 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect Anything via Next Point Prediction
Oct 14, 2025Object detection has long been dominated by traditional coordinate regression-based models, such as YOLO, DETR, and Grounding DINO. Although recent efforts have attempted to leverage MLLMs to tackle this task, they face challenges like low recall rate, duplicate predictions, coordinate misalignment, etc. In this work, we bridge this gap and propose Rex-Omni, a 3B-scale MLLM that achieves state-of-the-art object perception performance. On benchmarks like COCO and LVIS, Rex-Omni attains performance comparable to or exceeding regression-based models (e.g., DINO, Grounding DINO) in a zero-shot setting. This is enabled by three key designs: 1) Task Formulation: we use special tokens to represent quantized coordinates from 0 to 999, reducing the model's learning difficulty and improving token efficiency for coordinate prediction; 2) Data Engines: we construct multiple data engines to generate high-quality grounding, referring, and pointing data, providing semantically rich supervision for training; \3) Training Pipelines: we employ a two-stage training process, combining supervised fine-tuning on 22 million data with GRPO-based reinforcement post-training. This RL post-training leverages geometry-aware rewards to effectively bridge the discrete-to-continuous coordinate prediction gap, improve box accuracy, and mitigate undesirable behaviors like duplicate predictions that stem from the teacher-guided nature of the initial SFT stage. Beyond conventional detection, Rex-Omni's inherent language understanding enables versatile capabilities such as object referring, pointing, visual prompting, GUI grounding, spatial referring, OCR and key-pointing, all systematically evaluated on dedicated benchmarks. We believe that Rex-Omni paves the way for more versatile and language-aware visual perception systems.
Referring to Any Person
Mar 11, 2025
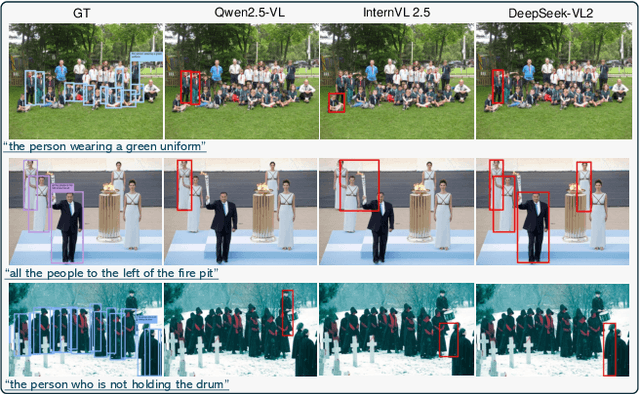
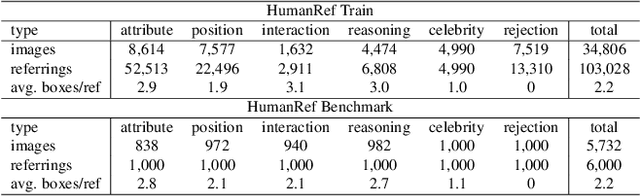
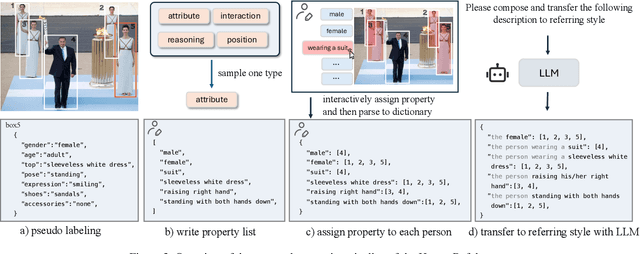
Humans are undoubtedly the most important participants in computer vision, and the ability to detect any individual given a natural language description, a task we define as referring to any person, holds substantial practical value. However, we find that existing models generally fail to achieve real-world usability, and current benchmarks are limited by their focus on one-to-one referring, that hinder progress in this area. In this work, we revisit this task from three critical perspectives: task definition, dataset design, and model architecture. We first identify five aspects of referable entities and three distinctive characteristics of this task. Next, we introduce HumanRef, a novel dataset designed to tackle these challenges and better reflect real-world applications. From a model design perspective, we integrate a multimodal large language model with an object detection framework, constructing a robust referring model named RexSeek. Experimental results reveal that state-of-the-art models, which perform well on commonly used benchmarks like RefCOCO/+/g, struggle with HumanRef due to their inability to detect multiple individuals. In contrast, RexSeek not only excels in human referring but also generalizes effectively to common object referring, making it broadly applicable across various perception tasks. Code is available at https://github.com/IDEA-Research/RexSeek
ChatRex: Taming Multimodal LLM for Joint Perception and Understanding
Dec 02, 2024



Perception and understanding are two pillars of computer vision. While multimodal large language models (MLLM) have demonstrated remarkable visual understanding capabilities, they arguably lack accurate perception abilities, e.g. the stage-of-the-art model Qwen2-VL only achieves a 43.9 recall rate on the COCO dataset, limiting many tasks requiring the combination of perception and understanding. In this work, we aim to bridge this perception gap from both model designing and data development perspectives. We first introduce ChatRex, an MLLM with a decoupled perception design. Instead of having the LLM directly predict box coordinates, we feed the output boxes from a universal proposal network into the LLM, allowing it to output the corresponding box indices to represent its detection results, turning the regression task into a retrieval-based task that LLM handles more proficiently. From the data perspective, we build a fully automated data engine and construct the Rexverse-2M dataset which possesses multiple granularities to support the joint training of perception and understanding. After standard two-stage training, ChatRex demonstrates strong perception capabilities while preserving multimodal understanding performance. The combination of these two capabilities simultaneously unlocks many attractive applications, demonstrating the complementary roles of both perception and understanding in MLLM. Code is available at \url{https://github.com/IDEA-Research/ChatRex}.
DINO-X: A Unified Vision Model for Open-World Object Detection and Understanding
Nov 21, 2024



In this paper, we introduce DINO-X, which is a unified object-centric vision model developed by IDEA Research with the best open-world object detection performance to date. DINO-X employs the same Transformer-based encoder-decoder architecture as Grounding DINO 1.5 to pursue an object-level representation for open-world object understanding. To make long-tailed object detection easy, DINO-X extends its input options to support text prompt, visual prompt, and customized prompt. With such flexible prompt options, we develop a universal object prompt to support prompt-free open-world detection, making it possible to detect anything in an image without requiring users to provide any prompt. To enhance the model's core grounding capability, we have constructed a large-scale dataset with over 100 million high-quality grounding samples, referred to as Grounding-100M, for advancing the model's open-vocabulary detection performance. Pre-training on such a large-scale grounding dataset leads to a foundational object-level representation, which enables DINO-X to integrate multiple perception heads to simultaneously support multiple object perception and understanding tasks, including detection, segmentation, pose estimation, object captioning, object-based QA, etc. Experimental results demonstrate the superior performance of DINO-X. Specifically, the DINO-X Pro model achieves 56.0 AP, 59.8 AP, and 52.4 AP on the COCO, LVIS-minival, and LVIS-val zero-shot object detection benchmarks, respectively. Notably, it scores 63.3 AP and 56.5 AP on the rare classes of LVIS-minival and LVIS-val benchmarks, both improving the previous SOTA performance by 5.8 AP. Such a result underscores its significantly improved capacity for recognizing long-tailed objects.
Grounding DINO 1.5: Advance the "Edge" of Open-Set Object Detection
May 16, 2024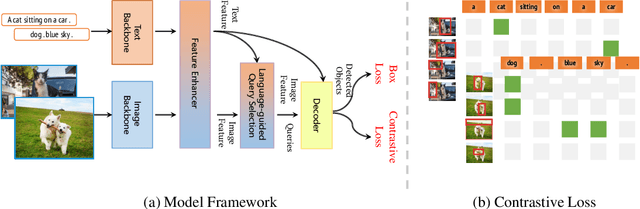
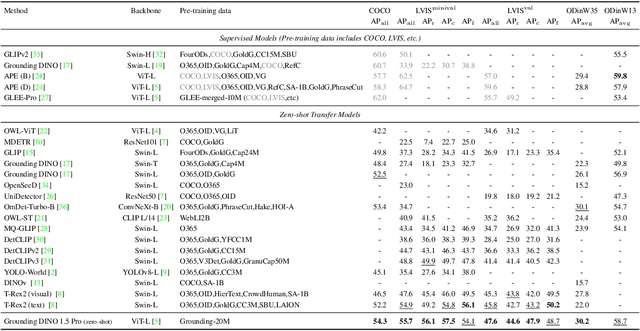
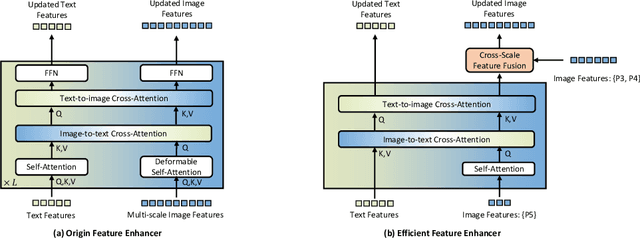

This paper introduces Grounding DINO 1.5, a suite of advanced open-set object detection models developed by IDEA Research, which aims to advance the "Edge" of open-set object detection. The suite encompasses two models: Grounding DINO 1.5 Pro, a high-performance model designed for stronger generalization capability across a wide range of scenarios, and Grounding DINO 1.5 Edge, an efficient model optimized for faster speed demanded in many applications requiring edge deployment. The Grounding DINO 1.5 Pro model advances its predecessor by scaling up the model architecture, integrating an enhanced vision backbone, and expanding the training dataset to over 20 million images with grounding annotations, thereby achieving a richer semantic understanding. The Grounding DINO 1.5 Edge model, while designed for efficiency with reduced feature scales, maintains robust detection capabilities by being trained on the same comprehensive dataset. Empirical results demonstrate the effectiveness of Grounding DINO 1.5, with the Grounding DINO 1.5 Pro model attaining a 54.3 AP on the COCO detection benchmark and a 55.7 AP on the LVIS-minival zero-shot transfer benchmark, setting new records for open-set object detection. Furthermore, the Grounding DINO 1.5 Edge model, when optimized with TensorRT, achieves a speed of 75.2 FPS while attaining a zero-shot performance of 36.2 AP on the LVIS-minival benchmark, making it more suitable for edge computing scenarios. Model examples and demos with API will be released at https://github.com/IDEA-Research/Grounding-DINO-1.5-API