 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBMD-45: A Large-Scale CCTV Vehicle Detection Dataset for Urban Traffic in Developing Cities
Apr 27, 2026Robust vehicle detection from fixed CCTV cameras is critical for Intelligent Transportation Systems. Yet existing benchmarks predominantly feature relatively homogeneous, highly organized traffic patterns captured from ego-centric driving perspectives or controlled aerial views. This regional and sensor view bias creates a significant gap. Models trained on datasets such as UA-DETRAC and COCO struggle to generalize to the dense, heterogeneous, disorganized traffic conditions observed in rapidly developing urban centers in emerging economies. To address this limitation, we introduce BMD-45, a large-scale dataset comprising 480K bounding boxes annotated over 45K images captured from over 3.6K operational Safe City CCTV cameras. BMD-45 contains 14 fine-grained vehicle categories, including region-specific modes such as auto-rickshaws and tempo travellers, which are not present in existing benchmarks. The dataset captures real-world deployment challenges, including extreme viewpoint variation, occlusion, and vehicle density . We establish comprehensive baselines using state-of-the-art detectors and reveal a striking domain gap: models fine-tuned on UA-DETRAC achieve only 33.6% mAP@0.50:0.95, compared to 83.8% when trained in-domain on BMD-45, representing a 2.5x improvement that persists even when accounting for novel vehicle classes. This performance gap underscores the critical need for geographically diverse traffic benchmarks and establishes BMD-45 as a baseline for developing robust perception systems in underrepresented urban environments worldwide. The dataset is available at: https://huggingface.co/datasets/iisc-aim/BMD-45.
Physics-informed neural network for fatigue life prediction of irradiated austenitic and ferritic/martensitic steels
Aug 24, 2025This study proposes a Physics-Informed Neural Network (PINN) framework to predict the low-cycle fatigue (LCF) life of irradiated austenitic and ferritic/martensitic (F/M) steels used in nuclear reactors. These materials experience cyclic loading and irradiation at elevated temperatures, causing complex degradation that traditional empirical models fail to capture accurately. The developed PINN model incorporates physical fatigue life constraints into its loss function, improving prediction accuracy and generalizability. Trained on 495 data points, including both irradiated and unirradiated conditions, the model outperforms traditional machine learning models like Random Forest, Gradient Boosting, eXtreme Gradient Boosting, and the conventional Neural Network. SHapley Additive exPlanations analysis identifies strain amplitude, irradiation dose, and testing temperature as dominant features, each inversely correlated with fatigue life, consistent with physical understanding. PINN captures saturation behaviour in fatigue life at higher strain amplitudes in F/M steels. Overall, the PINN framework offers a reliable and interpretable approach for predicting fatigue life in irradiated alloys, enabling informed alloy selection.
STEAM: Squeeze and Transform Enhanced Attention Module
Dec 12, 2024
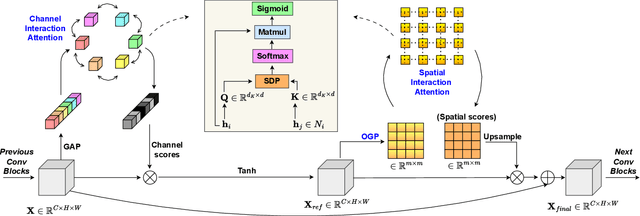
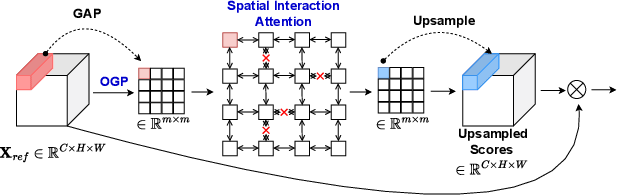
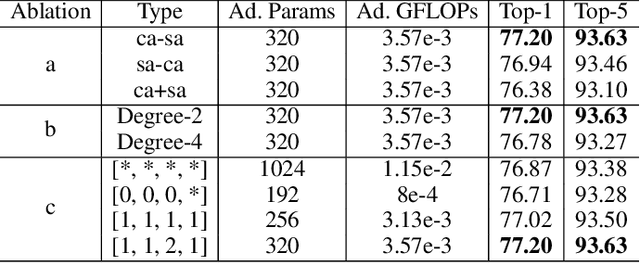
Channel and spatial attention mechanisms introduced by earlier works enhance the representation abilities of deep convolutional neural networks (CNNs) but often lead to increased parameter and computation costs. While recent approaches focus solely on efficient feature context modeling for channel attention, we aim to model both channel and spatial attention comprehensively with minimal parameters and reduced computation. Leveraging the principles of relational modeling in graphs, we introduce a constant-parameter module, STEAM: Squeeze and Transform Enhanced Attention Module, which integrates channel and spatial attention to enhance the representation power of CNNs. To our knowledge, we are the first to propose a graph-based approach for modeling both channel and spatial attention, utilizing concepts from multi-head graph transformers. Additionally, we introduce Output Guided Pooling (OGP), which efficiently captures spatial context to further enhance spatial attention. We extensively evaluate STEAM for large-scale image classification, object detection and instance segmentation on standard benchmark datasets. STEAM achieves a 2% increase in accuracy over the standard ResNet-50 model with only a meager increase in GFLOPs. Furthermore, STEAM outperforms leading modules ECA and GCT in terms of accuracy while achieving a three-fold reduction in GFLOPs.
Learning Low-Rank Latent Spaces with Simple Deterministic Autoencoder: Theoretical and Empirical Insights
Oct 24, 2023The autoencoder is an unsupervised learning paradigm that aims to create a compact latent representation of data by minimizing the reconstruction loss. However, it tends to overlook the fact that most data (images) are embedded in a lower-dimensional space, which is crucial for effective data representation. To address this limitation, we propose a novel approach called Low-Rank Autoencoder (LoRAE). In LoRAE, we incorporated a low-rank regularizer to adaptively reconstruct a low-dimensional latent space while preserving the basic objective of an autoencoder. This helps embed the data in a lower-dimensional space while preserving important information. It is a simple autoencoder extension that learns low-rank latent space. Theoretically, we establish a tighter error bound for our model. Empirically, our model's superiority shines through various tasks such as image generation and downstream classification. Both theoretical and practical outcomes highlight the importance of acquiring low-dimensional embeddings.
Convergence of ADAM with Constant Step Size in Non-Convex Settings: A Simple Proof
Sep 24, 2023In neural network training, RMSProp and ADAM remain widely favoured optimization algorithms. One of the keys to their performance lies in selecting the correct step size, which can significantly influence their effectiveness. It is worth noting that these algorithms performance can vary considerably, depending on the chosen step sizes. Additionally, questions about their theoretical convergence properties continue to be a subject of interest. In this paper, we theoretically analyze a constant stepsize version of ADAM in the non-convex setting. We show sufficient conditions for the stepsize to achieve almost sure asymptotic convergence of the gradients to zero with minimal assumptions. We also provide runtime bounds for deterministic ADAM to reach approximate criticality when working with smooth, non-convex functions.
A Self-Supervised Approach for Cluster Assessment of High-Dimensional Data
May 29, 2023



Estimating the number of clusters and underlying cluster structure in a dataset is a crucial task. Real-world data are often unlabeled, complex and high-dimensional, which makes it difficult for traditional clustering algorithms to perform well. In recent years, a matrix reordering based algorithm, called "visual assessment of tendency" (VAT), and its variants have attracted many researchers from various domains to estimate the number of clusters and inherent cluster structure present in the data. However, these algorithms fail when applied to high-dimensional data due to the curse of dimensionality, as they rely heavily on the notions of closeness and farness between data points. To address this issue, we propose a deep-learning based framework for cluster structure assessment in complex, image datasets. First, our framework generates representative embeddings for complex data using a self-supervised deep neural network, and then, these low-dimensional embeddings are fed to VAT/iVAT algorithms to estimate the underlying cluster structure. In this process, we ensured not to use any prior knowledge for the number of clusters (i.e k). We present our results on four real-life image datasets, and our findings indicate that our framework outperforms state-of-the-art VAT/iVAT algorithms in terms of clustering accuracy and normalized mutual information (NMI).
ConiVAT: Cluster Tendency Assessment and Clustering with Partial Background Knowledge
Sep 28, 2020
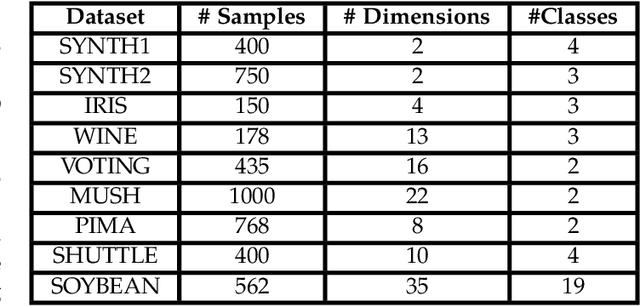

The VAT method is a visual technique for determining the potential cluster structure and the possible number of clusters in numerical data. Its improved version, iVAT, uses a path-based distance transform to improve the effectiveness of VAT for "tough" cases. Both VAT and iVAT have also been used in conjunction with a single-linkage(SL) hierarchical clustering algorithm. However, they are sensitive to noise and bridge points between clusters in the dataset, and consequently, the corresponding VAT/iVAT images are often in-conclusive for such cases. In this paper, we propose a constraint-based version of iVAT, which we call ConiVAT, that makes use of background knowledge in the form of constraints, to improve VAT/iVAT for challenging and complex datasets. ConiVAT uses the input constraints to learn the underlying similarity metric and builds a minimum transitive dissimilarity matrix, before applying VAT to it. We demonstrate ConiVAT approach to visual assessment and single linkage clustering on nine datasets to show that, it improves the quality of iVAT images for complex datasets, and it also overcomes the limitation of SL clustering with VAT/iVAT due to "noisy" bridges between clusters. Extensive experiment results on nine datasets suggest that ConiVAT outperforms the other three semi-supervised clustering algorithms in terms of improved clustering accuracy.
Understanding the Dynamics of Drivers' Locations for Passengers Pickup Performance: A Case Study
Sep 09, 2020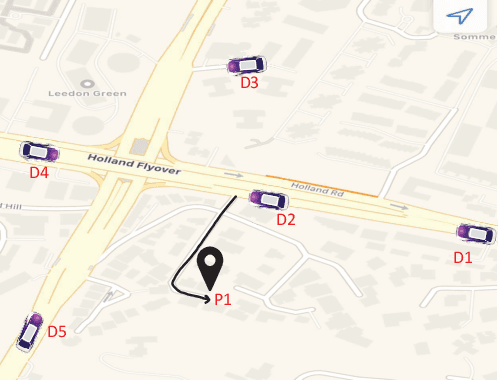
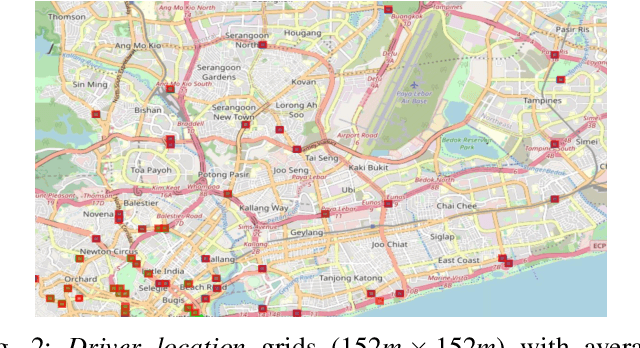


With the emergence of e-hailing taxi services, a growing number of scholars have attempted to analyze the taxi trips data to gain insights from drivers' and passengers' flow patterns and understand different dynamics of urban public transportation. Existing studies are limited to passengers' location analysis e.g., pick-up and drop-off points, in the context of maximizing the profits or better managing the resources for service providers. Moreover, taxi drivers' locations at the time of pick-up requests and their pickup performance in the spatial-temporal domain have not been explored. In this paper, we analyze drivers' and passengers' locations at the time of booking request in the context of drivers' pick-up performances. To facilitate our analysis, we implement a modified and extended version of a co-clustering technique, called sco-iVAT, to obtain useful clusters and co-clusters from big relational data, derived from booking records of Grab ride-hailing service in Singapore. We also explored the possibility of predicting timely pickup for a given booking request, without using entire trajectories data. Finally, we devised two scoring mechanisms to compute pickup performance score for all driver candidates for a booking request. These scores could be integrated into a booking assignment model to prioritize top-performing drivers for passenger pickups.
A Scalable Framework for Trajectory Prediction
Jun 20, 2018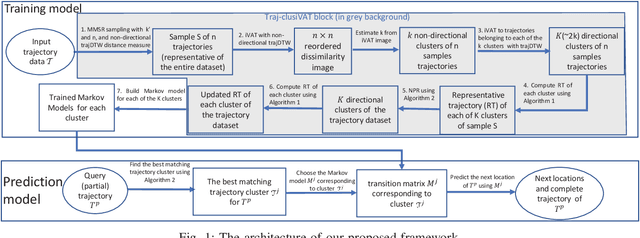

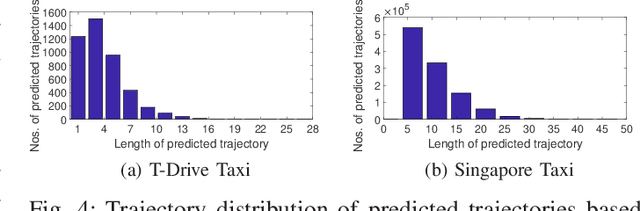
Trajectory prediction (TP) is of great importance for a wide range of location-based applications in intelligent transport systems such as location-based advertising, route planning, traffic management, and early warning systems. In the last few years, the widespread use of GPS navigation systems and wireless communication technology enabled vehicles has resulted in huge volumes of trajectory data. The task of utilizing this data employing spatio-temporal techniques for trajectory prediction in an efficient and accurate manner is an ongoing research problem. Existing TP approaches are limited to short-term predictions. Moreover, they cannot handle a large volume of trajectory data for long-term prediction. To address these limitations, we propose a scalable clustering and Markov chain based hybrid framework, called Traj-clusiVAT-based TP, for both short-term and long-term trajectory prediction, which can handle a large number of overlapping trajectories in a dense road network. In addition, Traj-clusiVAT can also determine the number of clusters, which represent different movement behaviours in input trajectory data. In our experiments, we compare our proposed approach with a mixed Markov model (MMM)-based scheme, and a trajectory clustering, NETSCAN-based TP method for both short- and long-term trajectory predictions. We performed our experiments on two real, vehicle trajectory datasets, including a large-scale trajectory dataset consisting of 3.28 million trajectories obtained from 15,061 taxis in Singapore over a period of one month. Experimental results on two real trajectory datasets show that our proposed approach outperforms the existing approaches in terms of both short- and long-term prediction performances, based on prediction accuracy and distance error (in km).