 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason: Temporal Saliency Distillation for Interpretable Knowledge Transfer
Jan 07, 2026Knowledge distillation has proven effective for model compression by transferring knowledge from a larger network called the teacher to a smaller network called the student. Current knowledge distillation in time series is predominantly based on logit and feature aligning techniques originally developed for computer vision tasks. These methods do not explicitly account for temporal data and fall short in two key aspects. First, the mechanisms by which the transferred knowledge helps the student model learning process remain unclear due to uninterpretability of logits and features. Second, these methods transfer only limited knowledge, primarily replicating the teacher predictive accuracy. As a result, student models often produce predictive distributions that differ significantly from those of their teachers, hindering their safe substitution for teacher models. In this work, we propose transferring interpretable knowledge by extending conventional logit transfer to convey not just the right prediction but also the right reasoning of the teacher. Specifically, we induce other useful knowledge from the teacher logits termed temporal saliency which captures the importance of each input timestep to the teacher prediction. By training the student with Temporal Saliency Distillation we encourage it to make predictions based on the same input features as the teacher. Temporal Saliency Distillation requires no additional parameters or architecture specific assumptions. We demonstrate that Temporal Saliency Distillation effectively improves the performance of baseline methods while also achieving desirable properties beyond predictive accuracy. We hope our work establishes a new paradigm for interpretable knowledge distillation in time series analysis.
MemKD: Memory-Discrepancy Knowledge Distillation for Efficient Time Series Classification
Jan 07, 2026Deep learning models, particularly recurrent neural networks and their variants, such as long short-term memory, have significantly advanced time series data analysis. These models capture complex, sequential patterns in time series, enabling real-time assessments. However, their high computational complexity and large model sizes pose challenges for deployment in resource-constrained environments, such as wearable devices and edge computing platforms. Knowledge Distillation (KD) offers a solution by transferring knowledge from a large, complex model (teacher) to a smaller, more efficient model (student), thereby retaining high performance while reducing computational demands. Current KD methods, originally designed for computer vision tasks, neglect the unique temporal dependencies and memory retention characteristics of time series models. To this end, we propose a novel KD framework termed Memory-Discrepancy Knowledge Distillation (MemKD). MemKD leverages a specialized loss function to capture memory retention discrepancies between the teacher and student models across subsequences within time series data, ensuring that the student model effectively mimics the teacher model's behaviour. This approach facilitates the development of compact, high-performing recurrent neural networks suitable for real-time, time series analysis tasks. Our extensive experiments demonstrate that MemKD significantly outperforms state-of-the-art KD methods. It reduces parameter size and memory usage by approximately 500 times while maintaining comparable performance to the teacher model.
NeuroSleepNet: A Multi-Head Self-Attention Based Automatic Sleep Scoring Scheme with Spatial and Multi-Scale Temporal Representation Learning
Dec 31, 2024



Objective: Automatic sleep scoring is crucial for diagnosing sleep disorders. Existing frameworks based on Polysomnography often rely on long sequences of input signals to predict sleep stages, which can introduce complexity. Moreover, there is limited exploration of simplifying representation learning in sleep scoring methods. Methods: In this study, we propose NeuroSleepNet, an automatic sleep scoring method designed to classify the current sleep stage using only the microevents in the current input signal, without the need for past inputs. Our model employs supervised spatial and multi-scale temporal context learning and incorporates a transformer encoder to enhance representation learning. Additionally, NeuroSleepNet is optimized for balanced performance across five sleep stages by introducing a logarithmic scale-based weighting technique as a loss function. Results: NeuroSleepNet achieved similar and comparable performance with current state-of-the-art results. The best accuracy, macro-F1 score, and Cohen's kappa were 86.1 percent, 80.8 percent, and 0.805 for Sleep-EDF expanded; 82.0 percent, 76.3 percent, and 0.753 for MESA; 80.5 percent, 76.8 percent, and 0.738 for Physio2018; and 86.7 percent, 80.9 percent, and 0.804 for the SHHS database. Conclusion: NeuroSleepNet demonstrates that even with a focus on computational efficiency and a purely supervised learning approach, it is possible to achieve performance that is comparable to state-of-the-art methods. Significance: Our study simplifies automatic sleep scoring by focusing solely on microevents in the current input signal while maintaining remarkable performance. This offers a streamlined alternative for sleep diagnosis applications.
MOMA:Distill from Self-Supervised Teachers
Feb 04, 2023Contrastive Learning and Masked Image Modelling have demonstrated exceptional performance on self-supervised representation learning, where Momentum Contrast (i.e., MoCo) and Masked AutoEncoder (i.e., MAE) are the state-of-the-art, respectively. In this work, we propose MOMA to distill from pre-trained MoCo and MAE in a self-supervised manner to collaborate the knowledge from both paradigms. We introduce three different mechanisms of knowledge transfer in the propsoed MOMA framework. : (1) Distill pre-trained MoCo to MAE. (2) Distill pre-trained MAE to MoCo (3) Distill pre-trained MoCo and MAE to a random initialized student. During the distillation, the teacher and the student are fed with original inputs and masked inputs, respectively. The learning is enabled by aligning the normalized representations from the teacher and the projected representations from the student. This simple design leads to efficient computation with extremely high mask ratio and dramatically reduced training epochs, and does not require extra considerations on the distillation target. The experiments show MOMA delivers compact student models with comparable performance to existing state-of-the-art methods, combining the power of both self-supervised learning paradigms. It presents competitive results against different benchmarks in computer vision. We hope our method provides an insight on transferring and adapting the knowledge from large-scale pre-trained models in a computationally efficient way.
Masked Contrastive Representation Learning
Nov 11, 2022



Masked image modelling (e.g., Masked AutoEncoder) and contrastive learning (e.g., Momentum Contrast) have shown impressive performance on unsupervised visual representation learning. This work presents Masked Contrastive Representation Learning (MACRL) for self-supervised visual pre-training. In particular, MACRL leverages the effectiveness of both masked image modelling and contrastive learning. We adopt an asymmetric setting for the siamese network (i.e., encoder-decoder structure in both branches), where one branch with higher mask ratio and stronger data augmentation, while the other adopts weaker data corruptions. We optimize a contrastive learning objective based on the learned features from the encoder in both branches. Furthermore, we minimize the $L_1$ reconstruction loss according to the decoders' outputs. In our experiments, MACRL presents superior results on various vision benchmarks, including CIFAR-10, CIFAR-100, Tiny-ImageNet, and two other ImageNet subsets. Our framework provides unified insights on self-supervised visual pre-training and future research.
A Distributed Deep Reinforcement Learning Technique for Application Placement in Edge and Fog Computing Environments
Oct 24, 2021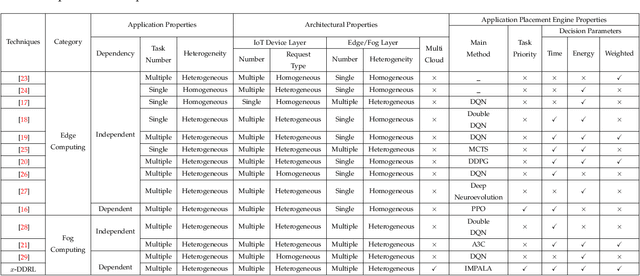
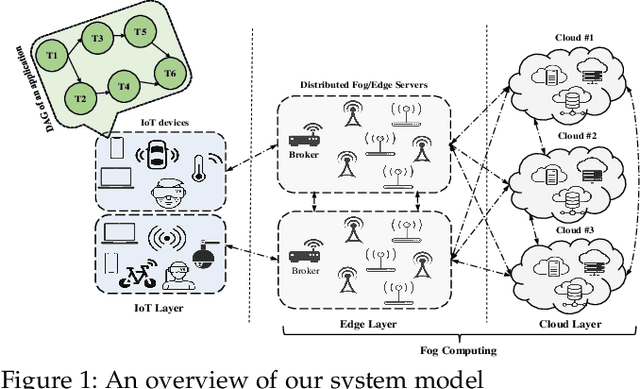
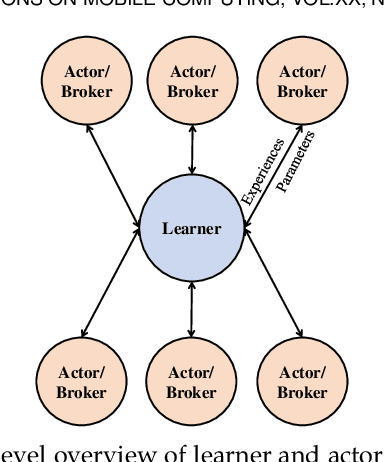
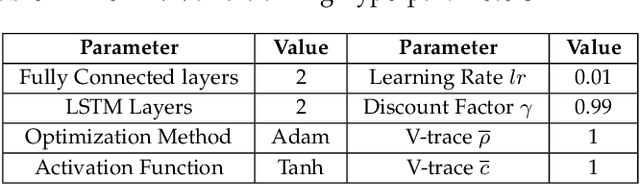
Fog/Edge computing is a novel computing paradigm supporting resource-constrained Internet of Things (IoT) devices by the placement of their tasks on the edge and/or cloud servers. Recently, several Deep Reinforcement Learning (DRL)-based placement techniques have been proposed in fog/edge computing environments, which are only suitable for centralized setups. The training of well-performed DRL agents requires manifold training data while obtaining training data is costly. Hence, these centralized DRL-based techniques lack generalizability and quick adaptability, thus failing to efficiently tackle application placement problems. Moreover, many IoT applications are modeled as Directed Acyclic Graphs (DAGs) with diverse topologies. Satisfying dependencies of DAG-based IoT applications incur additional constraints and increase the complexity of placement problems. To overcome these challenges, we propose an actor-critic-based distributed application placement technique, working based on the IMPortance weighted Actor-Learner Architectures (IMPALA). IMPALA is known for efficient distributed experience trajectory generation that significantly reduces the exploration costs of agents. Besides, it uses an adaptive off-policy correction method for faster convergence to optimal solutions. Our technique uses recurrent layers to capture temporal behaviors of input data and a replay buffer to improve the sample efficiency. The performance results, obtained from simulation and testbed experiments, demonstrate that our technique significantly improves the execution cost of IoT applications up to 30\% compared to its counterparts.
A Scalable Framework for Trajectory Prediction
Jun 20, 2018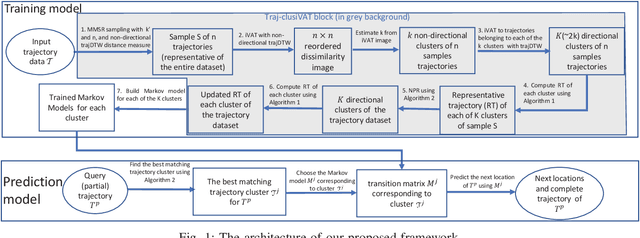

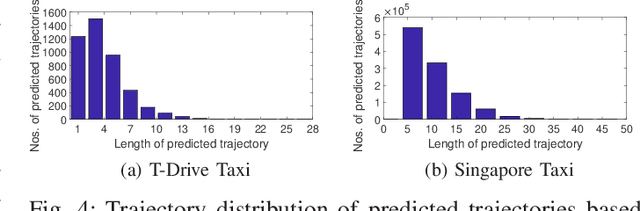
Trajectory prediction (TP) is of great importance for a wide range of location-based applications in intelligent transport systems such as location-based advertising, route planning, traffic management, and early warning systems. In the last few years, the widespread use of GPS navigation systems and wireless communication technology enabled vehicles has resulted in huge volumes of trajectory data. The task of utilizing this data employing spatio-temporal techniques for trajectory prediction in an efficient and accurate manner is an ongoing research problem. Existing TP approaches are limited to short-term predictions. Moreover, they cannot handle a large volume of trajectory data for long-term prediction. To address these limitations, we propose a scalable clustering and Markov chain based hybrid framework, called Traj-clusiVAT-based TP, for both short-term and long-term trajectory prediction, which can handle a large number of overlapping trajectories in a dense road network. In addition, Traj-clusiVAT can also determine the number of clusters, which represent different movement behaviours in input trajectory data. In our experiments, we compare our proposed approach with a mixed Markov model (MMM)-based scheme, and a trajectory clustering, NETSCAN-based TP method for both short- and long-term trajectory predictions. We performed our experiments on two real, vehicle trajectory datasets, including a large-scale trajectory dataset consisting of 3.28 million trajectories obtained from 15,061 taxis in Singapore over a period of one month. Experimental results on two real trajectory datasets show that our proposed approach outperforms the existing approaches in terms of both short- and long-term prediction performances, based on prediction accuracy and distance error (in km).
Fuzzy c-Shape: A new algorithm for clustering finite time series waveforms
Aug 03, 2016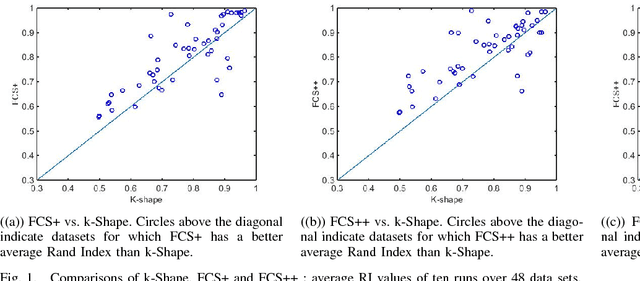
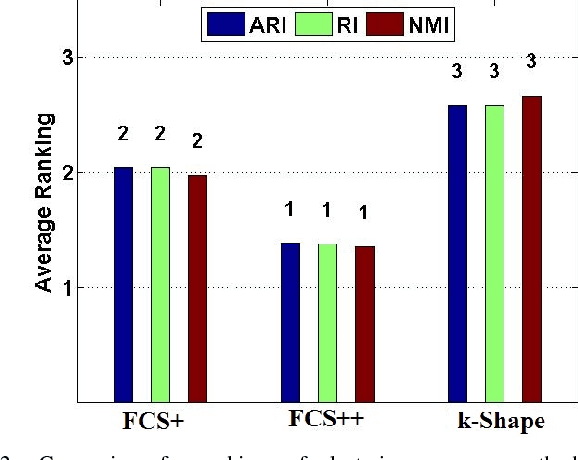
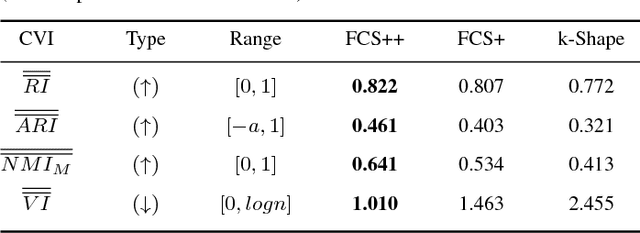
The existence of large volumes of time series data in many applications has motivated data miners to investigate specialized methods for mining time series data. Clustering is a popular data mining method due to its powerful exploratory nature and its usefulness as a preprocessing step for other data mining techniques. This article develops two novel clustering algorithms for time series data that are extensions of a crisp c-shapes algorithm. The two new algorithms are heuristic derivatives of fuzzy c-means (FCM). Fuzzy c-Shapes plus (FCS+) replaces the inner product norm in the FCM model with a shape-based distance function. Fuzzy c-Shapes double plus (FCS++) uses the shape-based distance, and also replaces the FCM cluster centers with shape-extracted prototypes. Numerical experiments on 48 real time series data sets show that the two new algorithms outperform state-of-the-art shape-based clustering algorithms in terms of accuracy and efficiency. Four external cluster validity indices (the Rand index, Adjusted Rand Index, Variation of Information, and Normalized Mutual Information) are used to match candidate partitions generated by each of the studied algorithms. All four indices agree that for these finite waveform data sets, FCS++ gives a small improvement over FCS+, and in turn, FCS+ is better than the original crisp c-shapes method. Finally, we apply two tests of statistical significance to the three algorithms. The Wilcoxon and Friedman statistics both rank the three algorithms in exactly the same way as the four cluster validity indices.