 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamSoNG: A Soft Streaming Classification Approach
Oct 01, 2020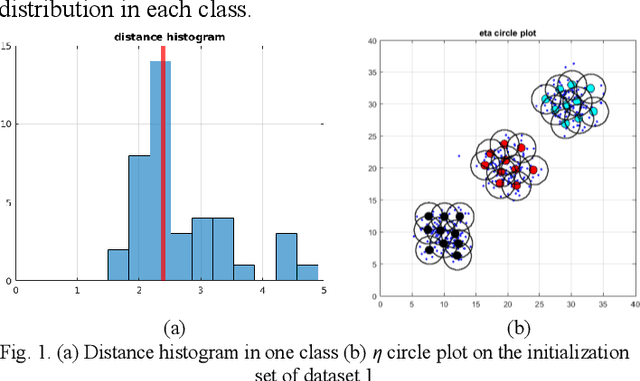
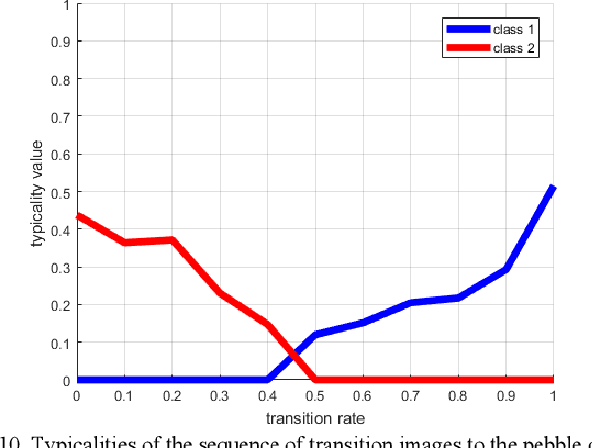
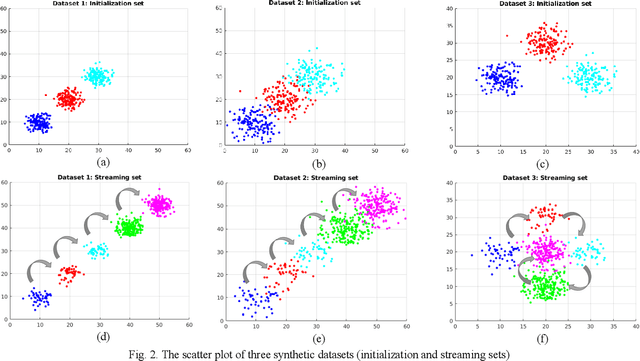
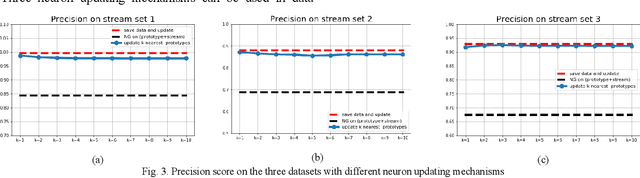
Examining most streaming clustering algorithms leads to the understanding that they are actually incremental classification models. They model existing and newly discovered structures via summary information that we call footprints. Incoming data is normally assigned crisp labels (into one of the structures) and that structure's footprints are incrementally updated. There is no reason that these assignments need to be crisp. In this paper, we propose a new streaming classification algorithm that uses Neural Gas prototypes as footprints and produces a possibilistic label vector (typicalities) for each incoming vector. These typicalities are generated by a modified possibilistic k-nearest neighbor algorithm. The approach is tested on synthetic and real image datasets with excellent results.
ConiVAT: Cluster Tendency Assessment and Clustering with Partial Background Knowledge
Sep 28, 2020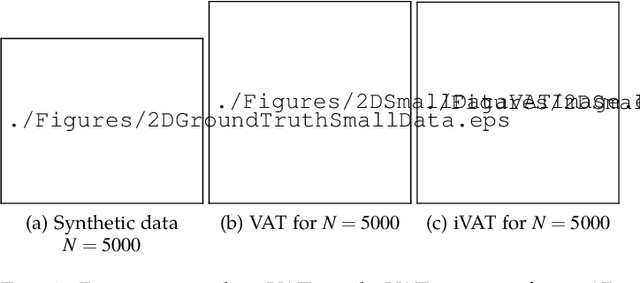
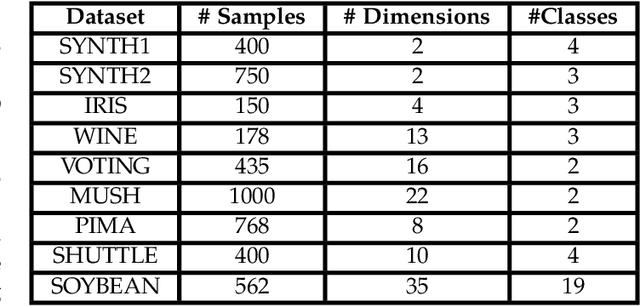

The VAT method is a visual technique for determining the potential cluster structure and the possible number of clusters in numerical data. Its improved version, iVAT, uses a path-based distance transform to improve the effectiveness of VAT for "tough" cases. Both VAT and iVAT have also been used in conjunction with a single-linkage(SL) hierarchical clustering algorithm. However, they are sensitive to noise and bridge points between clusters in the dataset, and consequently, the corresponding VAT/iVAT images are often in-conclusive for such cases. In this paper, we propose a constraint-based version of iVAT, which we call ConiVAT, that makes use of background knowledge in the form of constraints, to improve VAT/iVAT for challenging and complex datasets. ConiVAT uses the input constraints to learn the underlying similarity metric and builds a minimum transitive dissimilarity matrix, before applying VAT to it. We demonstrate ConiVAT approach to visual assessment and single linkage clustering on nine datasets to show that, it improves the quality of iVAT images for complex datasets, and it also overcomes the limitation of SL clustering with VAT/iVAT due to "noisy" bridges between clusters. Extensive experiment results on nine datasets suggest that ConiVAT outperforms the other three semi-supervised clustering algorithms in terms of improved clustering accuracy.
A Scalable Framework for Trajectory Prediction
Jun 20, 2018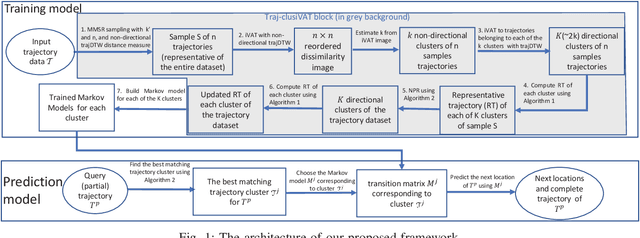

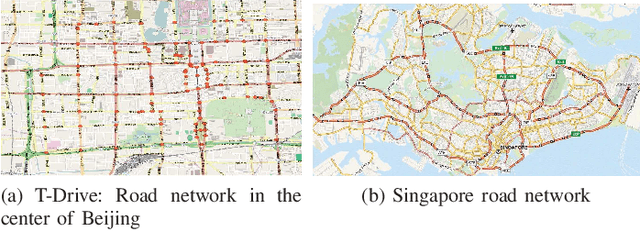
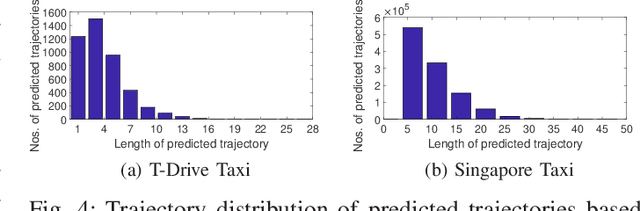
Trajectory prediction (TP) is of great importance for a wide range of location-based applications in intelligent transport systems such as location-based advertising, route planning, traffic management, and early warning systems. In the last few years, the widespread use of GPS navigation systems and wireless communication technology enabled vehicles has resulted in huge volumes of trajectory data. The task of utilizing this data employing spatio-temporal techniques for trajectory prediction in an efficient and accurate manner is an ongoing research problem. Existing TP approaches are limited to short-term predictions. Moreover, they cannot handle a large volume of trajectory data for long-term prediction. To address these limitations, we propose a scalable clustering and Markov chain based hybrid framework, called Traj-clusiVAT-based TP, for both short-term and long-term trajectory prediction, which can handle a large number of overlapping trajectories in a dense road network. In addition, Traj-clusiVAT can also determine the number of clusters, which represent different movement behaviours in input trajectory data. In our experiments, we compare our proposed approach with a mixed Markov model (MMM)-based scheme, and a trajectory clustering, NETSCAN-based TP method for both short- and long-term trajectory predictions. We performed our experiments on two real, vehicle trajectory datasets, including a large-scale trajectory dataset consisting of 3.28 million trajectories obtained from 15,061 taxis in Singapore over a period of one month. Experimental results on two real trajectory datasets show that our proposed approach outperforms the existing approaches in terms of both short- and long-term prediction performances, based on prediction accuracy and distance error (in km).
Online Cluster Validity Indices for Streaming Data
Jan 08, 2018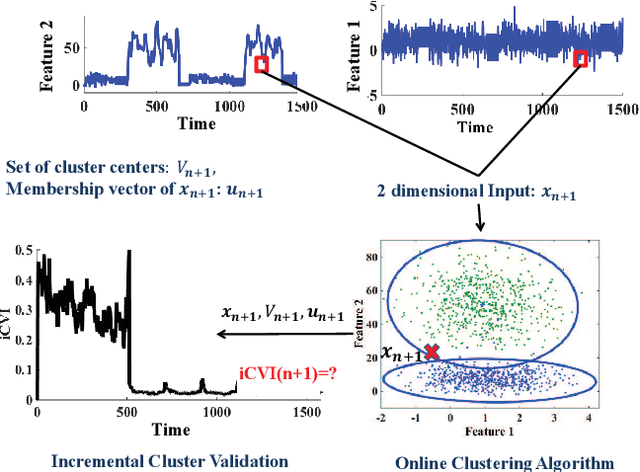
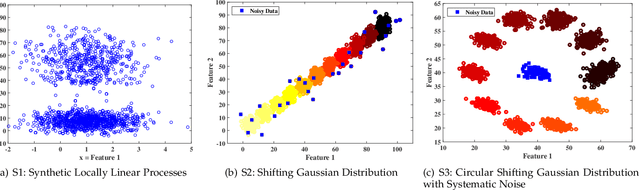
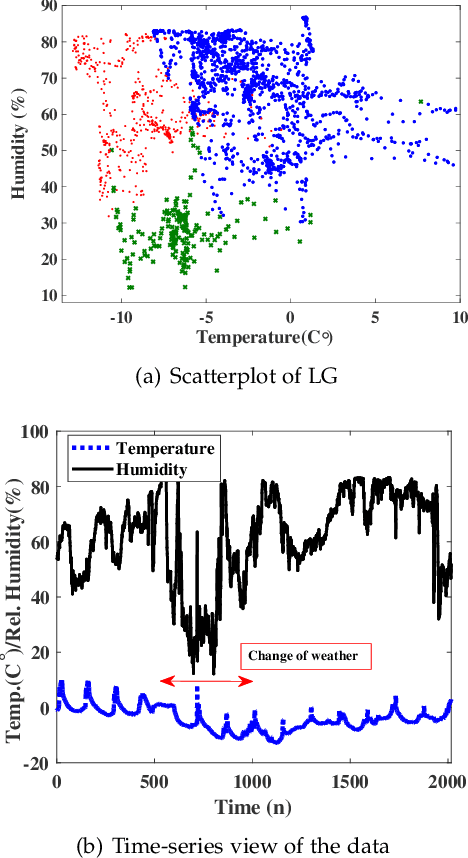
Cluster analysis is used to explore structure in unlabeled data sets in a wide range of applications. An important part of cluster analysis is validating the quality of computationally obtained clusters. A large number of different internal indices have been developed for validation in the offline setting. However, this concept has not been extended to the online setting. A key challenge is to find an efficient incremental formulation of an index that can capture both cohesion and separation of the clusters over potentially infinite data streams. In this paper, we develop two online versions (with and without forgetting factors) of the Xie-Beni and Davies-Bouldin internal validity indices, and analyze their characteristics, using two streaming clustering algorithms (sk-means and online ellipsoidal clustering), and illustrate their use in monitoring evolving clusters in streaming data. We also show that incremental cluster validity indices are capable of sending a distress signal to online monitors when evolving clusters go awry. Our numerical examples indicate that the incremental Xie-Beni index with forgetting factor is superior to the other three indices tested.
An ensemble-based online learning algorithm for streaming data
Apr 26, 2017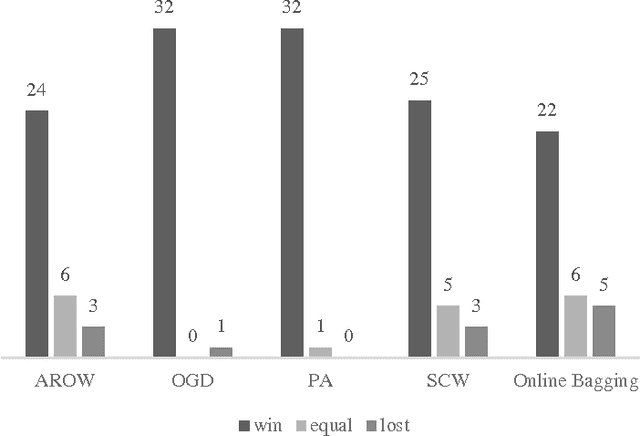
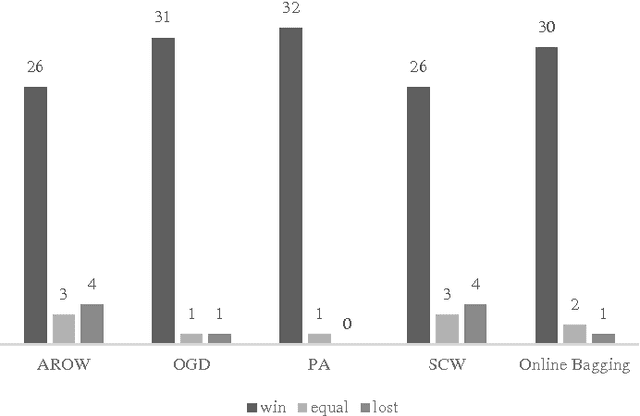

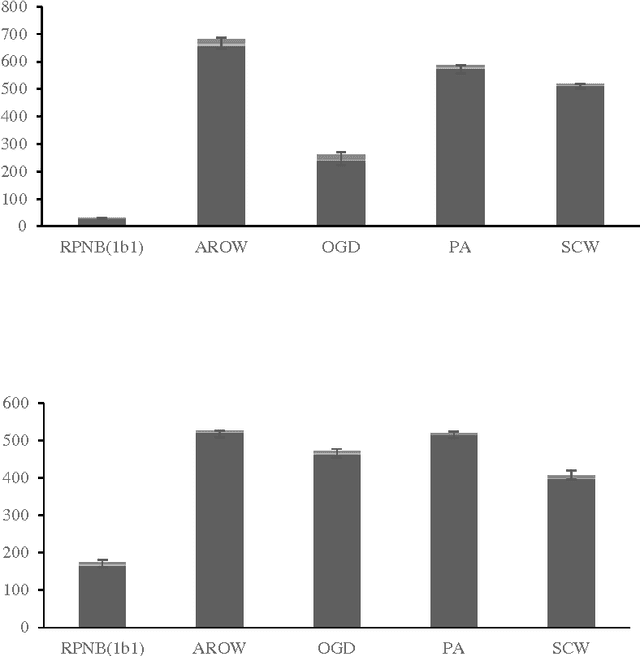
In this study, we introduce an ensemble-based approach for online machine learning. The ensemble of base classifiers in our approach is obtained by learning Naive Bayes classifiers on different training sets which are generated by projecting the original training set to lower dimensional space. We propose a mechanism to learn sequences of data using data chunks paradigm. The experiments conducted on a number of UCI datasets and one synthetic dataset demonstrate that the proposed approach performs significantly better than some well-known online learning algorithms.
Ground Truth Bias in External Cluster Validity Indices
Jun 17, 2016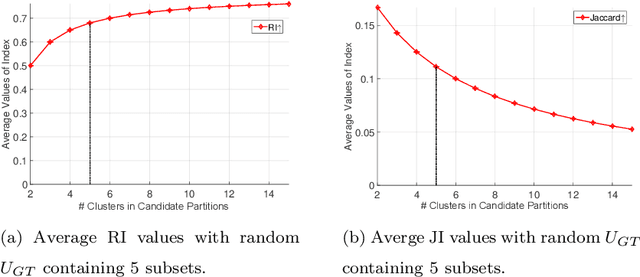
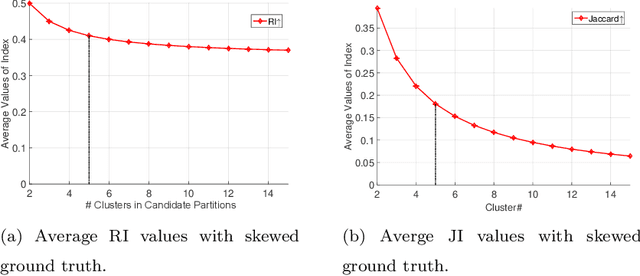

It has been noticed that some external CVIs exhibit a preferential bias towards a larger or smaller number of clusters which is monotonic (directly or inversely) in the number of clusters in candidate partitions. This type of bias is caused by the functional form of the CVI model. For example, the popular Rand index (RI) exhibits a monotone increasing (NCinc) bias, while the Jaccard Index (JI) index suffers from a monotone decreasing (NCdec) bias. This type of bias has been previously recognized in the literature. In this work, we identify a new type of bias arising from the distribution of the ground truth (reference) partition against which candidate partitions are compared. We call this new type of bias ground truth (GT) bias. This type of bias occurs if a change in the reference partition causes a change in the bias status (e.g., NCinc, NCdec) of a CVI. For example, NCinc bias in the RI can be changed to NCdec bias by skewing the distribution of clusters in the ground truth partition. It is important for users to be aware of this new type of biased behaviour, since it may affect the interpretations of CVI results. The objective of this article is to study the empirical and theoretical implications of GT bias. To the best of our knowledge, this is the first extensive study of such a property for external cluster validity indices.