 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOMA:Distill from Self-Supervised Teachers
Feb 04, 2023Contrastive Learning and Masked Image Modelling have demonstrated exceptional performance on self-supervised representation learning, where Momentum Contrast (i.e., MoCo) and Masked AutoEncoder (i.e., MAE) are the state-of-the-art, respectively. In this work, we propose MOMA to distill from pre-trained MoCo and MAE in a self-supervised manner to collaborate the knowledge from both paradigms. We introduce three different mechanisms of knowledge transfer in the propsoed MOMA framework. : (1) Distill pre-trained MoCo to MAE. (2) Distill pre-trained MAE to MoCo (3) Distill pre-trained MoCo and MAE to a random initialized student. During the distillation, the teacher and the student are fed with original inputs and masked inputs, respectively. The learning is enabled by aligning the normalized representations from the teacher and the projected representations from the student. This simple design leads to efficient computation with extremely high mask ratio and dramatically reduced training epochs, and does not require extra considerations on the distillation target. The experiments show MOMA delivers compact student models with comparable performance to existing state-of-the-art methods, combining the power of both self-supervised learning paradigms. It presents competitive results against different benchmarks in computer vision. We hope our method provides an insight on transferring and adapting the knowledge from large-scale pre-trained models in a computationally efficient way.
Masked Contrastive Representation Learning
Nov 11, 2022



Masked image modelling (e.g., Masked AutoEncoder) and contrastive learning (e.g., Momentum Contrast) have shown impressive performance on unsupervised visual representation learning. This work presents Masked Contrastive Representation Learning (MACRL) for self-supervised visual pre-training. In particular, MACRL leverages the effectiveness of both masked image modelling and contrastive learning. We adopt an asymmetric setting for the siamese network (i.e., encoder-decoder structure in both branches), where one branch with higher mask ratio and stronger data augmentation, while the other adopts weaker data corruptions. We optimize a contrastive learning objective based on the learned features from the encoder in both branches. Furthermore, we minimize the $L_1$ reconstruction loss according to the decoders' outputs. In our experiments, MACRL presents superior results on various vision benchmarks, including CIFAR-10, CIFAR-100, Tiny-ImageNet, and two other ImageNet subsets. Our framework provides unified insights on self-supervised visual pre-training and future research.
Conditional Variational Autoencoder with Balanced Pre-training for Generative Adversarial Networks
Jan 13, 2022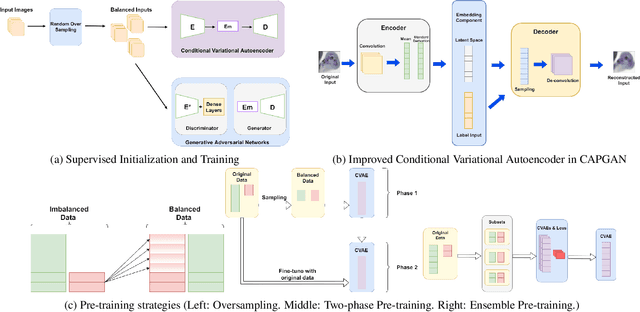
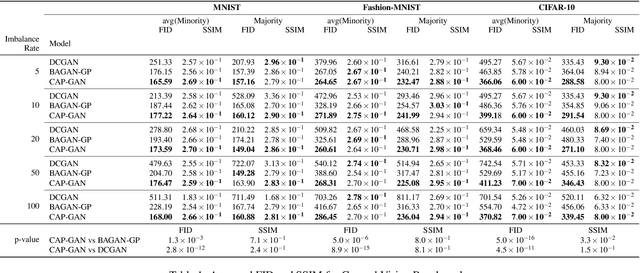
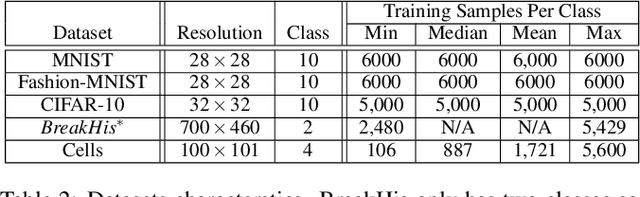
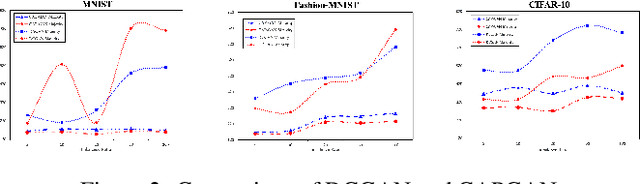
Class imbalance occurs in many real-world applications, including image classification, where the number of images in each class differs significantly. With imbalanced data, the generative adversarial networks (GANs) leans to majority class samples. The two recent methods, Balancing GAN (BAGAN) and improved BAGAN (BAGAN-GP), are proposed as an augmentation tool to handle this problem and restore the balance to the data. The former pre-trains the autoencoder weights in an unsupervised manner. However, it is unstable when the images from different categories have similar features. The latter is improved based on BAGAN by facilitating supervised autoencoder training, but the pre-training is biased towards the majority classes. In this work, we propose a novel Conditional Variational Autoencoder with Balanced Pre-training for Generative Adversarial Networks (CAPGAN) as an augmentation tool to generate realistic synthetic images. In particular, we utilize a conditional convolutional variational autoencoder with supervised and balanced pre-training for the GAN initialization and training with gradient penalty. Our proposed method presents a superior performance of other state-of-the-art methods on the highly imbalanced version of MNIST, Fashion-MNIST, CIFAR-10, and two medical imaging datasets. Our method can synthesize high-quality minority samples in terms of Fr\'echet inception distance, structural similarity index measure and perceptual quality.