 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEAM: Squeeze and Transform Enhanced Attention Module
Paper and Code
Dec 12, 2024
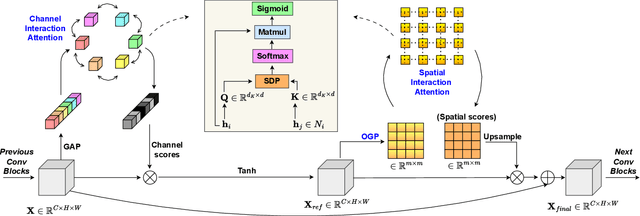
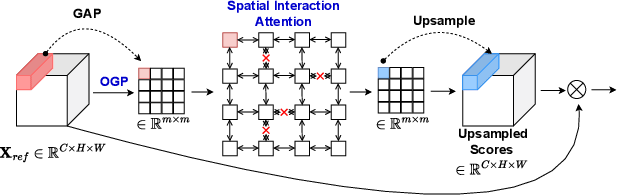
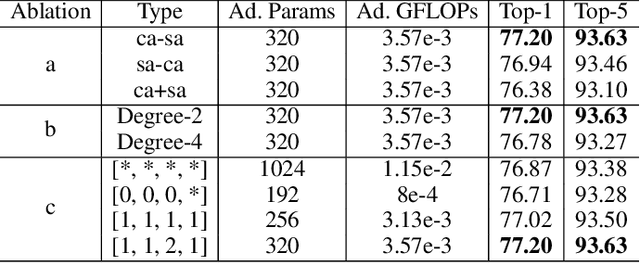
Channel and spatial attention mechanisms introduced by earlier works enhance the representation abilities of deep convolutional neural networks (CNNs) but often lead to increased parameter and computation costs. While recent approaches focus solely on efficient feature context modeling for channel attention, we aim to model both channel and spatial attention comprehensively with minimal parameters and reduced computation. Leveraging the principles of relational modeling in graphs, we introduce a constant-parameter module, STEAM: Squeeze and Transform Enhanced Attention Module, which integrates channel and spatial attention to enhance the representation power of CNNs. To our knowledge, we are the first to propose a graph-based approach for modeling both channel and spatial attention, utilizing concepts from multi-head graph transformers. Additionally, we introduce Output Guided Pooling (OGP), which efficiently captures spatial context to further enhance spatial attention. We extensively evaluate STEAM for large-scale image classification, object detection and instance segmentation on standard benchmark datasets. STEAM achieves a 2% increase in accuracy over the standard ResNet-50 model with only a meager increase in GFLOPs. Furthermore, STEAM outperforms leading modules ECA and GCT in terms of accuracy while achieving a three-fold reduction in GFLOPs.