Estimation Module (FDEM). Although the proposed strategy effectively reduces the hypothesis space so as to relieve the optimization for those task-specific experts, the high correlation of these sub-tasks are ignored. Therefore, we introduce three types of interaction strategies to unify the whole framework, which are Feature Interaction, Gradient Interaction, and Scale Interaction. Integrated with the above spirits, HDNet achieves state-of-the-art performance on several popular counting benchmarks.
Global Meets Local: Effective Multi-Label Image Classification via Category-Aware Weak Supervision
Nov 23, 2022Multi-label image classification, which can be categorized into label-dependency and region-based methods, is a challenging problem due to the complex underlying object layouts. Although region-based methods are less likely to encounter issues with model generalizability than label-dependency methods, they often generate hundreds of meaningless or noisy proposals with non-discriminative information, and the contextual dependency among the localized regions is often ignored or over-simplified. This paper builds a unified framework to perform effective noisy-proposal suppression and to interact between global and local features for robust feature learning. Specifically, we propose category-aware weak supervision to concentrate on non-existent categories so as to provide deterministic information for local feature learning, restricting the local branch to focus on more high-quality regions of interest. Moreover, we develop a cross-granularity attention module to explore the complementary information between global and local features, which can build the high-order feature correlation containing not only global-to-local, but also local-to-local relations. Both advantages guarantee a boost in the performance of the whole network. Extensive experiments on two large-scale datasets (MS-COCO and VOC 2007) demonstrate that our framework achieves superior performance over state-of-the-art methods.
* 12 pages, 10 figures, published in ACMMM 2022
Multiple Anchor Learning for Visual Object Detection
Dec 04, 2019

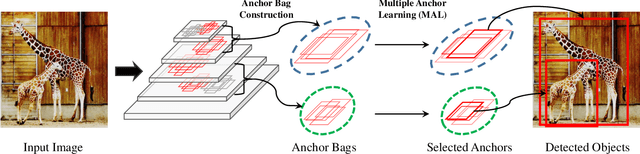
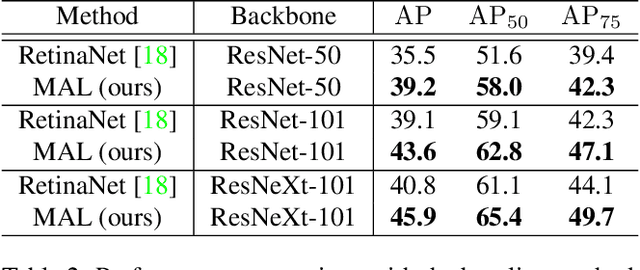
Classification and localization are two pillars of visual object detectors. However, in CNN-based detectors, these two modules are usually optimized under a fixed set of candidate (or anchor) bounding boxes. This configuration significantly limits the possibility to jointly optimize classification and localization. In this paper, we propose a Multiple Instance Learning (MIL) approach that selects anchors and jointly optimizes the two modules of a CNN-based object detector. Our approach, referred to as Multiple Anchor Learning (MAL), constructs anchor bags and selects the most representative anchors from each bag. Such an iterative selection process is potentially NP-hard to optimize. To address this issue, we solve MAL by repetitively depressing the confidence of selected anchors by perturbing their corresponding features. In an adversarial selection-depression manner, MAL not only pursues optimal solutions but also fully leverages multiple anchors/features to learn a detection model. Experiments show that MAL improves the baseline RetinaNet with significant margins on the commonly used MS-COCO object detection benchmark and achieves new state-of-the-art detection performance compared with recent methods.
Self-learning Scene-specific Pedestrian Detectors using a Progressive Latent Model
Nov 22, 2016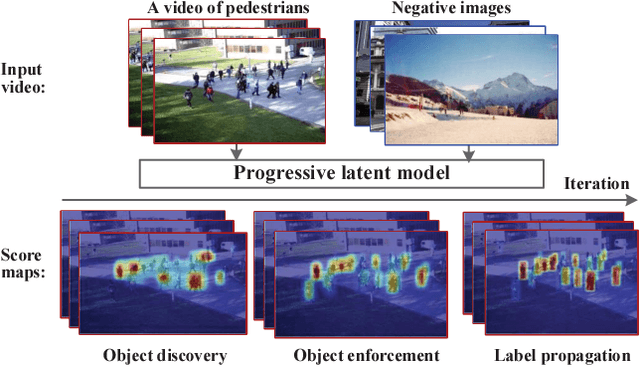
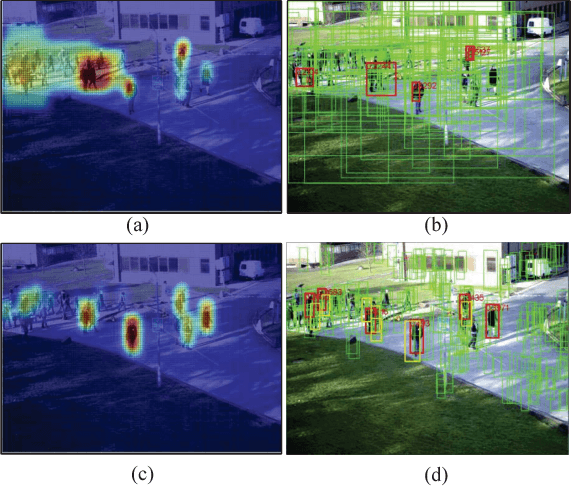
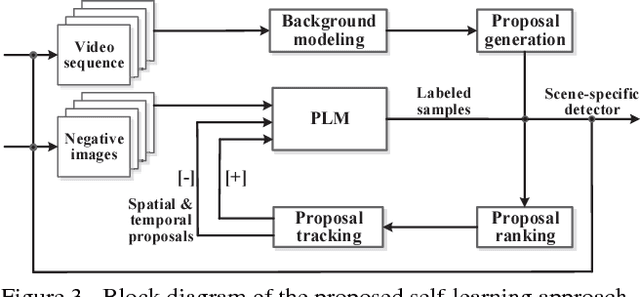
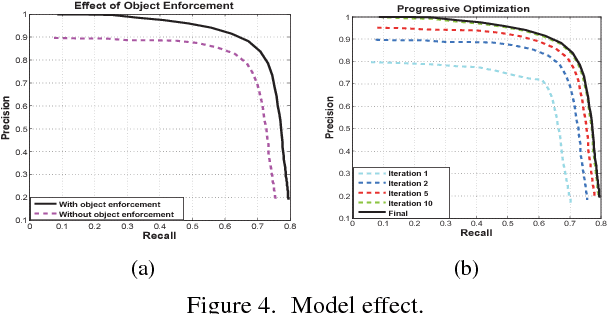
In this paper, a self-learning approach is proposed towards solving scene-specific pedestrian detection problem without any human' annotation involved. The self-learning approach is deployed as progressive steps of object discovery, object enforcement, and label propagation. In the learning procedure, object locations in each frame are treated as latent variables that are solved with a progressive latent model (PLM). Compared with conventional latent models, the proposed PLM incorporates a spatial regularization term to reduce ambiguities in object proposals and to enforce object localization, and also a graph-based label propagation to discover harder instances in adjacent frames. With the difference of convex (DC) objective functions, PLM can be efficiently optimized with a concave-convex programming and thus guaranteeing the stability of self-learning. Extensive experiments demonstrate that even without annotation the proposed self-learning approach outperforms weakly supervised learning approaches, while achieving comparable performance with transfer learning and fully supervised approaches.