 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Turn Evaluation of Deep Research Agents Under Process-Level Feedback
Jun 08, 2026Existing benchmarks for deep research agents (DRAs) assess only single-shot outputs, ignoring a key question: can DRAs improve their reports when guided by feedback? To investigate this, we conduct a multi-turn evaluation of DRAs under two feedback settings: self-reflection, in which the agent revises its report without any external diagnostic signal, and process-level feedback, in which the agent receives guidance targeting gaps in its research strategy. To enable process-level feedback, we design Research Gap Inference (RGI), a method that analyzes patterns of satisfied and unsatisfied rubric criteria to infer research-process gaps. Our analysis reveals three key findings: (i) under self-reflection, agents incorporate and regress on rubric criteria at nearly equal rates, yielding negligible net improvement; (ii) a single round of process-level feedback yields substantial gains, raising the normalized score by approximately $8$-$15$ points and yielding a roughly $35$-$40\%$ incorporation rate; (iii) these gains do not compound over subsequent turns, as agents regress on up to $24\%$ of previously satisfied criteria when rewriting the full report to address remaining gaps. Even with targeted guidance, reliable multi-turn improvement remains out of reach for the DRA architectures we evaluate. Our code and results are publicly available at https://github.com/sabharwalrishabh/Multi-Turn-Evaluation-of-DRAs.
STEAM: Squeeze and Transform Enhanced Attention Module
Dec 12, 2024
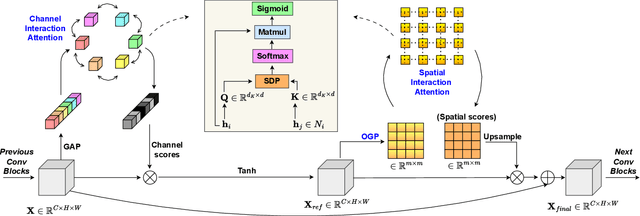
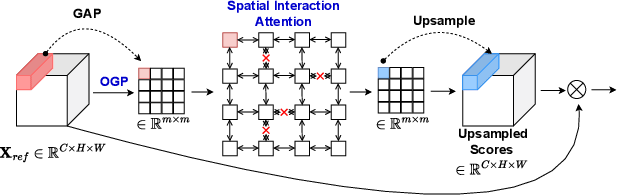
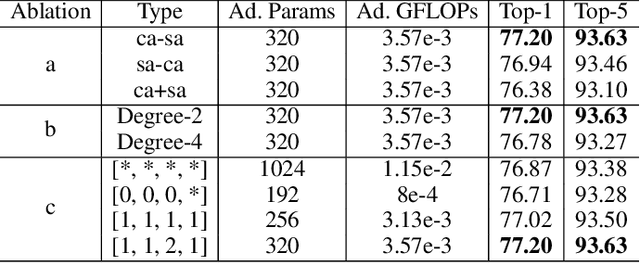
Channel and spatial attention mechanisms introduced by earlier works enhance the representation abilities of deep convolutional neural networks (CNNs) but often lead to increased parameter and computation costs. While recent approaches focus solely on efficient feature context modeling for channel attention, we aim to model both channel and spatial attention comprehensively with minimal parameters and reduced computation. Leveraging the principles of relational modeling in graphs, we introduce a constant-parameter module, STEAM: Squeeze and Transform Enhanced Attention Module, which integrates channel and spatial attention to enhance the representation power of CNNs. To our knowledge, we are the first to propose a graph-based approach for modeling both channel and spatial attention, utilizing concepts from multi-head graph transformers. Additionally, we introduce Output Guided Pooling (OGP), which efficiently captures spatial context to further enhance spatial attention. We extensively evaluate STEAM for large-scale image classification, object detection and instance segmentation on standard benchmark datasets. STEAM achieves a 2% increase in accuracy over the standard ResNet-50 model with only a meager increase in GFLOPs. Furthermore, STEAM outperforms leading modules ECA and GCT in terms of accuracy while achieving a three-fold reduction in GFLOPs.