 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Convergence of Plug-and-Play Algorithms with Kernel Denoisers
May 21, 2025The use of denoisers for image reconstruction has shown significant potential, especially for the Plug-and-Play (PnP) framework. In PnP, a powerful denoiser is used as an implicit regularizer in proximal algorithms such as ISTA and ADMM. The focus of this work is on the convergence of PnP iterates for linear inverse problems using kernel denoisers. It was shown in prior work that the update operator in standard PnP is contractive for symmetric kernel denoisers under appropriate conditions on the denoiser and the linear forward operator. Consequently, we could establish global linear convergence of the iterates using the contraction mapping theorem. In this work, we develop a unified framework to establish global linear convergence for symmetric and nonsymmetric kernel denoisers. Additionally, we derive quantitative bounds on the contraction factor (convergence rate) for inpainting, deblurring, and superresolution. We present numerical results to validate our theoretical findings.
Learning Low-Rank Latent Spaces with Simple Deterministic Autoencoder: Theoretical and Empirical Insights
Oct 24, 2023The autoencoder is an unsupervised learning paradigm that aims to create a compact latent representation of data by minimizing the reconstruction loss. However, it tends to overlook the fact that most data (images) are embedded in a lower-dimensional space, which is crucial for effective data representation. To address this limitation, we propose a novel approach called Low-Rank Autoencoder (LoRAE). In LoRAE, we incorporated a low-rank regularizer to adaptively reconstruct a low-dimensional latent space while preserving the basic objective of an autoencoder. This helps embed the data in a lower-dimensional space while preserving important information. It is a simple autoencoder extension that learns low-rank latent space. Theoretically, we establish a tighter error bound for our model. Empirically, our model's superiority shines through various tasks such as image generation and downstream classification. Both theoretical and practical outcomes highlight the importance of acquiring low-dimensional embeddings.
On the Contractivity of Plug-and-Play Operators
Sep 28, 2023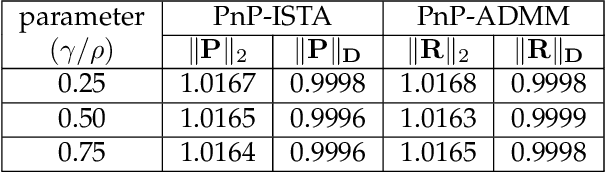
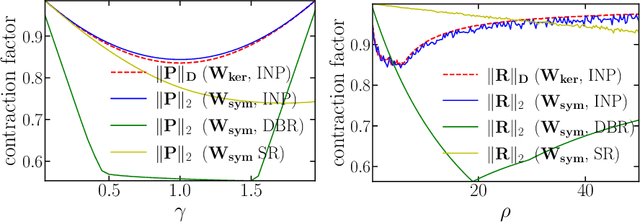
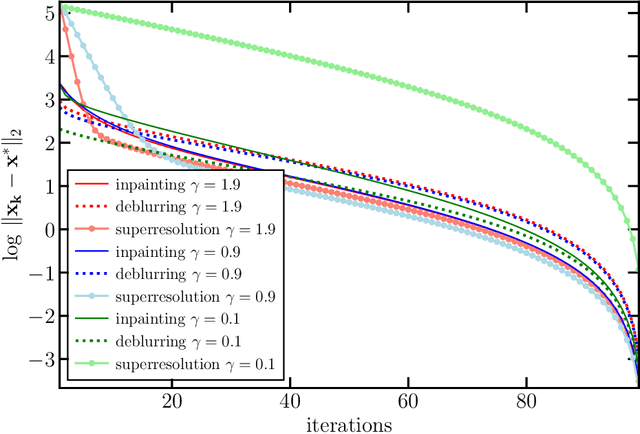

In plug-and-play (PnP) regularization, the proximal operator in algorithms such as ISTA and ADMM is replaced by a powerful denoiser. This formal substitution works surprisingly well in practice. In fact, PnP has been shown to give state-of-the-art results for various imaging applications. The empirical success of PnP has motivated researchers to understand its theoretical underpinnings and, in particular, its convergence. It was shown in prior work that for kernel denoisers such as the nonlocal means, PnP-ISTA provably converges under some strong assumptions on the forward model. The present work is motivated by the following questions: Can we relax the assumptions on the forward model? Can the convergence analysis be extended to PnP-ADMM? Can we estimate the convergence rate? In this letter, we resolve these questions using the contraction mapping theorem: (i) for symmetric denoisers, we show that (under mild conditions) PnP-ISTA and PnP-ADMM exhibit linear convergence; and (ii) for kernel denoisers, we show that PnP-ISTA and PnP-ADMM converge linearly for image inpainting. We validate our theoretical findings using reconstruction experiments.
Convergence of ADAM with Constant Step Size in Non-Convex Settings: A Simple Proof
Sep 24, 2023In neural network training, RMSProp and ADAM remain widely favoured optimization algorithms. One of the keys to their performance lies in selecting the correct step size, which can significantly influence their effectiveness. It is worth noting that these algorithms performance can vary considerably, depending on the chosen step sizes. Additionally, questions about their theoretical convergence properties continue to be a subject of interest. In this paper, we theoretically analyze a constant stepsize version of ADAM in the non-convex setting. We show sufficient conditions for the stepsize to achieve almost sure asymptotic convergence of the gradients to zero with minimal assumptions. We also provide runtime bounds for deterministic ADAM to reach approximate criticality when working with smooth, non-convex functions.